1
Audio oder Video hochladen
Laden Sie Ihre Dateien (MP3, WAV, MP4) hoch oder fügen Sie einen Link von YouTube, Google Drive oder Dropbox ein, um den Sprache-zu-Text-Prozess zu starten.
Wandeln Sie Sprache mit unserem KI-gestützten Transkriptionstool sofort in Text um. Egal ob Meetings, Vorlesungen oder Videos – Transkriptor liefert schnelle und hochgenaue Audio-zu-Text-Konvertierungen in über 100 Sprachen.
Hochladen, um Sprache in Text umzuwandeln
Klicken Sie zum Hochladen und Transkribieren
Sprache von URL in Text umwandeln
Der einfachste Weg zur automatischen Transkription aus jeder Audio- oder Videoquelle.
Laden Sie Ihre Dateien (MP3, WAV, MP4) hoch oder fügen Sie einen Link von YouTube, Google Drive oder Dropbox ein, um den Sprache-zu-Text-Prozess zu starten.
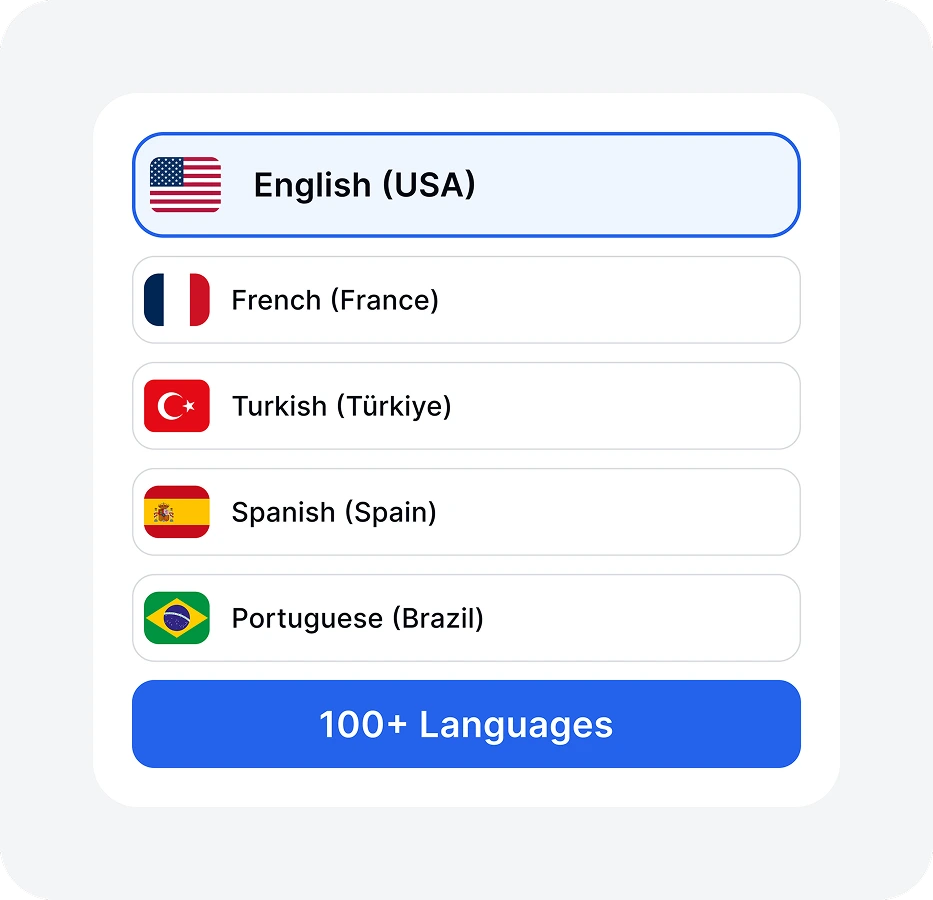
Wählen Sie aus über 100 Sprachen. Unsere KI-Transkriptions-Engine unterstützt verschiedene Dialekte für maximale Genauigkeit.
