
Can ChatGPT Transcribe Audio?
Transcribe, Translate & Summarize in Seconds
Quick Answer: ChatGPT transcribes audio through OpenAI's Whisper model, but with a 25MB file cap, no speaker identification, and no meeting integration. Transkriptor delivers 99%+ accuracy across 100+ languages with zero setup required.
Recording a meeting, interview, or lecture and then needing accurate text fast is one of the most common professional frustrations today. Many users turn to ChatGPT expecting a seamless fix. Naturally, this leads to one key question: can ChatGPT transcribe audio? It comes up often, and the honest answer is more nuanced than simple yes or no.
ChatGPT can transcribe audio files using OpenAI's Whisper model. Still, a hard 25MB file cap, the absence of speaker labels, unreliable direct uploads, and zero meeting platform integrations limit what it realistically delivers. For short, clean, single-speaker clips, ChatGPT can work. For professional recordings, multi-speaker meetings, and long audio files, those limitations compound quickly, and knowing exactly where they hit helps you avoid wasted time.
How Does ChatGPT Transcribe Audio?
If you're wondering whether ChatGPT can transcribe audio to text, the answer is yes. It offers three different methods, each suited to a specific use case. Whether you are dictating quick voice notes or handling more advanced workflows, choosing the right option helps you get accurate results without unnecessary friction.
Method 1: Direct File Upload (GPT-5.4)
GPT-5.4 supports uploading audio files directly to the ChatGPT chat window. Users on ChatGPT Plus, Team, and Enterprise plans can attach MP3, WAV, M4A, or WebM files and prompt ChatGPT to transcribe the audio.
In real-world testing, the file upload itself completed successfully, but transcription failed. After uploading an audio file, ChatGPT remained in “thinking” mode for 5 minutes and 6 seconds before taking action. It then spent 29 seconds attempting to process the file, trying Whisper, falling back to SpeechBrain, checking for available ASR models, connecting to FFmpeg, and running a sample test. Despite these steps, no transcript was generated, and the transcription attempt failed.
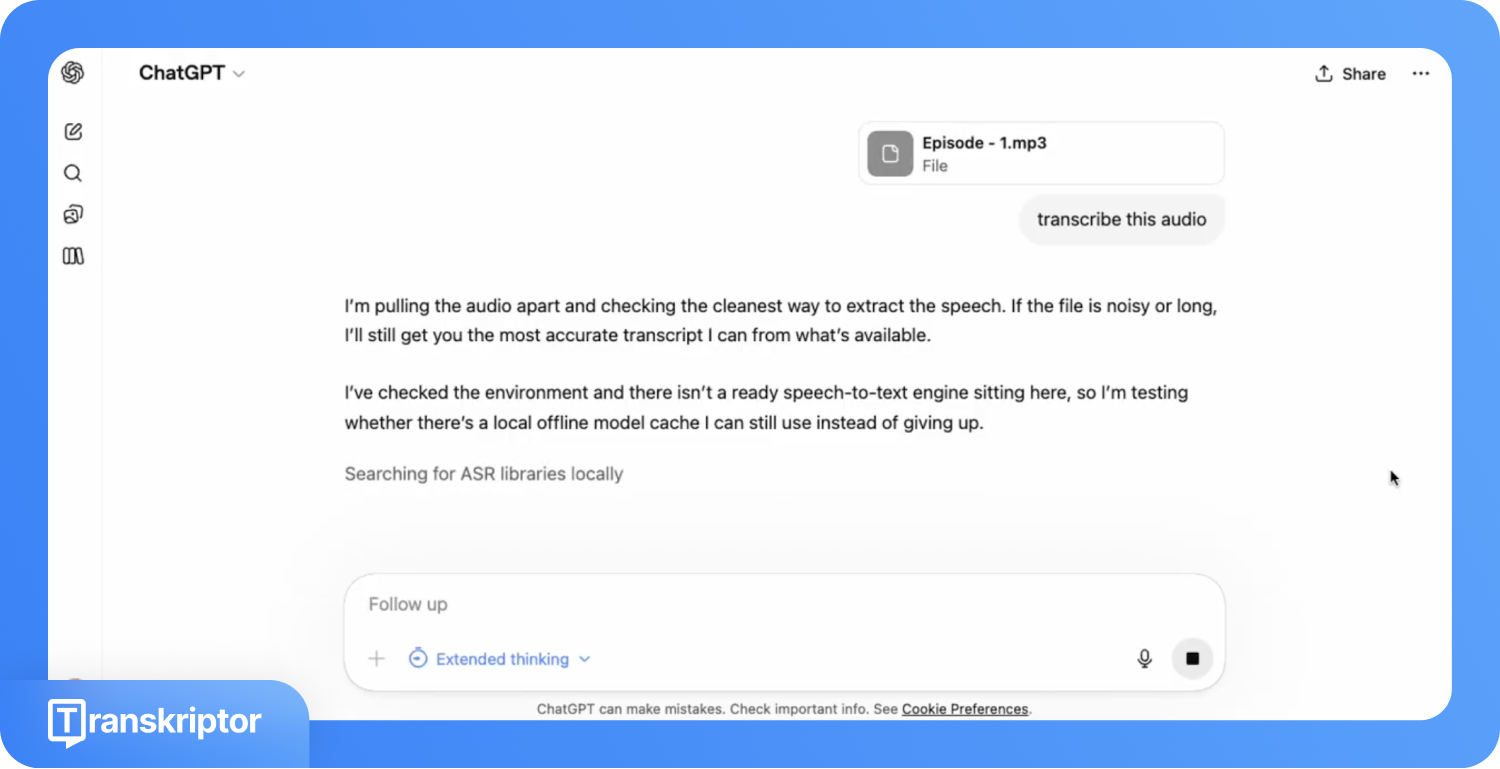
On top of that, unreliability sets a hard technical limit. The 25MB file size cap means any recording beyond roughly 25 minutes at standard MP3 quality exceeds the ceiling before ChatGPT even begins.
Method 2: Record Mode
Record mode lets users speak directly into ChatGPT via the microphone icon in the desktop or mobile app. ChatGPT listens to the user's speech, processes it after the user stops speaking, and delivers the written output.
