1
Upload Audio or Video
Upload your files (MP3, WAV, MP4) or paste a link from YouTube, Google Drive, or Dropbox to start the speech to text process.
Convert speech to text instantly with our AI-powered transcription tool. Whether you need to transcribe meetings, lectures, or videos, Transkriptor delivers fast, highly accurate audio to text conversions in 100+ languages.
Upload to convert speech to text
Click to upload and transcribe
Convert speech to text from URL
The easiest way to get automatic transcription from any audio or video source.
Upload your files (MP3, WAV, MP4) or paste a link from YouTube, Google Drive, or Dropbox to start the speech to text process.
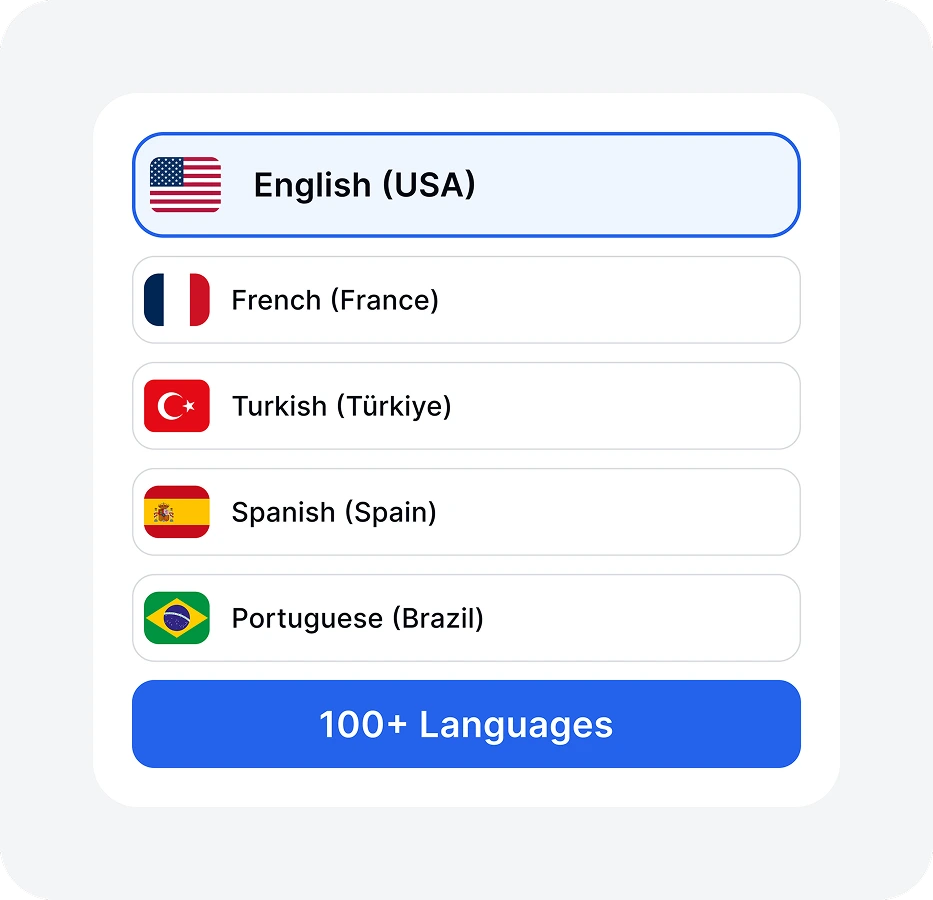
Choose from over 100 languages. Our AI transcription engine supports diverse dialects to ensure maximum accuracy for your specific file.
