1
Prześlij Audio lub Wideo
Prześlij pliki (MP3, WAV, MP4) lub wklej link z YouTube, Google Drive lub Dropbox, aby rozpocząć proces zamiany mowy na tekst.
Konwertuj mowę na tekst natychmiast za pomocą naszego narzędzia transkrypcji opartego na AI. Niezależnie od tego, czy potrzebujesz transkrypcji spotkań, wykładów czy filmów, Transkriptor zapewnia szybką i bardzo dokładną konwersję dźwięku na tekst w ponad 100 językach.
Prześlij, aby konwertować mowę na tekst
Kliknij, aby przesłać i transkrybować
Konwertuj mowę na tekst z adresu URL
Najprostszy sposób na automatyczną transkrypcję z dowolnego źródła audio lub wideo.
Prześlij pliki (MP3, WAV, MP4) lub wklej link z YouTube, Google Drive lub Dropbox, aby rozpocząć proces zamiany mowy na tekst.
Wybierz spośród ponad 100 języków. Nasz silnik transkrypcji AI obsługuje różne dialekty, zapewniając maksymalną dokładność dla Twojego pliku.
Kliknij przycisk i pozwól naszemu oprogramowaniu przekonwertować mowę na tekst. Większość transkrypcji jest gotowa w ciągu kilku sekund.
Przejrzyj tekst w naszym edytorze online, a następnie wyeksportuj transkrypt w wielu formatach, w tym TXT, Word lub SRT do napisów.

Przestań marnować godziny na ręczną transkrypcję. Nasz zaawansowany silnik mowy na tekst wykorzystuje najnowocześniejsze uczenie maszynowe, aby zapewnić dokładność do 99%. Niezależnie od tego, czy masz nagranie z wieloma mówcami, czy pełne technicznego żargonu, nasze oprogramowanie filtruje szumy tła, zapewniając precyzyjną i profesjonalną konwersję mowy na tekst.