Record mode works reliably for short, single-speaker audio. It does not provide real-time transcription, and the written text appears only after the speaker finishes. Live meetings, multi-speaker conversations, and long recordings fall outside its functional range. For quick personal voice notes, it gets the job done.
Method 3: Whisper API (For Developers)
The Whisper API is built for developers who want to add audio transcription directly into their own apps, websites, or internal tools. Regular ChatGPT users do not need it, but for a developer who wants automated, large-scale transcription, it is the most direct path OpenAI provides.
How ChatGPT works is straightforward. A developer sends an audio file to OpenAI's servers, and OpenAI sends back a written transcript. No chat window is involved; it runs entirely in code.
OpenAI officially offers three transcription models through the API. whisper-1 is the original and most flexible; it handles the widest range of output formats. gpt-4o-transcribe is newer and more accurate, particularly across languages. gpt-4o-mini-transcribe offers similar improvements at a lower cost, suited for high-volume use.
According to OpenAI's official documentation, ChatGPT accepts the following file formats: MP3, MP4, MPEG, M4A, WAV, and WebM. Every file must stay under 25MB. If the file is larger, the developer must split it into smaller pieces first and send each piece separately.
What ChatGPT cannot do matters just as much. The Whisper API does not identify speakers. If three people talk in a recording, the transcript appears as a single continuous block of text with no labels indicating who said what. The gpt-4o-transcribe model adds one more constraint: audio cannot exceed 1,500 seconds (25 minutes) per file; otherwise, the request fails with an error.
In short, the Whisper API gives developers a reliable, code-based route to transcription. For anyone without a development background or who needs speaker labels and longer file support, a ready-made solution removes all those technical barriers.
What are the Limitations of Using ChatGPT for Audio?
ChatGPT can transcribe audio under limited conditions, but six concrete limitations prevent its professional use. Each one creates a real problem for teams handling meetings, long recordings, or multi-speaker audio.
25MB File Size Cap: OpenAI's Audio API enforces a 25MB maximum on all uploads. A standard one-hour meeting recording in MP3 format regularly exceeds this limit, requiring manual file splitting before every upload.
