1
上传音频或视频
上传文件(MP3、WAV、MP4)或粘贴YouTube、Google Drive或Dropbox的链接,开始语音转文字流程。
使用我们的AI转录工具即时将语音转换为文字。无论您需要转录会议、讲座还是视频,Transkriptor都能以100多种语言提供快速、高精度的音频转文字服务。
上传文件进行语音转文字
点击上传并转录
从URL转换语音为文字
从任何音频或视频来源获取自动转录的最简单方法。
上传文件(MP3、WAV、MP4)或粘贴YouTube、Google Drive或Dropbox的链接,开始语音转文字流程。
从100多种语言中选择。我们的AI转录引擎支持多种方言,确保您的文件具有最高准确度。
点击按钮,让我们的软件将语音转换为文字。大多数转录在几秒内完成。
在我们的在线编辑器中审阅文字,然后以多种格式导出转录稿,包括TXT、Word或字幕用SRT格式。

停止在手动转录上浪费数小时。我们先进的语音转文字引擎使用前沿机器学习技术,准确率高达99%。无论您的录音包含多个说话者还是专业术语,我们的软件都能过滤背景噪音,确保您的语音转文字转换精准专业。
停止翻阅大量文字页面。我们的AI语音转文字工具不仅能转录,还能理解内容。即时生成长视频、采访或讲座的简洁AI摘要,在几秒内捕获关键要点。需要特定答案?使用AI对话功能直接向转录稿提问,如“项目截止日期是什么时候?”,无需阅读整个文件即可获得即时答案。
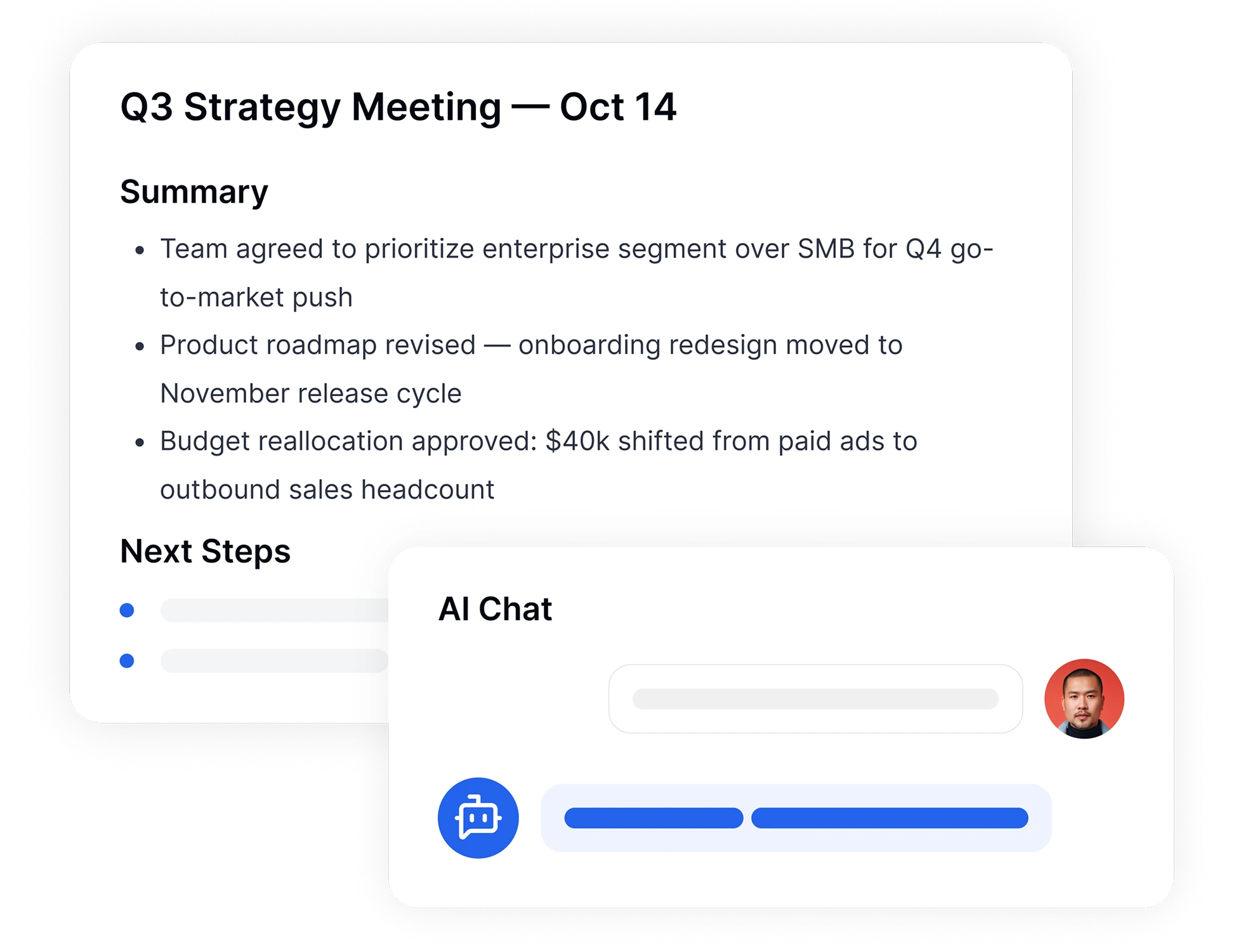
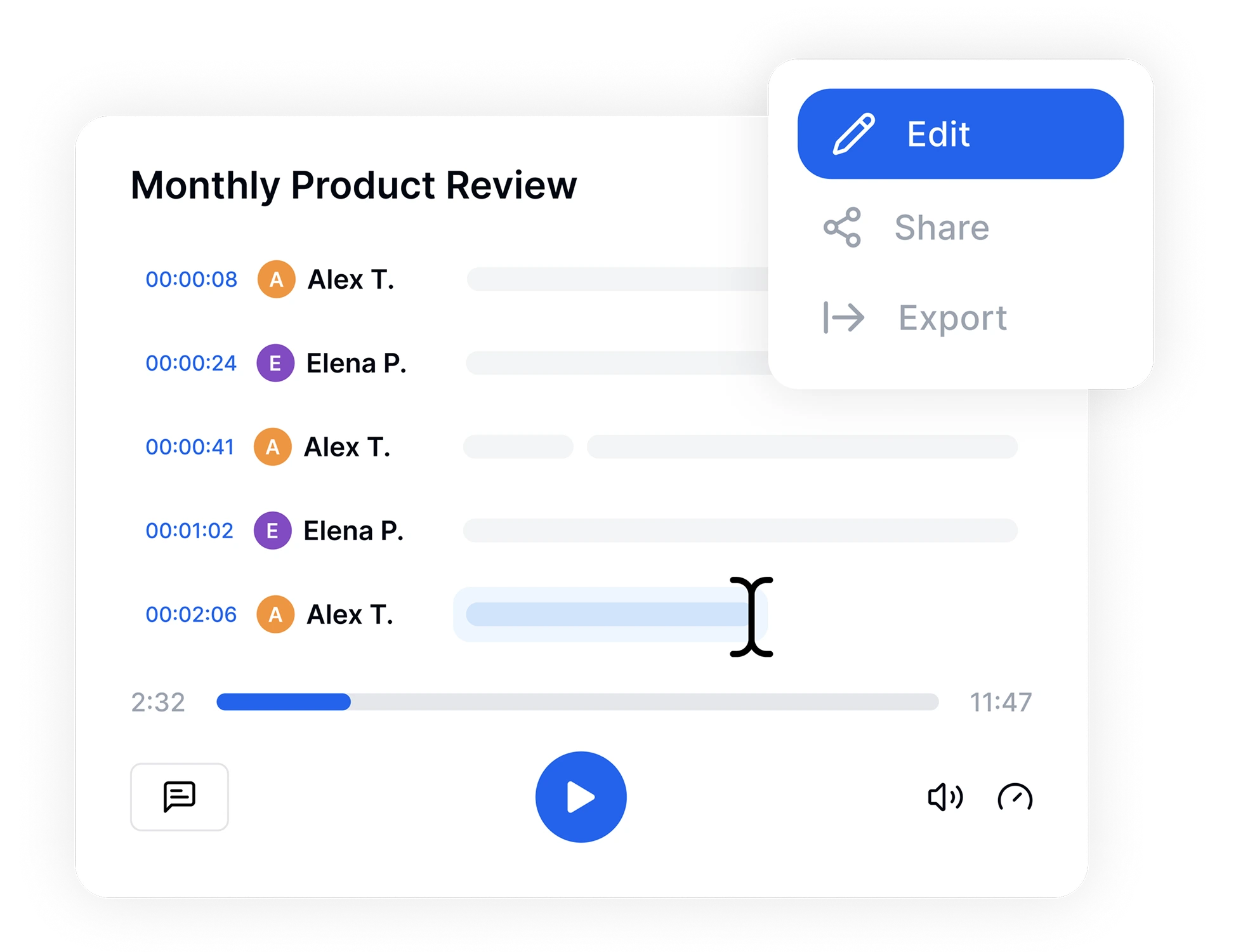
转录完成后,使用我们直观的在线编辑器进行快速调整。高亮重要时刻、添加说话者标签并在文字中搜索。完成后,以您喜欢的格式导出文件—TXT、PDF、Word或视频字幕SRT—并立即与团队分享。
探索其他将音频或视频文件转换为文字的工具
我尝试过多种转录服务,但没有一个能与这个媲美。准确性近乎完美,每周为我节省了好几个小时。它已成为我日常工作流程中记录会议笔记不可或缺的工具。