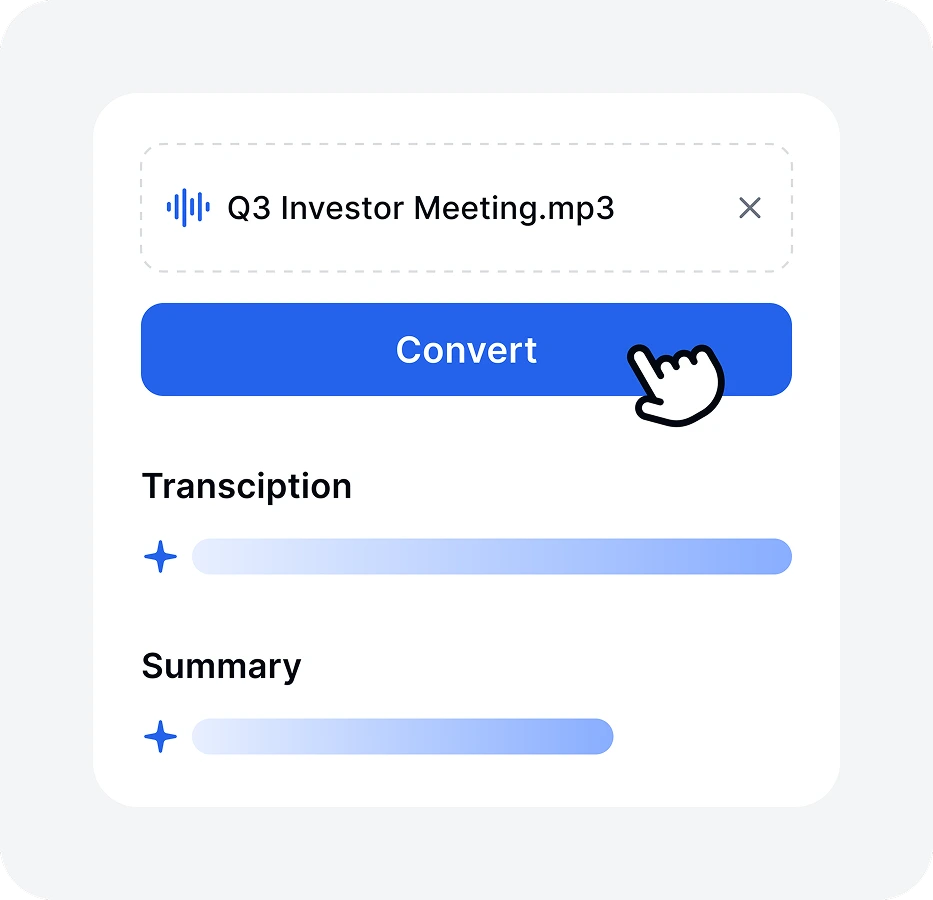
Click the button and let our software convert speech to text. Most transcriptions are completed in seconds.
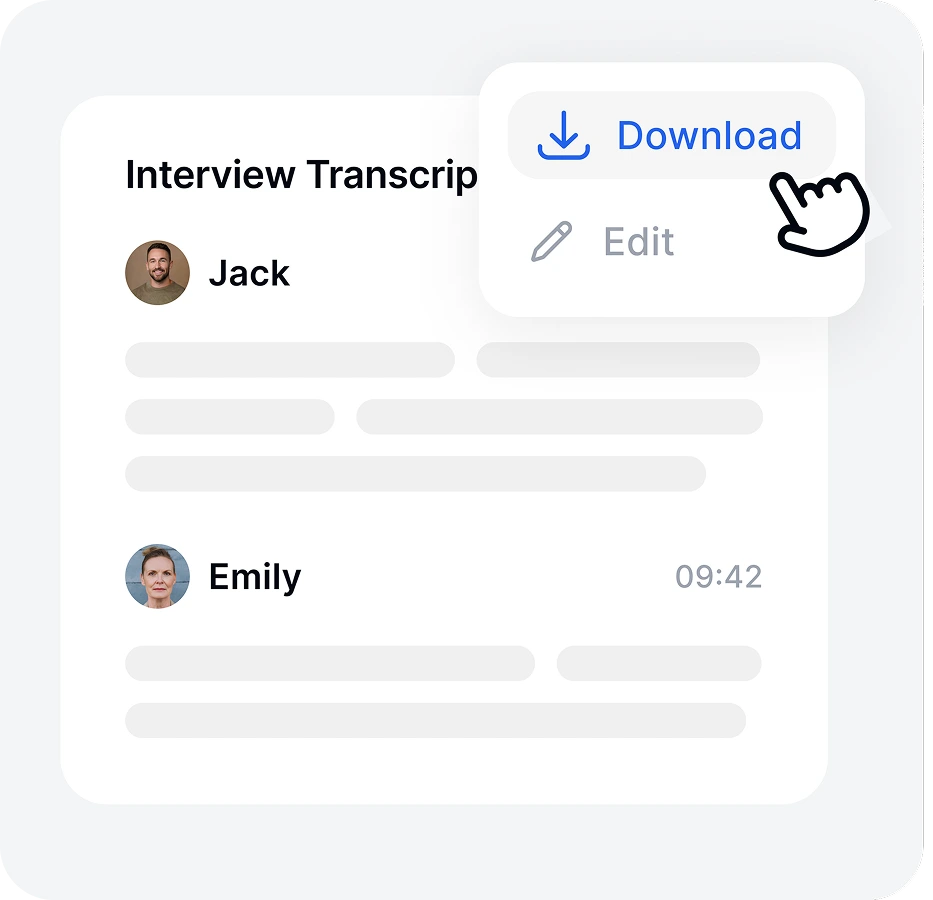
Review your text in our online editor, then export your transcript in multiple formats, including TXT, Word, or SRT for subtitles.

Stop wasting hours on manual transcription. Our advanced speech to text engine uses cutting-edge machine learning to deliver up to 99% accuracy. Whether you have a recording with multiple speakers or technical jargon, our software filters out background noise to ensure your speech to text conversion is precise and professional.
Stop scrolling through pages of text. Our AI speech to text tool doesn't just transcribe; it understands. Instantly generate a concise AI summary of your long videos, interviews, or lectures to capture the key takeaways