No Speaker Identification: ChatGPT cannot transcribe audio to text with speaker labels. Every participant's words merge into a single, undifferentiated text block, making meeting transcripts nearly unusable for documentation or follow-up.
No Meeting Platform Integrations: ChatGPT has no connections to Zoom, Google Meet, or Microsoft Teams. Transcribing a meeting recording means manually exporting, compressing, and uploading each file individually.
Unreliable Direct Upload Performance: GPT-4o's direct file uploads frequently fail entirely. ChatGPT cycles through multiple backend tools, Whisper, SpeechBrain, and FFmpeg, without completing the task, even after several minutes of processing.
No Real-Time Transcription: Record mode returns text only after the speaker stops. Live, word-by-word transcription during a meeting or interview is unavailable across all ChatGPT interfaces.
Restricted Output Formats Via API: gpt-4o-transcribe outputs only JSON or plain text. Subtitle formats like SRT and VTT require switching to whisper-1, adding model management overhead to every video-related workflow.
ChatGPT vs. Transkriptor: Side-by-Side Comparison
When you want to know if ChatGPT can transcribe audio from a video, you quickly find answers, but then start looking for a more reliable option. That is where comparing transcription tools side by side helps. Here is how ChatGPT and Transkriptor differ across key features:
| Feature | ChatGPT (Whisper and 5.4 model) | Transkriptor |
|---|---|---|
| File size limit | 25MB | No restrictive cap |
| Languages supported | 57+ | 100+ |
| Speaker identification | No | Yes, automatic |
| Real-time transcription | No | No |
| Meeting integrations | None | Zoom, Teams, Google Meet, Webex |
| Output formats | JSON, text, SRT (whisper-1), VTT | TXT, DOCX, SRT, PDF |
| AI summaries | Manual prompting required | Automatic |
| Direct upload reliability | Inconsistent, may fail | Consistent |
| Accuracy | Variable | 99%+ |
| Free plan | Basic ChatGPT tier | 90 minutes |
| Setup required | Account or API key | Account signup only |
| GDPR/SOC 2 | Not stated for consumer product | Yes |
When to Use ChatGPT to Transcribe Audio?
ChatGPT performs well at audio transcription in a narrow set of low-stakes scenarios. ChatGPT fits best when:
You need a quick transcript of a short, clean audio clip under 25 MB, and you're already using ChatGPT.
You want to combine transcription with immediate summarization, translation, or analysis in a single prompt.
You are a developer prototyping a voice-to-text feature inside the OpenAI ecosystem using the Whisper API.
Single-speaker recordings with clear audio and minimal background noise are your only use case.
When to Use Transkriptor to Transcribe Audio to Text?
If you are trying to decide whether to rely on ChatGPT for transcription or switch to a dedicated tool, the difference becomes clear in real use. In one test, uploading an audio file to ChatGPT 5.4 took over five minutes, went through multiple failed backend attempts, including Whisper, SpeechBrain, FFmpeg, and a sample run, and still produced no transcript. Transkriptor handled the same file in a few minutes, delivered a complete speaker-labeled transcript, and required nothing beyond a simple upload. That reliability gap is exactly why the comparison matters.
Transkriptor converts audio to accurate, editable text in four steps with no technical knowledge required. Here are some common reasons you need Transkriptor:
You need to transcribe audio recordings from meetings with multiple speakers and require automatic speaker labels.
Your audio or video files exceed 25MB.
You need automatic AI summaries, action items, or sentiment analysis delivered alongside the transcript.
You work across languages and need consistent, reliable results across 100+ languages.
You need SRT subtitle exports or DOCX documentation without extra file conversion steps.
You want native Zoom, Google Meet, or Teams integration that eliminates manual recording exports.
How to Use Transkriptor to Transcribe Audio Files?
Transkriptor converts audio to accurate, editable text in four steps without any technical knowledge. Follow the steps below:
Step 1: Create the account and access the dashboard. Here, choose Upload and Transcribe if you have a recording, or Record and Transcribe.