Przestań przewijać strony tekstu. Nasze narzędzie AI do zamiany mowy na tekst nie tylko transkrybuje – ono rozumie. Natychmiast generuj zwięzłe podsumowania AI z długich filmów, wywiadów lub wykładów. Potrzebujesz konkretnej odpowiedzi? Użyj funkcji Czat AI, aby zadawać pytania bezpośrednio do transkryptu, jak „Jaki był termin projektu?” i otrzymaj natychmiastowe odpowiedzi.
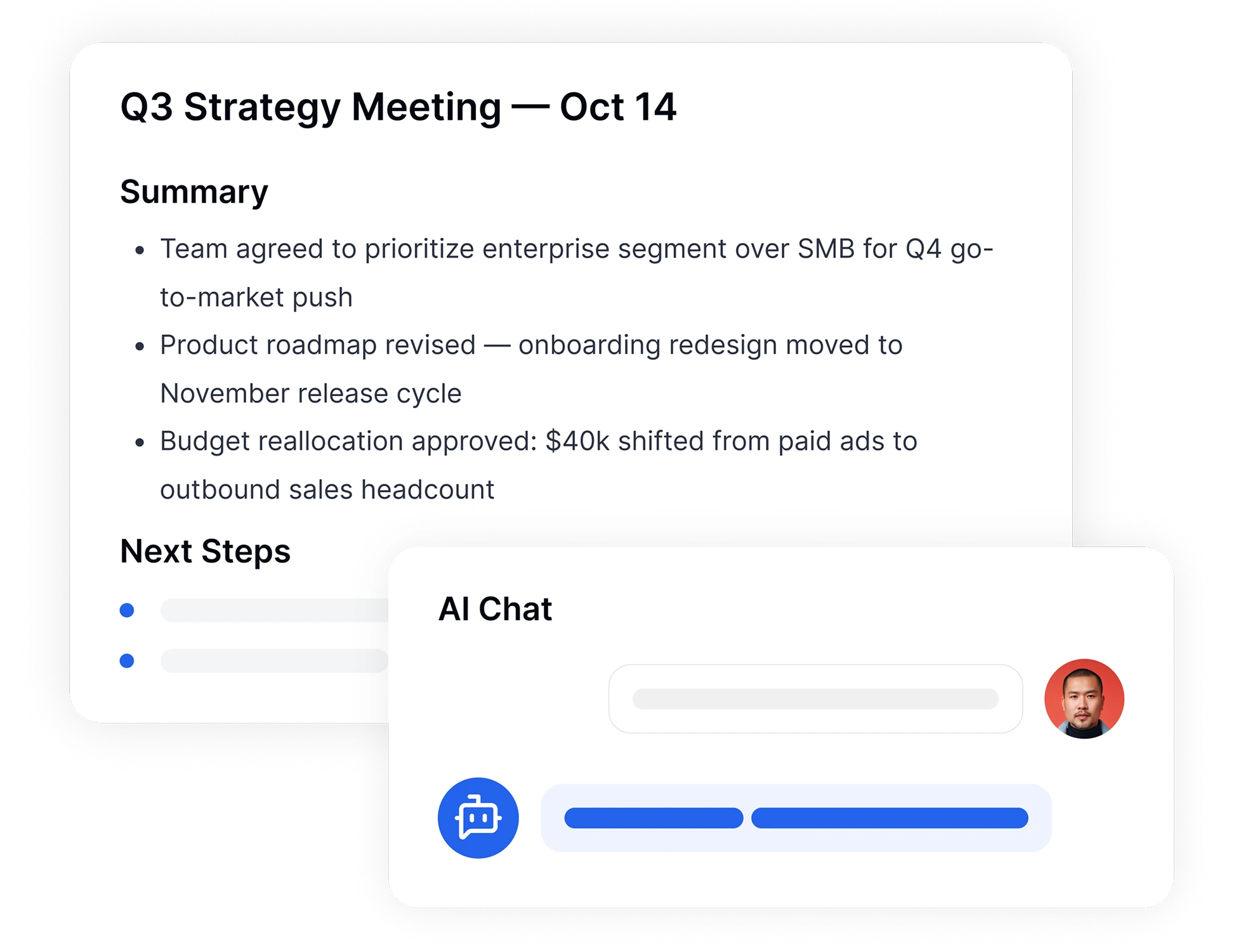
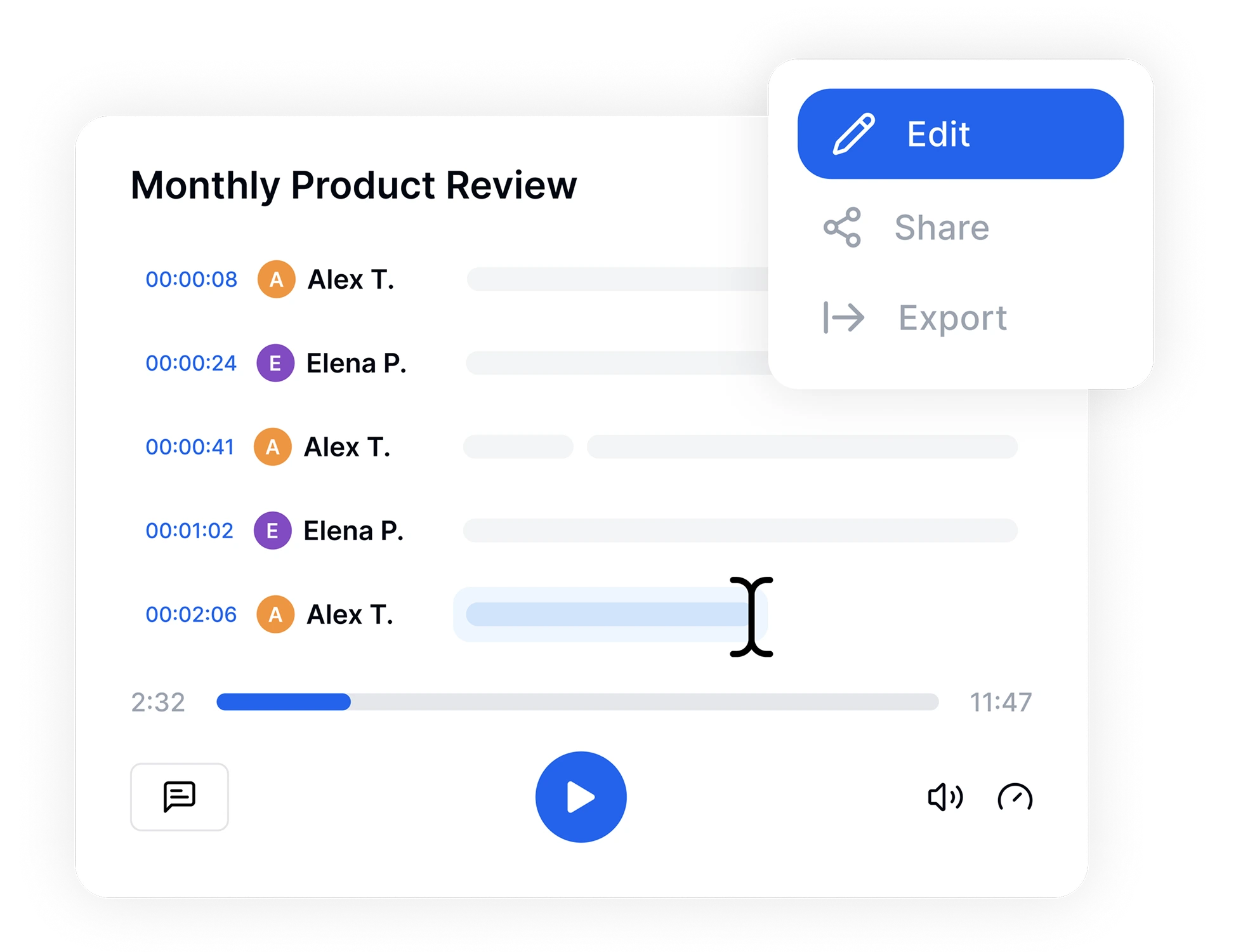
Gdy transkrypcja jest gotowa, użyj naszego intuicyjnego edytora online do szybkich poprawek. Wyróżniaj kluczowe momenty, dodawaj etykiety mówców i przeszukuj tekst. Po zakończeniu wyeksportuj plik w preferowanym formacie—TXT, PDF, Word lub SRT do napisów wideo—i natychmiast udostępnij go swojemu zespołowi.
Odkryj inne narzędzia do konwersji plików audio lub wideo na tekst
Wypróbowałam wiele usług transkrypcji, ale nic nie dorównuje temu narzędziu. Dokładność jest niemal doskonała i oszczędza mi godziny każdego tygodnia. Stało się niezbędną częścią mojego codziennego przepływu pracy przy notatkach ze spotkań.

Sarah K.
Starszy Kierownik Projektu
Tworzenie transkryptów wideo dla mojego kanału YouTube zajmowało mi cały dzień. Teraz wklejam link i w ciągu minut mam pełny plik tekstowy. Eksport SRT sprawia, że napisy to pestka!

Marcus A.
Twórca Treści Cyfrowych
