Los usuarios pueden aprovechar eficazmente los convertidores de voz a texto para optimizar sus flujos de trabajo, ahorrar tiempo y lograr más en sus esfuerzos profesionales y personales al obtener información sobre la tecnología y las funcionalidades subyacentes, incluida la aplicación móvil Transkriptor . Comprender cómo funcionan los convertidores de voz a texto es crucial para todos los usuarios que buscan mejorar su productividad.
Transkriptor apoya esta tecnología al ofrecer un servicio de conversión de voz a texto altamente eficiente y fácil de usar, proporcionando el poder de la AI avanzada para entregar transcripciones precisas, lo que lo convierte en una herramienta esencial para las estrategias de transcripción de marketing de contenidos que requieren convertir el contenido hablado en material escrito atractivo. Ya sea para reuniones de negocios, investigación académica o notas personales, Transkriptor proporciona una experiencia única, asegurando que cada Word hablado se capture y se convierta en texto con precisión.
¿Cómo funciona la conversión de voz a texto?
Los usuarios hablan a un micrófono conectado a un dispositivo o aplicación en un convertidor de voz a texto para iniciar la transcripción. Después de esto, el convertidor utiliza algoritmos avanzados y técnicas de aprendizaje automático para analizar los patrones de habla y convertirlos en texto escrito. Este proceso consiste en descomponer el habla en unidades más pequeñas, identificar fonemas y luego relacionarlos con palabras de su vocabulario.
Además, el convertidor aprende continuamente de sus interacciones, mejorando su precisión con el tiempo. Los usuarios pueden ajustar la configuración para mejorar la precisión, como las preferencias de idioma y la cancelación de ruido. Pueden editar y formatear el texto según sea necesario una vez que se transcribe el discurso.
Esta tecnología se usa ampliamente en diversas aplicaciones, incluidos asistentes virtuales, servicios de transcripción y herramientas de accesibilidad, que ofrecen formas eficientes y convenientes de convertir palabras habladas en texto escrito.
¿Cuáles son las tecnologías clave detrás de la conversión de voz a texto?
Los usuarios confían en varias tecnologías clave para la conversión de voz a texto.
- Automatic Speech Recognition (ASR): Desempeña un papel crucial en el desciframiento de palabras habladas en texto mediante el análisis de señales de audio Además, Natural Language Processing (NLP) mejora la precisión de la transcripción mediante la interpretación de los matices lingüísticos y el contexto Los algoritmos de aprendizaje automático permiten a los convertidores de voz a texto mejorar continuamente su rendimiento en función de las interacciones y los comentarios de los usuarios, lo que mejora la precisión de la transcripción.
- Inteligencia Artificial (AI): Integra estas tecnologías, permitiendo que los convertidores se adapten a diferentes acentos, idiomas y patrones de habla A través de AI, los convertidores aprenden de vastos conjuntos de datos para reconocer y transcribir el habla con una precisión cada vez mayor.
Estas tecnologías funcionan de forma sinérgica, lo que permite a los usuarios convertir sin esfuerzo las palabras habladas en texto escrito a través de diversas aplicaciones y plataformas como Transkriptor, revolucionando la comunicación y la accesibilidad en la era digital.
¿Cuáles son las aplicaciones de la conversión de voz a texto?
La conversión de voz a texto se ha convertido en parte integral de muchos aspectos de la vida moderna. Se utiliza de varias maneras, y es esencial comprender dónde se encuentra la información crucial.
Servicios de transcripción
Los servicios de transcripción aprovechan la tecnología de conversión de voz a texto para convertir el audio hablado en texto escrito de manera eficiente. Los editores se benefician de los servicios de transcripción en diversos escenarios, como entrevistas, reuniones, conferencias y dictados.
Estos servicios ofrecen a los usuarios la comodidad de transcribir de forma rápida y precisa grandes volúmenes de contenido de audio, ahorrando tiempo y esfuerzo. Profesionales como periodistas , investigadores y estudiantes confían en los servicios de transcripción para crear registros escritos de entrevistas, conferencias y resultados de investigaciones.
Las empresas utilizan servicios de transcripción para generar transcripciones escritas de reuniones, conferencias e interacciones con los clientes para su documentación y análisis.
Tecnologías de asistencia para discapacitados
Las tecnologías de asistencia para discapacitados aprovechan la conversión de voz a texto para aumentar la accesibilidad y la independencia de los usuarios con discapacidades.