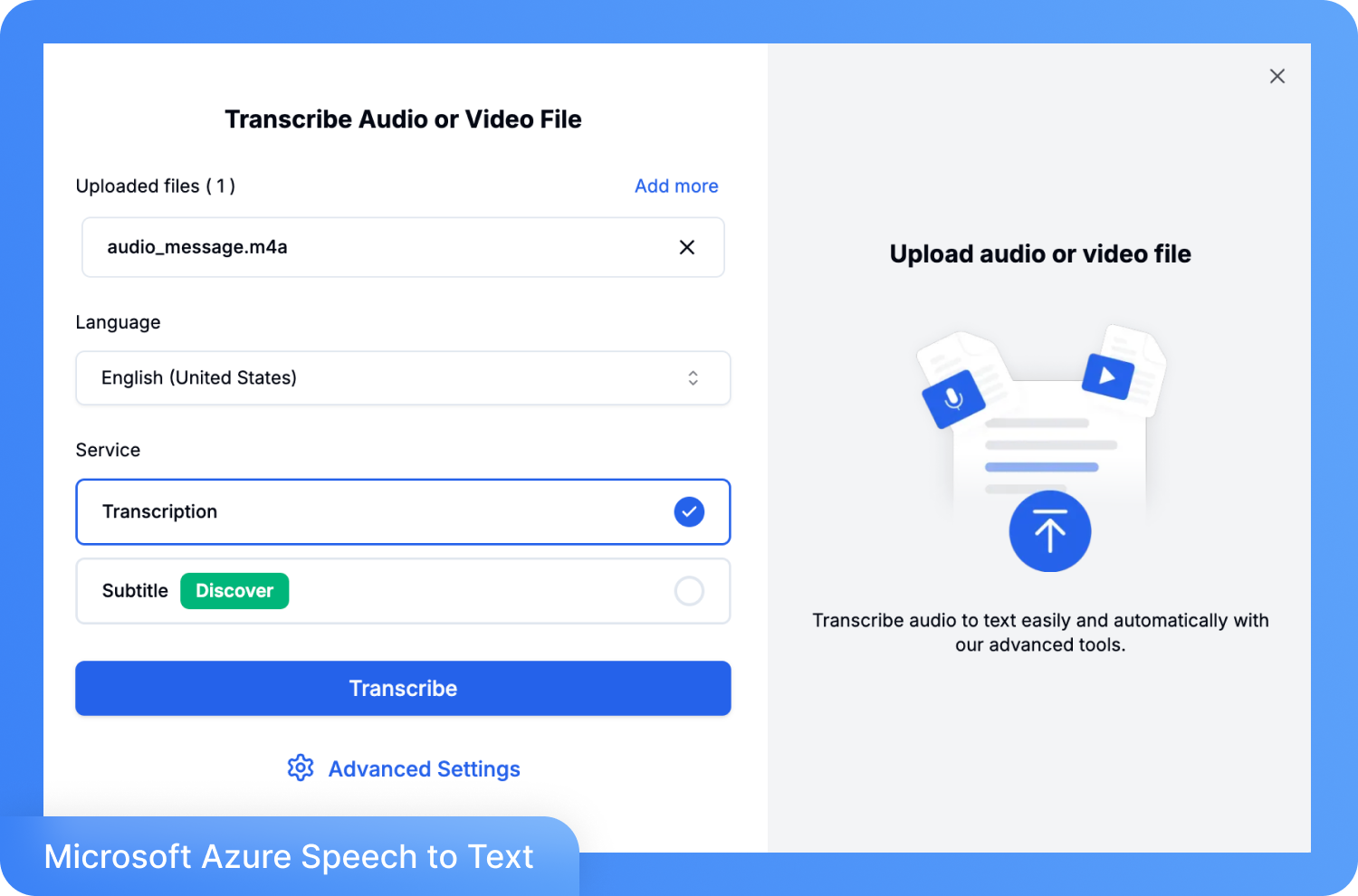
Step 2: Upload the file, choose the target language, and click Transcribe.