in seconds. Need a specific answer? Use our AI Chat feature to ask questions directly to your transcript like “What was the project deadline?” and get immediate answers without reading the whole file.
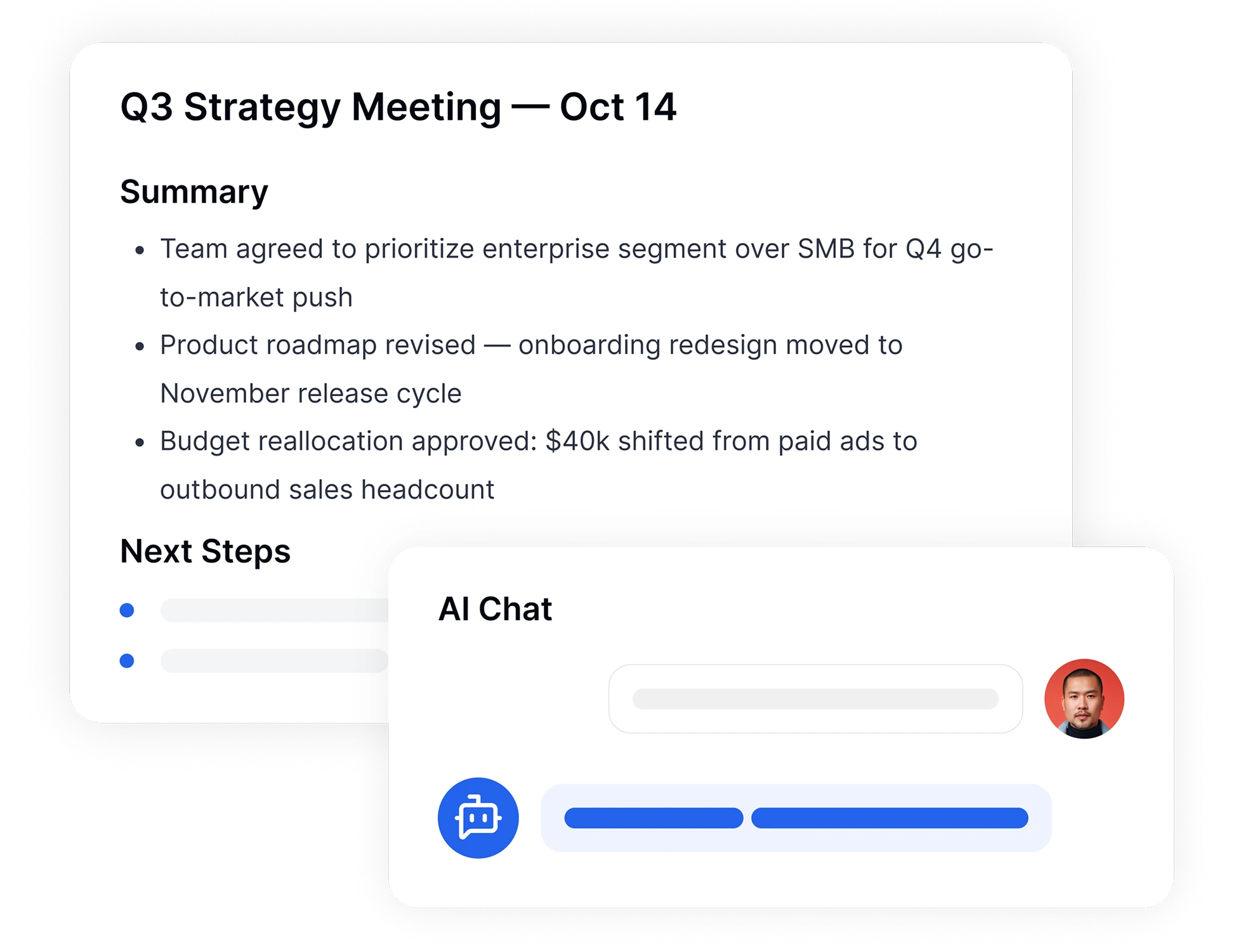
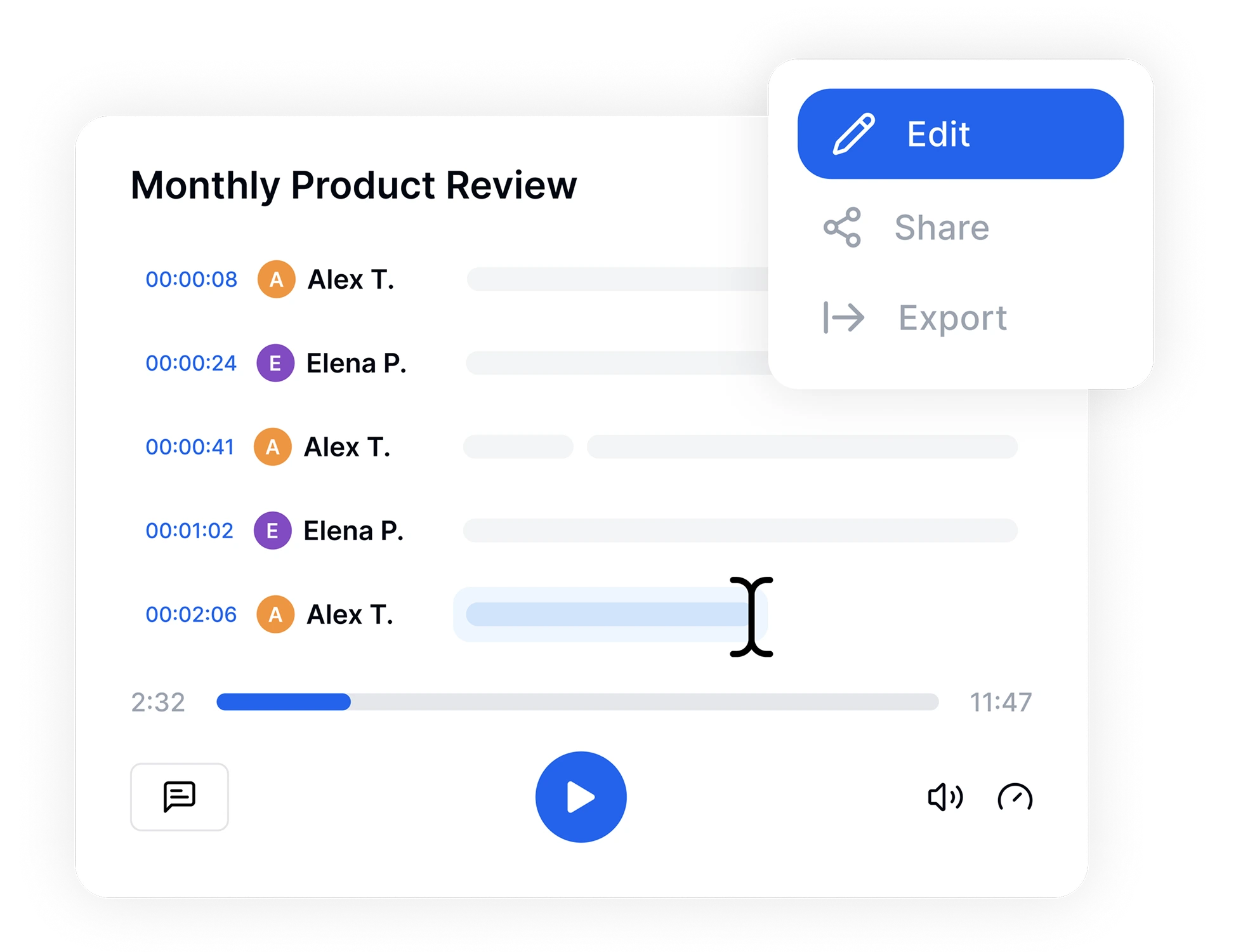
Once your transcription is ready, use our intuitive online editor to make quick adjustments. Highlight key moments, add speaker labels, and search through your text. When you're finished, export your file in your preferred format—TXT, PDF, Word, or SRT for video subtitles—and share it with your team instantly.
Explore other tools to convert audio or video files to text
I've tried several transcription services, but nothing beats this. The accuracy is near-perfect, and it saves me hours every week. It's become an essential part of my daily workflow for meeting notes.

Sarah K.