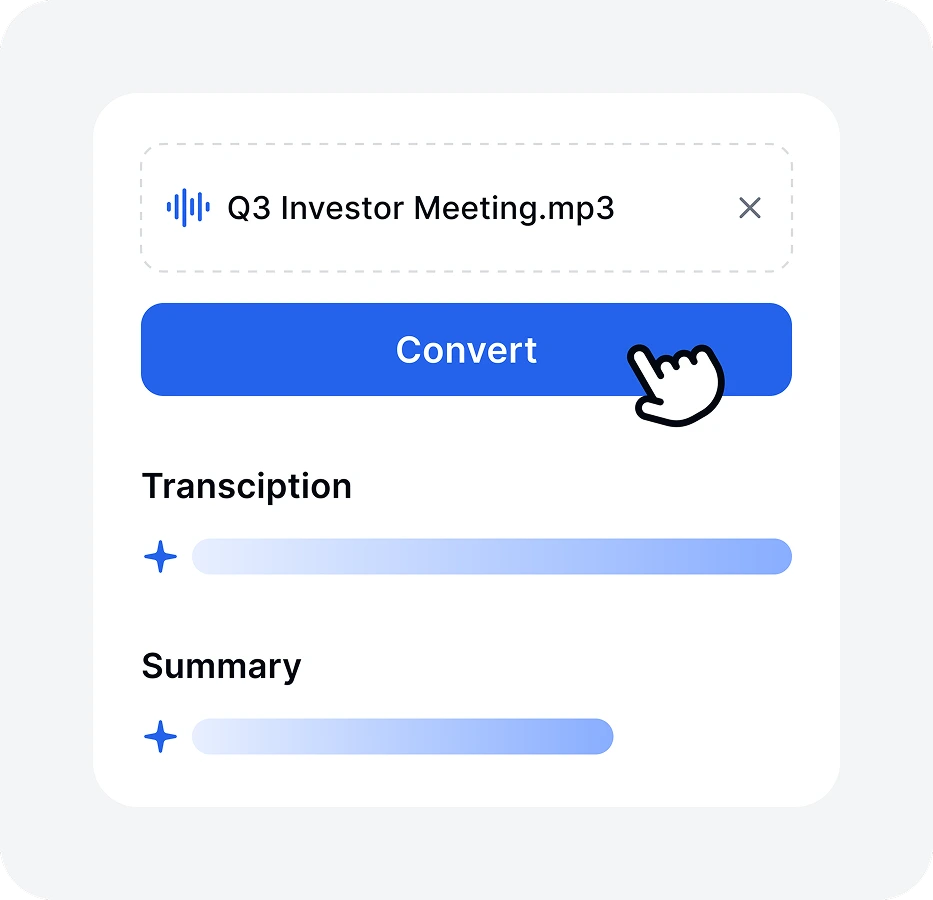
Klicken Sie auf die Schaltfläche und lassen Sie unsere Software Sprache in Text umwandeln. Die meisten Transkriptionen sind in Sekunden abgeschlossen.
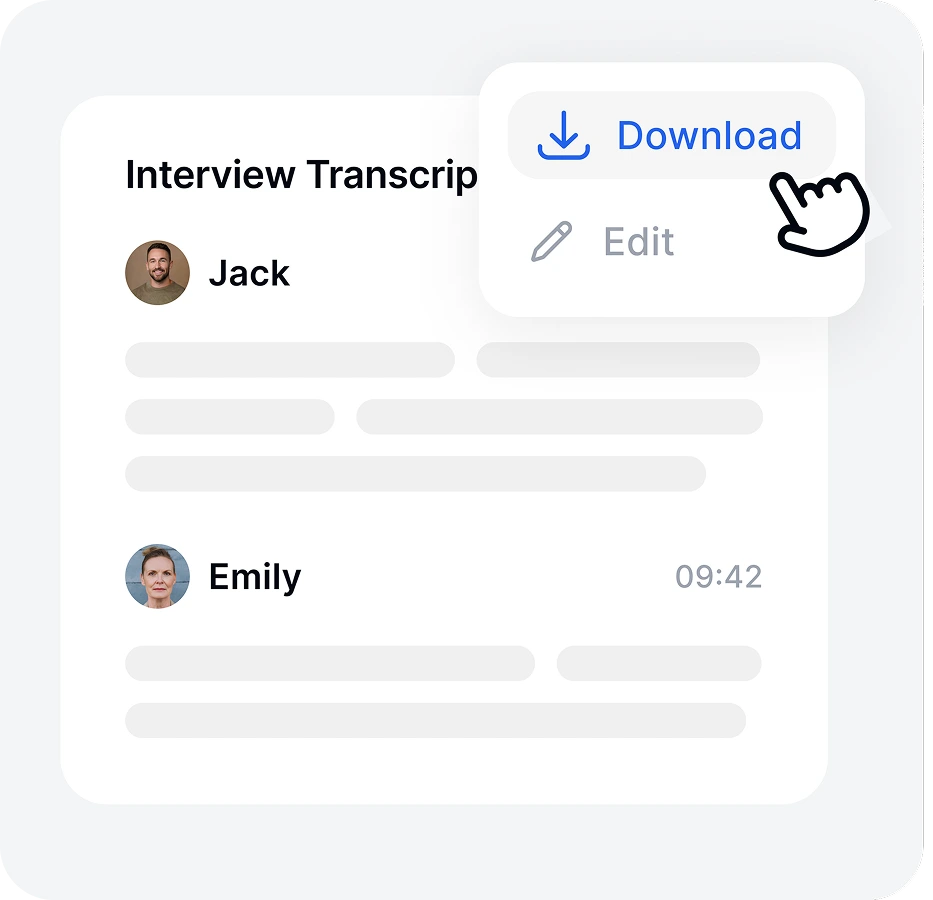
Überprüfen Sie Ihren Text in unserem Online-Editor und exportieren Sie Ihre Transkription in mehreren Formaten, einschließlich TXT, Word oder SRT für Untertitel.