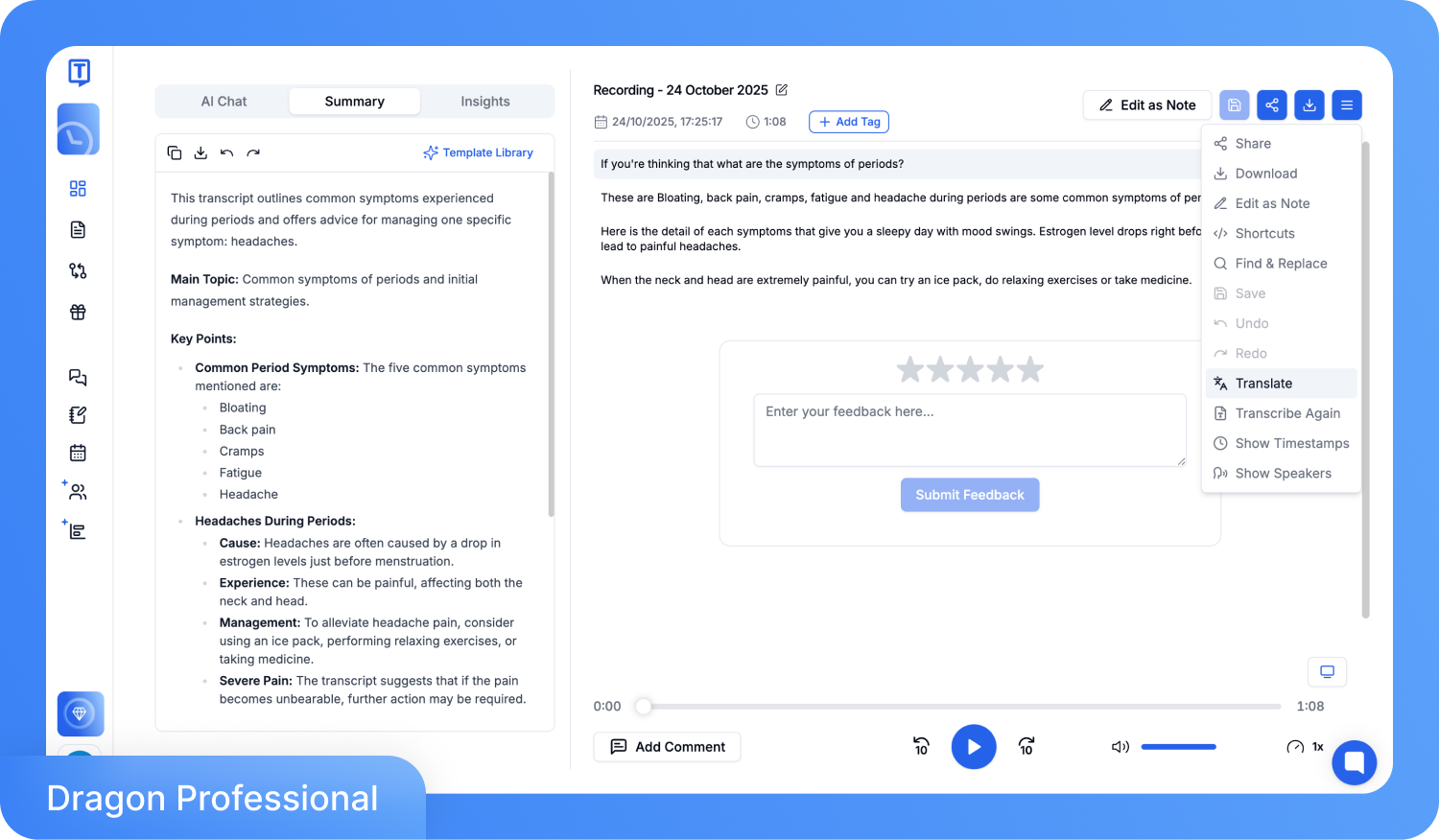
Step 3: After a few minutes, you will get the complete transcription. Open the built-in editor, correct any errors, rename speakers, and adjust timestamps. If you want a transcription in multiple languages, click the Translate option.