Senior Project Manager
Generating video transcripts for my YouTube channel used to take me all day. Now, I just paste the link and get a full text file in minutes. The SRT export makes subtitles a breeze!

Marcus A.
Digital Content Creator
You can convert speech to text by uploading your audio or video file directly to our platform. Many tools, including Transkriptor, offer a free trial that allows you to test the AI transcription accuracy and speed before committing to a plan. Simply click "Upload" to get started.
The most accurate software uses advanced AI and machine learning algorithms to reach up to 99% accuracy. For the best results, ensure your audio is clear and has minimal background noise. Our automatic transcription engine is designed to handle different accents and technical terminology across 100+ languages.
Yes! You can easily convert YouTube to text or transcribe videos from Google Drive and Dropbox. Just paste the URL into the "Convert from URL" box, and our tool will fetch the audio and generate a video transcript in minutes.
Our speech to text converter supports all major audio and video formats, including MP3, MP4, WAV, AAC, and M4A. Once the transcription is complete, you can export your text in formats like TXT, Word, or SRT for subtitles.
With our high-speed AI transcription, it typically takes less than 5 minutes to transcribe 1 hour of audio. This is significantly faster than manual transcription, which can take up to 4 hours for the same amount of content.
Absolutely. We support speech to text in over 100 languages, including English, Spanish, French, German, Portuguese, Turkish and Arabic. Our tool automatically detects the language and provides a localized transcript with high precision.