Verschwenden Sie keine Stunden mehr mit manueller Transkription. Unsere fortschrittliche Sprache-zu-Text-Engine nutzt modernste maschinelle Lernverfahren und liefert eine Genauigkeit von bis zu 99 %. Ob Aufnahme mit mehreren Sprechern oder Fachbegriffen – unsere Software filtert Hintergrundgeräusche heraus und sorgt für präzise, professionelle Ergebnisse.
Hören Sie auf, durch seitenlangen Text zu scrollen. Unser KI-Sprache-zu-Text-Tool transkribiert nicht nur, es versteht. Erstellen Sie sofort prägnante KI-Zusammenfassungen langer Videos, Interviews oder Vorlesungen. Nutzen Sie den KI-Chat, um direkte Fragen an Ihre Transkription zu stellen und sofortige Antworten zu erhalten.
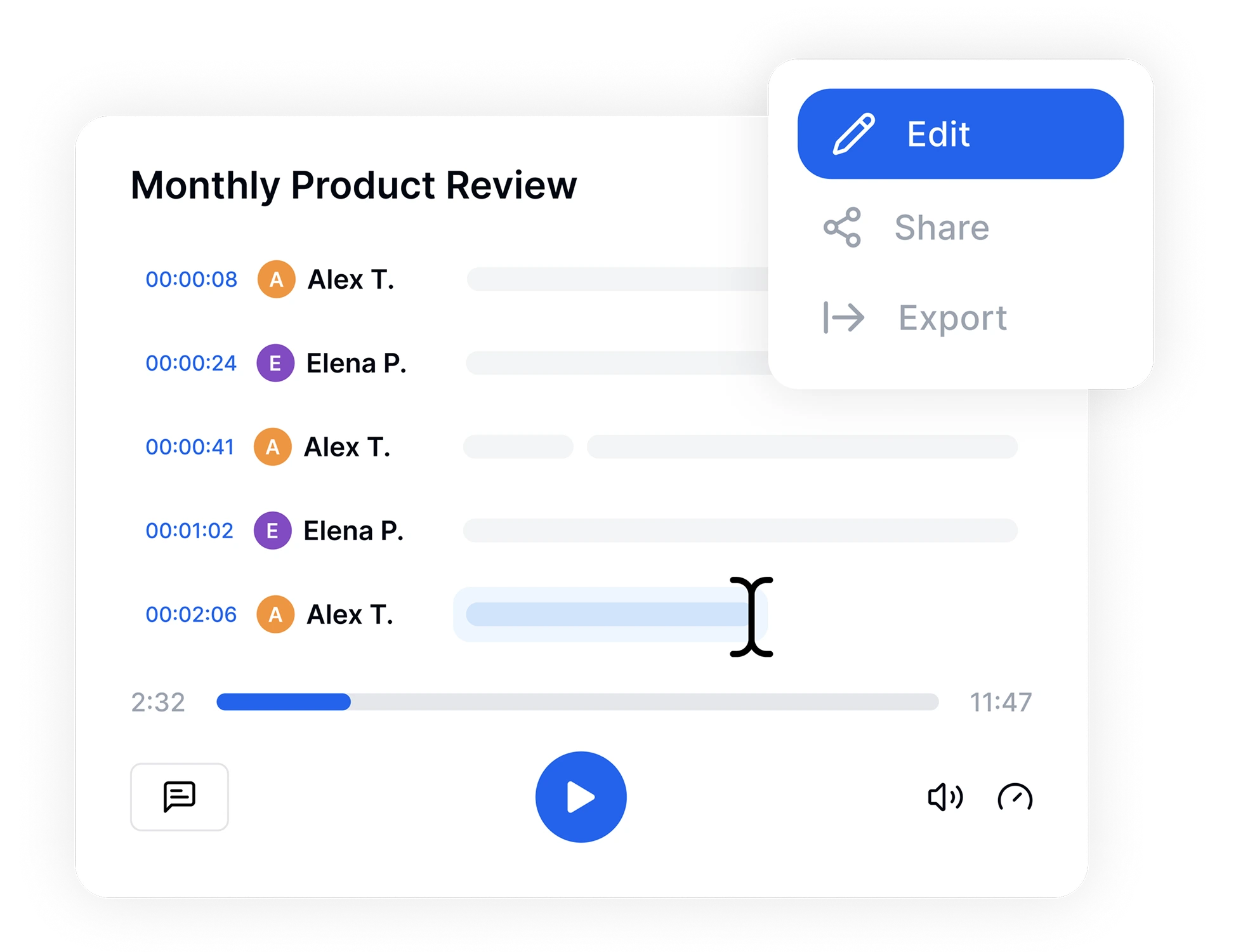
Sobald Ihre Transkription fertig ist, nutzen Sie unseren intuitiven Online-Editor für schnelle Anpassungen. Markieren Sie wichtige Momente, fügen Sie Sprecherbeschriftungen hinzu und durchsuchen Sie Ihren Text. Exportieren Sie die Datei anschließend im bevorzugten Format—TXT, PDF, Word oder SRT für Untertitel—und teilen Sie sie sofort mit Ihrem Team.
Entdecken Sie weitere Tools zur Konvertierung von Audio- oder Videodateien in Text
Ich habe mehrere Transkriptionsdienste ausprobiert, aber nichts kommt an diesen heran. Die Genauigkeit ist nahezu perfekt und spart mir jede Woche Stunden. Es ist ein unverzichtbarer Teil meines täglichen Workflows geworden.

Sarah K.
Senior Projektmanagerin