Możesz konwertować mowę na tekst, przesyłając plik audio lub wideo bezpośrednio do naszej platformy. Wiele narzędzi, w tym Transkriptor, oferuje bezpłatny okres próbny umożliwiający przetestowanie dokładności i szybkości transkrypcji AI. Kliknij po prostu 'Prześlij', aby rozpocząć.
Najdokładniejsze oprogramowanie używa zaawansowanych algorytmów AI i uczenia maszynowego, aby osiągnąć dokładność do 99%. Dla najlepszych wyników upewnij się, że Twoje audio jest wyraźne i ma minimalny szum tła. Nasz silnik obsługuje różne akcenty i terminologię techniczną w ponad 100 językach.
Tak! Możesz łatwo konwertować YouTube na tekst lub transkrybować filmy z Google Drive i Dropbox. Wklej URL do pola 'Konwertuj z adresu URL', a nasze narzędzie pobierze audio i w ciągu minut wygeneruje transkrypt wideo.
Nasz konwerter mowy na tekst obsługuje wszystkie główne formaty audio i wideo, w tym MP3, MP4, WAV, AAC i M4A. Po zakończeniu transkrypcji możesz wyeksportować tekst w formatach takich jak TXT, Word lub SRT do napisów.
Dzięki naszej szybkiej transkrypcji AI transkrypcja 1 godziny audio zajmuje zazwyczaj mniej niż 5 minut. Jest to znacznie szybsze niż ręczna transkrypcja, która może zająć do 4 godzin dla tej samej ilości treści.
Absolutnie. Obsługujemy zamianę mowy na tekst w ponad 100 językach, w tym angielskim, hiszpańskim, francuskim, niemieckim, portugalskim, tureckim i arabskim. Nasze narzędzie automatycznie wykrywa język i dostarcza zlokalizowany transkrypt z wysoką precyzją.