Sarah K.
高级项目经理
为我的YouTube频道生成视频转录稿以前需要花一整天。现在,我只需粘贴链接,几分钟内就能获得完整的文字文件。SRT导出让字幕制作变得轻而易举!

Marcus A.
数字内容创作者
您可以通过将音频或视频文件直接上传到我们的平台来进行语音转文字。包括Transkriptor在内的许多工具都提供免费试用,让您在订阅计划之前测试AI转录的准确性和速度。只需点击"上传"即可开始。
最准确的软件使用先进的AI和机器学习算法,准确率可达99%。为获得最佳效果,请确保您的音频清晰且背景噪音最小。我们的自动转录引擎专为处理100多种语言的不同口音和专业术语而设计。
可以!您可以轻松将YouTube转换为文字,或转录来自Google Drive和Dropbox的视频。只需将URL粘贴到"从URL转换"框中,我们的工具将获取音频并在几分钟内生成视频转录稿。
我们的语音转文字转换器支持所有主要音频和视频格式,包括MP3、MP4、WAV、AAC和M4A。转录完成后,您可以将文字以TXT、Word或字幕SRT等格式导出。
使用我们的高速AI转录,转录1小时的音频通常只需不到5分钟。这比手动转录快得多——同等内容的手动转录可能需要长达4小时。
当然支持。我们支持100多种语言的语音转文字,包括英语、西班牙语、法语、德语、葡萄牙语、土耳其语和阿拉伯语。我们的工具自动检测语言并以高精度提供本地化转录稿。