Crea il Tuo Account & Registra o Carica un File
Crea il tuo account Transkriptor e inizia con l'accesso gratuito alla trascrizione. Registra o carica il tuo audio/video per iniziare a trascrivere istantaneamente.
Carica per convertire audio o video in testo
Trascrivi file MP3Clicca per caricare e trascrivere gratuitamente
Registra audio o video e trascrivi gratuitamente
Fidato da individui presso

Convertire audio in testo con l'estensione Chrome trascrizione #1 valutata. Registra istantaneamente il tuo schermo, la tua fotocamera o il tuo microfono e ottieni trascrizioni vocali accurate direttamente dal tuo browser.
Transkriptor è riconosciuto come uno dei migliori software di trascrizione audio, fidato da migliaia di utenti in tutto il mondo. Scopri perché le persone ci scelgono come il loro miglior strumento di trascrizione audio.
Uso Transkriptor da mesi e la precisione è costantemente del 98-99%, anche con termini tecnici. Supporta più lingue, tra cui inglese, svedese e tedesco. Convertire lunghe registrazioni in testo è ora molto più veloce ed efficiente.

Lena Kaur
Specialista di Marketing Digitale
Imparare a trascrivere audio in testo è semplice con Transkriptor. Segui il nostro processo passo-passo per convertire qualsiasi registrazione come riunioni, lezioni, interviste o note vocali in testo preciso e modificabile in pochi secondi.
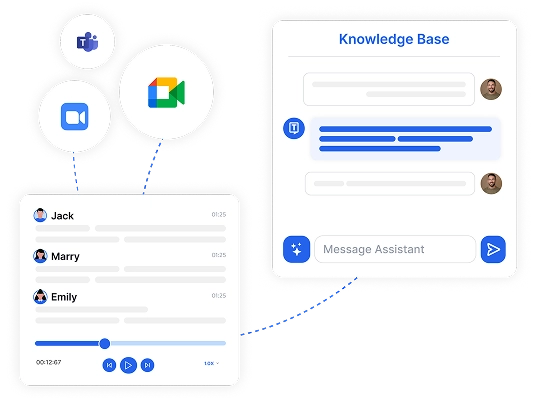
Cerchi di trascrivere audio in testo per il tuo settore? Transkriptor offre funzionalità di trascrizione specifiche per settore, progettate per team legali, operatori sanitari, psicologi, consulenti, manager IT e professionisti dei media.

Software di dettatura medica sicuro e accurato progettato per i professionisti sanitari. Trasforma le interazioni con i pazienti in trascrizioni cliniche organizzate istantaneamente.

Trasforma le riunioni con i clienti in trascrizioni aziendali organizzate e ricercabili con la trascrizione per consulenti. Ottieni intuizioni trascritte istantanee, risultati chiave e analisi della trascrizione AI per migliori risultati con i clienti.

Concentrati completamente sui tuoi clienti mentre Transkriptor agisce come il tuo trascrittore per le sessioni di terapia. Ottieni note organizzate delle sessioni, monitoraggio dei progressi e documentazione sicura automaticamente.

Trasforma le riunioni con i clienti in trascrizioni ricercabili con la trascrizione legale. Accedi a registrazioni istantanee delle discussioni mantenendo la riservatezza.

Trascrizione media veloce e accurata per trasmissioni e produzione di contenuti. Converti audio in testo istantaneamente, con supporto per più formati e lingue.
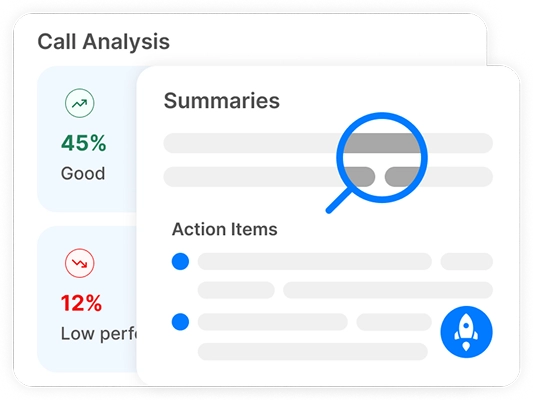
Trasforma ogni riunione in intuizioni attuabili con trascrizioni, riassunti e analisi potenziati dall'AI.
Transkriptor dà priorità alla sicurezza e alla privacy a ogni livello. La nostra piattaforma di trascrizione di livello aziendale è conforme agli standard SOC 2, GDPR, ISO 27001 e SSL per garantire che i tuoi dati audio e video siano completamente protetti e trascritti in modo sicuro.