Video-Transkriptionen für meinen YouTube-Kanal zu erstellen dauerte früher einen ganzen Tag. Jetzt füge ich einfach den Link ein und habe in Minuten eine vollständige Textdatei. Der SRT-Export macht Untertitel zum Kinderspiel!

Marcus A.
Digitaler Content Creator
Sie können Sprache in Text umwandeln, indem Sie Ihre Audio- oder Videodatei direkt auf unsere Plattform hochladen. Viele Tools, einschließlich Transkriptor, bieten eine kostenlose Testversion an. Klicken Sie einfach auf „Hochladen“, um loszulegen.
Die genaueste Software verwendet fortschrittliche KI- und maschinelle Lernalgorithmen, um eine Genauigkeit von bis zu 99 % zu erreichen. Unser Engine ist für verschiedene Akzente und Fachterminologie in über 100 Sprachen ausgelegt.
Ja! Sie können YouTube einfach in Text umwandeln oder Videos von Google Drive und Dropbox transkribieren. Fügen Sie einfach die URL in das Feld „Von URL konvertieren“ ein und unser Tool erstellt in Minuten eine Transkription.
Unser Konverter unterstützt alle gängigen Audio- und Videoformate, einschließlich MP3, MP4, WAV, AAC und M4A. Nach der Transkription können Sie den Text als TXT, Word oder SRT exportieren.
Mit unserer Hochgeschwindigkeits-KI-Transkription dauert die Transkription einer Stunde Audio in der Regel weniger als 5 Minuten. Das ist deutlich schneller als manuelle Transkription, die bis zu 4 Stunden dauern kann.
Absolut. Wir unterstützen Sprache-zu-Text in über 100 Sprachen, darunter Deutsch, Englisch, Spanisch, Französisch, Portugiesisch, Türkisch und Arabisch. Unser Tool erkennt die Sprache automatisch.