Las personas con discapacidades motoras, como parálisis o destreza limitada, pueden utilizar convertidores de voz a texto para operar computadoras, teléfonos inteligentes y otros dispositivos con manos libres. Esta tecnología permite a los editores redactar correos electrónicos, navegar por Internet e interactuar con interfaces digitales mediante comandos de voz.
Además, la conversión de voz a texto facilita la comunicación de las personas con discapacidad auditiva al transcribir las palabras habladas en texto escrito en tiempo real. Los usuarios pueden entablar conversaciones, participar en reuniones y acceder a contenido de audio con mayor facilidad.
Sistemas controlados por voz y asistentes virtuales
Los sistemas controlados por voz y los asistentes virtuales utilizan la conversión de voz a texto para permitir a los usuarios interactuar con dispositivos y aplicaciones mediante comandos de lenguaje natural. Los usuarios pueden realizar varias tareas con manos libres, como configurar recordatorios, enviar mensajes o controlar SMART dispositivos domésticos simplemente hablando en voz alta.
Los asistentes virtuales como Siri, Alexay Google Assistant aprovechan la tecnología de voz a texto para comprender los comandos del usuario, procesarlos y proporcionar respuestas o acciones relevantes. Estos sistemas mejoran la comodidad y la productividad del usuario al eliminar la necesidad de entrada manual y agilizar las tareas a través de la interacción de voz.
Los editores pueden acceder a la información, administrar sus horarios y controlar sus entornos de manera más eficiente, ya sea en casa, en el automóvil o mientras viajan.
Además, otra aplicación de la conversión de voz a texto es que Transkriptor integra perfectamente con plataformas como Google Meet y Zoom, lo que permite a los usuarios transcribir reuniones directamente, mejorando la accesibilidad y facilitando la toma de notas eficiente durante las reuniones virtuales.
Servicios de comunicación y traducción en tiempo real
Los servicios de comunicación y traducción en tiempo real utilizan la conversión de voz a texto para facilitar interacciones fluidas entre usuarios que hablan diferentes idiomas.
Los usuarios pueden participar en conversaciones en vivo, ya sea en persona o de forma remota, con la ayuda de la tecnología de voz a texto que transcribe las palabras habladas en texto escrito en tiempo real. Esto permite WHO las personas que hablan diferentes idiomas se comuniquen de manera efectiva sin la necesidad de un traductor humano.
Además, los servicios de traducción aprovechan la conversión de voz a texto para traducir palabras habladas a texto escrito y luego al idioma deseado, lo que permite a los editores comprender y responder a los mensajes en su idioma preferido.
¿Cuáles son los beneficios de la tecnología de voz a texto?
La adopción de la tecnología de voz a texto permite a los usuarios contar con un medio cómodo, eficiente e inclusivo para convertir el lenguaje hablado en texto escrito, revolucionando la forma en que interactuamos con los dispositivos digitales y la información. Ofrece una gran cantidad de ventajas para los usuarios de varios dominios.
1 Mayor accesibilidad e inclusión
La tecnología de voz a texto ofrece una mayor accesibilidad e inclusión para usuarios con diversas necesidades y preferencias. Las personas con discapacidad auditiva pueden acceder a la información hablada a través de transcripciones de texto , lo que les permite participar plenamente en conversaciones, conferencias y otras interacciones verbales. Los usuarios con discapacidades motoras pueden navegar por las interfaces digitales con manos libres, utilizando comandos de voz para tareas como escribir, navegar y operar dispositivos.
Además, la tecnología de voz a texto rompe las barreras lingüísticas, permitiendo a los usuarios comunicarse y acceder a la información en su idioma preferido, independientemente de las diferencias lingüísticas.
Además, mejora las experiencias de aprendizaje al proporcionar subtítulos, subtítulos y transcripciones para videos educativos y conferencias, atendiendo a diversos estilos de aprendizaje y necesidades de accesibilidad.
2 Mejora de la productividad y la eficiencia
La tecnología de voz a texto mejora significativamente la productividad y la eficiencia en varios sectores.
Los reporteros transcriben entrevistas y dictan artículos rápidamente, cumpliendo fácilmente con plazos ajustados. Los profesionales legales dictan notas de casos y documentos, lo que reduce el tiempo dedicado a la transcripción manual y aumenta el enfoque en las necesidades del cliente.