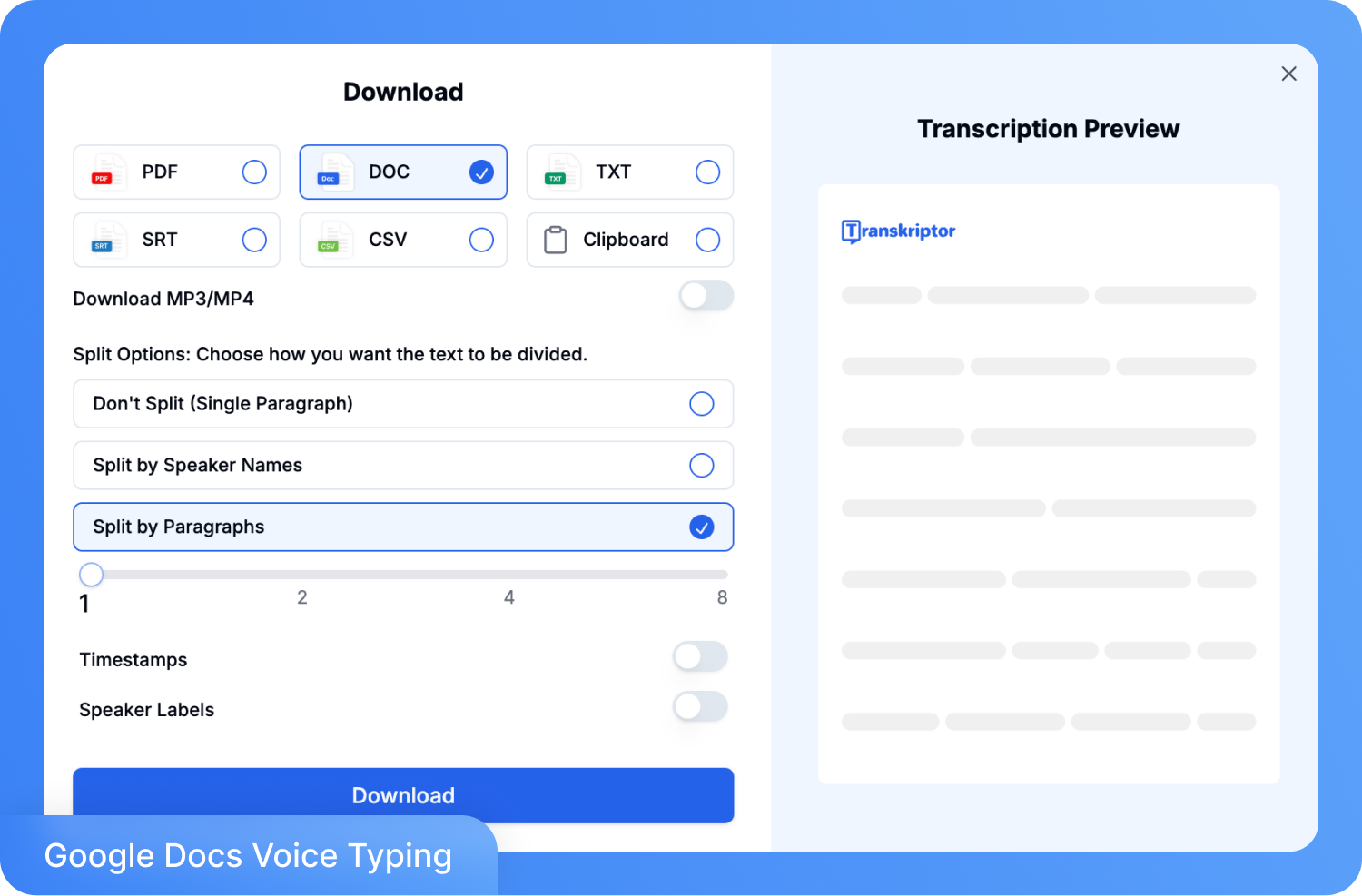
Step 4: Export the final transcript in TXT, DOCX, SRT, or PDF format. Share directly with your team or download it for reports, captions, or any documentation workflow.
Conclusion
Now you have the answer to whether ChatGPT can transcribe audio. It works for basic needs, especially short, clean recordings with a single speaker under 25 MB. Beyond that narrow range, its limits compound quickly: no speaker labels, no meeting integrations, unreliable file uploads, and a hard file-size ceiling that cuts off longer recordings before they start. Transkriptor closes every gap. It delivers 99%+ accuracy across 100+ languages, automatically labels speakers, and integrates directly with Zoom, Google Meet, and Microsoft Teams. Start with the free plan at Transkriptor.com and get your first accurate transcript in just a few minutes.