La trascrizione è il processo di convertire il linguaggio parlato da registrazioni audio o video in testo scritto. È ampiamente utilizzata per riunioni, interviste, conferenze, podcast e contenuti multimediali. La trascrizione può essere effettuata manualmente da trascrittori umani o automaticamente utilizzando software di trascrizione AI.
La trascrizione funziona convertendo le parole pronunciate da audio o video in testo scritto. Carichi un file su uno strumento come Transkriptor, che utilizza l'AI per rilevare il parlato, identificare i relatori e generare una trascrizione con timestamp. Puoi quindi rivedere e modificare il testo ed esportarlo in formati come TXT, DOCX o sottotitoli (SRT/VTT).
I vantaggi della trascrizione includono una migliore accessibilità, una maggiore ricercabilità dei contenuti e un aumento della produttività. Trasforma i contenuti parlati in testo scritto facile da leggere e riutilizzare. La trascrizione supporta anche la SEO creando contenuti indicizzabili. Gli strumenti di trascrizione AI come Transkriptor automatizzano il processo, risparmiando tempo e risorse.
L'accuratezza della trascrizione è influenzata da diversi fattori, tra cui la qualità audio, il rumore di fondo, la chiarezza del parlato, dialoghi sovrapposti, accenti e il numero di relatori. Audio registrati male o accenti forti possono ridurre l'efficacia degli strumenti di trascrizione AI. Microfoni di alta qualità, parlato chiaro e interruzioni minime migliorano i risultati.
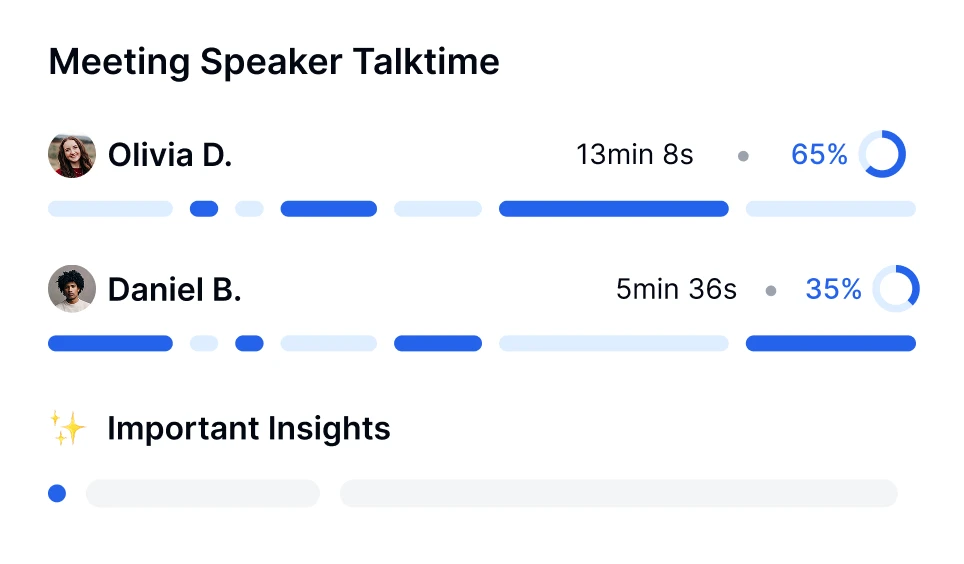
Sì, i moderni strumenti di trascrizione come Transkriptor possono gestire più relatori utilizzando la tecnologia di diarizzazione dei relatori. Questa funzione identifica e etichetta ogni relatore nella trascrizione, facilitando il seguire le conversazioni in riunioni, interviste o discussioni di gruppo.
Il miglior software di trascrizione è Transkriptor. Offre una trascrizione AI altamente accurata con un'accuratezza fino al 99%. Transkriptor supporta oltre 100 lingue, consente agli utenti di caricare file audio o video in vari formati e include funzionalità come l'identificazione dei relatori, la generazione di sottotitoli e un editor di trascrizioni integrato. Altri strumenti di trascrizione popolari includono Otter.ai e Fireflies.ai, che offrono anche servizi di trascrizione basati su AI. Tuttavia, Transkriptor è preferito per la sua copertura linguistica più ampia, prezzi convenienti e funzionalità di editing semplificate che supportano sia gli utenti occasionali che i professionisti.