Los médicos dictan de manera eficiente las notas de los pacientes durante los exámenes, lo que mejora la precisión de la documentación y libera más tiempo para la atención del paciente. Los empleados dictan correos electrónicos, informes y memorandos en entornos corporativos, lo que agiliza los procesos de comunicación y gestión de tareas.
3 Mejora de la precisión y el análisis de los datos
Los avances en la tecnología de voz a texto mejoran significativamente la precisión y el análisis de datos para los usuarios de diversas industrias. Esta tecnología minimiza los errores que pueden ocurrir a través de la entrada manual de datos al transcribir con precisión las palabras habladas en texto escrito.
Los editores pueden confiar en transcripciones precisas para documentación importante, como actas de reuniones, entrevistas e historiales médicos, lo que garantiza la integridad de los datos y el cumplimiento de las normas reglamentarias.
Además, la tecnología de voz a texto facilita el análisis de grandes volúmenes de datos de audio convirtiéndolos en un formato de texto analizable y con capacidad de búsqueda. Los investigadores, analistas y empresas aprovechan esta capacidad para extraer información, identificar patrones y tomar decisiones basadas en datos de manera más eficiente.
Además, la integración con algoritmos de Natural Language Processing y aprendizaje automático mejora aún más las capacidades de análisis de datos, lo que permite a los usuarios descubrir información y tendencias valiosas a partir del contenido hablado.
¿Cuáles son los desafíos en la conversión de voz a texto?
La tecnología de conversión de voz a texto también presenta a los editores varios desafíos que afectan su efectividad y confiabilidad a pesar de sus numerosos beneficios. Comprender estos desafíos es crucial para que los usuarios naveguen por las limitaciones de esta tecnología y tomen decisiones informadas con respecto a su uso.
1 Lidiar con los acentos y el dialecto
Los usuarios a menudo encuentran desafíos con la conversión de voz a texto cuando se trata de acentos y dialectos. Los acentos varían ampliamente entre los hablantes, lo que presenta dificultades para que los sistemas de reconocimiento de voz transcriban con precisión las palabras habladas. Los usuarios con acentos o dialectos no estándar pueden experimentar una menor precisión de transcripción, lo que provoca errores en el texto convertido.
Además, los dialectos regionales y los términos de la jerga pueden complicar aún más el proceso de transcripción, ya que los sistemas de reconocimiento de voz tienen dificultades para interpretar variaciones lingüísticas desconocidas. Los editores suelen optar por convertidores de voz a texto con funciones de personalización de acento y dialecto para mitigar estos desafíos, lo que permite que el sistema se adapte a patrones de habla específicos.
Además, los avances continuos en la tecnología de reconocimiento de voz tienen como objetivo mejorar la precisión en diversos acentos y dialectos a través de algoritmos mejorados de entrenamiento y aprendizaje automático.
2 Problemas de ruido de fondo y calidad de sonido
Los usuarios a menudo se enfrentan a problemas de ruido de fondo y calidad de sonido cuando utilizan la tecnología de conversión de voz a texto. El ruido de fondo, como las charlas, la música o los sonidos ambientales, puede interferir con la precisión de los sistemas de reconocimiento de voz, lo que provoca errores en el texto transcrito.
La mala calidad del sonido, incluido el volumen bajo, el habla apagada o el audio distorsionado, exacerba aún más estos desafíos, ya que los algoritmos de reconocimiento de voz luchan por descifrar patrones de habla poco claros o indistintos. Los editores pueden experimentar frustración y disminución de la precisión de la transcripción cuando intentan convertir voz en entornos ruidosos o con condiciones de grabación subóptimas.
Los usuarios pueden minimizar el ruido de fondo eligiendo entornos silenciosos para la entrada de voz y optimizando la configuración del micrófono para obtener una mejor calidad de sonido para abordar estos desafíos. Además, los convertidores de voz a texto equipados con funciones de cancelación de ruido ayudan a mitigar el impacto del ruido de fondo, mejorando la precisión de la transcripción y la experiencia general del usuario.
3 Comprensión contextual y homófonos
Los usuarios a menudo encuentran desafíos con la comprensión contextual y los homófonos cuando utilizan la tecnología de conversión de voz a texto. El software de reconocimiento de voz puede tener dificultades para interpretar con precisión las palabras habladas sin el contexto adecuado, lo que provoca errores en la transcripción.
Las frases ambiguas u homófonos (palabras que suenan igual pero tienen significados diferentes) plantean dificultades particulares, ya que los convertidores de voz a texto malinterpretan el Word previsto en función del contexto. Por ejemplo, distinguir entre "escribir" y "derecho" o "su", "allí" y "están" es un desafío para estos sistemas.
Los editores deben corregir o editar manualmente el texto transcrito para garantizar la precisión, especialmente en contextos en los que el lenguaje preciso es crucial, como los entornos académicos o profesionales.
Los continuos avances en Natural Language Processing y aprendizaje automático tienen como objetivo mejorar la comprensión contextual y el reconocimiento homófono en la conversión de voz a texto, mejorando la precisión general de la transcripción del usuario.
¿Cómo elegir un convertidor de voz a texto?
Los usuarios deben tener en cuenta varios factores para asegurarse de que satisface sus necesidades a la hora de elegir un convertidor de voz a texto. La precisión es primordial, ya que los editores confían en el convertidor para transcribir el discurso con precisión. La velocidad es otro aspecto crucial, especialmente para los usuarios que requieren transcripción en tiempo real.
La compatibilidad con diferentes idiomas y acentos garantiza la versatilidad y la inclusión en la comunicación. Los usuarios también deben evaluar la facilidad de uso del convertidor y la compatibilidad con sus dispositivos y plataformas.
Además, tener en cuenta características como las opciones de puntuación y formato mejora la usabilidad del convertidor para tareas específicas. La integración con otras aplicaciones y servicios también es crucial para una integración perfecta del flujo de trabajo. Por último, los editores deben evaluar las medidas de privacidad y seguridad del convertidor para salvaguardar la información confidencial.
¿Cómo convertir archivos de voz a texto con Transkriptor?
Los usuarios que buscan un método fácil y eficiente para convertir archivos de voz en texto encontrarán en Transkriptor una herramienta valiosa. Diseñado pensando en la comodidad del usuario, Transkriptor ofrece una plataforma sencilla e intuitiva para una conversión precisa de voz a texto.
1 Únete
Los usuarios deben navegar hasta el sitio web de Transkriptory ubicar la página de registro para registrarse para Transkriptor y convertir archivos de voz a texto. Se les pedirá que proporcionen información básica en la página de registro, como la dirección de correo electrónico y la contraseña deseada.
Después de ingresar esta información, los editores deben hacer clic en el botón "Registrarse" para continuar. Una vez que se complete el proceso de registro, deben iniciar sesión en su cuenta de Transkriptor y comenzar a cargar archivos de voz para la conversión.
Además, los usuarios tienen la opción de personalizar la configuración de su cuenta, como las preferencias de idioma o el nombre de usuario y el correo electrónico, para que se adapte a sus necesidades y preferencias específicas.
2 Cargar o grabar voz
Los usuarios deben iniciar sesión en su cuenta y navegar a la herramienta de conversión de voz para cargar o grabar voz en Transkriptor. A partir de ahí, pueden cargar archivos de voz pregrabados en formatos comunes como MP3, MP4o WAV o elegir grabar voz directamente usando el micrófono de su dispositivo.
Los editores simplemente necesitan hacer clic en el botón "Cargar" y seleccionar el archivo deseado de su computadora o dispositivo para cargar archivos. Alternativamente, deben hacer clic en el botón "Grabar" para grabar el habla en tiempo real.
A continuación, Transkriptor procesará la voz cargada o grabada y la convertirá en texto escrito utilizando algoritmos avanzados de conversión de voz a texto.