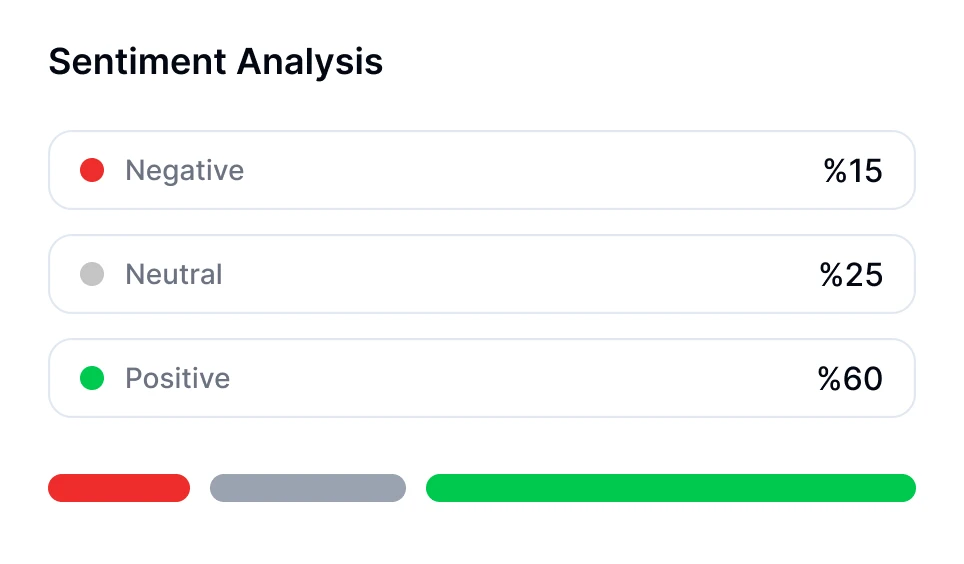
Puoi effettuare l'analisi del sentiment per le conversazioni utilizzando strumenti basati su AI come Transkriptor. Il bot per riunioni di Transkriptor può unirsi direttamente alle tue riunioni online o analizzare le registrazioni caricate. Dopo la trascrizione, valuta automaticamente il tono emotivo della conversazione, classificando i segmenti come positivi, neutrali o negativi.
Il miglior convertitore da audio a testo è Transkriptor. Utilizza AI avanzata per convertire accuratamente l'audio parlato in testo scritto in pochi secondi. Transkriptor supporta formati audio popolari come MP3, WAV e M4A e funziona in oltre 100 lingue.
Il miglior strumento gratuito per la trascrizione è Transkriptor. Fornisce servizi di trascrizione altamente accurati e basati su AI anche nel suo piano gratuito. Con l'opzione di trascrizione gratuita di Transkriptor, puoi trascrivere fino a 30 minuti di audio al giorno.
La conversione da video a testo è il processo di trasformare automaticamente le parole pronunciate in un video in testo scritto utilizzando la tecnologia di riconoscimento vocale alimentata dall'IA.
Transkriptor è uno dei migliori strumenti per trascrivere video in testo, offrendo una rapida elaborazione, alta precisione e supporto per più lingue e formati.
Sì, puoi convertire automaticamente video in testo utilizzando strumenti di trascrizione basati su IA come Transkriptor, eliminando la necessità di digitazione manuale.
Sì, convertire video in testo migliora la SEO rendendo i contenuti video ricercabili, indicizzabili e accessibili ai motori di ricerca.
Gli strumenti da video a testo sono ideali per creatori di contenuti, educatori, giornalisti, marketer, studenti e aziende che necessitano di trascrizioni rapide.
Sì, la conversione da video a testo migliora l'accessibilità fornendo trascrizioni leggibili per utenti con problemi di udito e un pubblico più ampio.
L'IA analizza i modelli di linguaggio, i segnali audio e il contesto linguistico per convertire con precisione le parole pronunciate nei video in testo.
Transkriptor offre una trascrizione da video a testo veloce, precisa, sicura ed economica, con potenti strumenti di IA e un'interfaccia intuitiva.