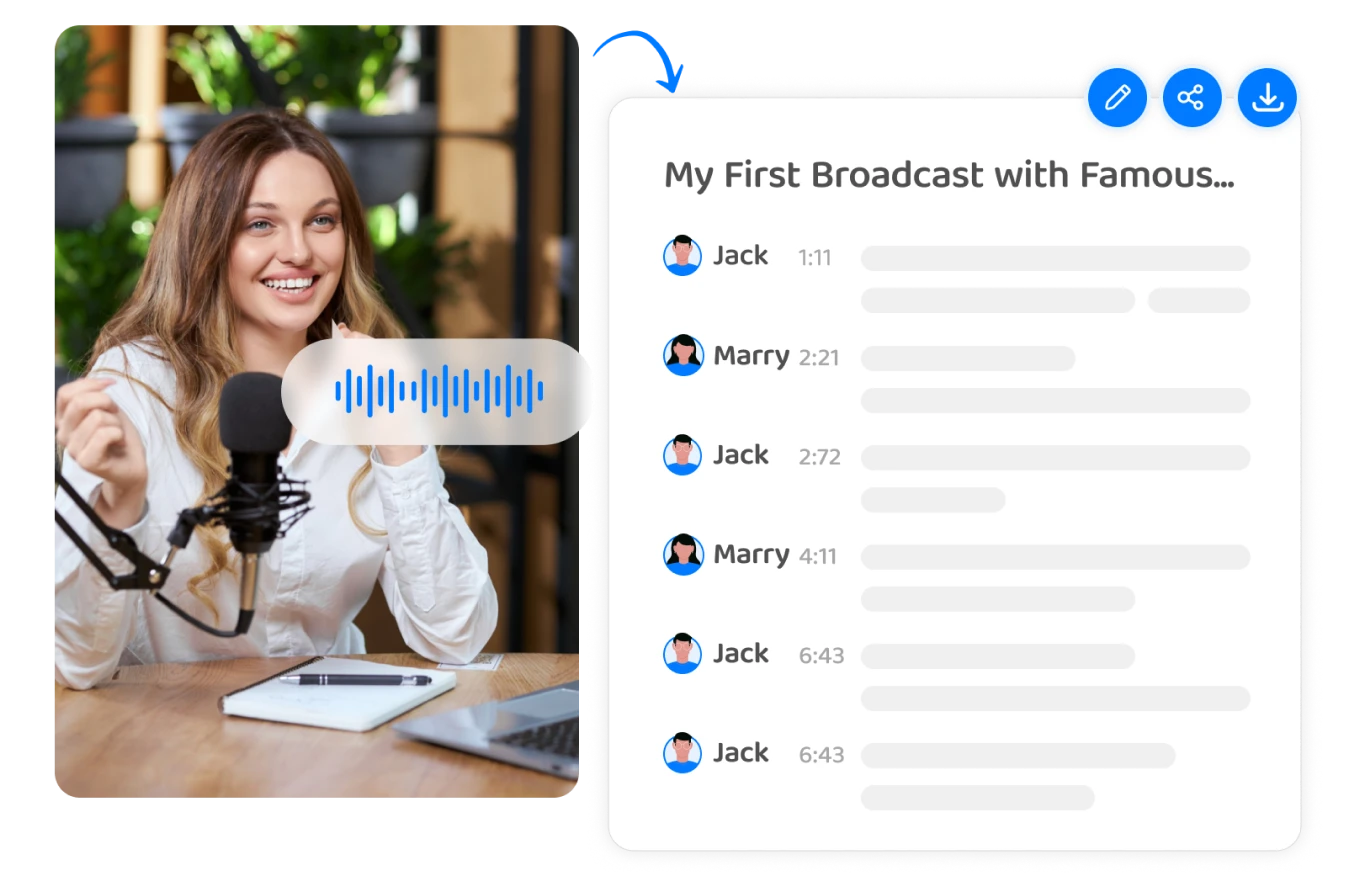
3 Editar, descargar o compartir
Los editores pueden editar, descargar o compartir fácilmente sus transcripciones después de convertir voz a texto con Transkriptor. Encontrarán opciones para editar el texto transcrito directamente dentro de la interfaz de Transkriptor , haciendo las correcciones o ajustes necesarios para mayor precisión.
Los usuarios pueden descargarlo en varios formatos de archivo, como TXT, DOCxo SRT una vez que estén satisfechos con la transcripción, según sus preferencias y necesidades.
Además, pueden compartir la transcripción con otros generando un enlace para compartir y enviándolo por correo electrónico o aplicaciones de mensajería. Esta función facilita la colaboración y la comunicación entre los miembros del equipo o las partes interesadas WHO necesitan acceder al contenido transcrito.
Transkriptor permite a los usuarios administrar su contenido de voz transcrito de manera eficiente de acuerdo con sus requisitos y flujos de trabajo al ofrecer capacidades de edición, descarga y uso compartido sin problemas.