Pengguna dapat secara efektif memanfaatkan konverter ucapan-ke-teks untuk merampingkan alur kerja mereka, menghemat waktu, dan mencapai lebih banyak dalam upaya profesional dan pribadi mereka dengan mendapatkan wawasan tentang teknologi dan fungsionalitas yang mendasarinya, termasuk aplikasi seluler Transkriptor . Memahami cara kerja konverter ucapan ke teks sangat penting bagi semua pengguna yang ingin meningkatkan produktivitas mereka.
Transkriptor mendukung teknologi ini dengan menawarkan layanan konversi ucapan-ke-teks yang sangat efisien dan ramah pengguna, memberikan kekuatan AI canggih untuk memberikan transkripsi yang akurat, menjadikannya alat penting untuk strategi transkripsi pemasaran konten yang memerlukan konversi konten lisan menjadi materi tertulis yang menarik. Baik itu untuk pertemuan bisnis, penelitian akademis, atau catatan pribadi, Transkriptor memberikan pengalaman unik, memastikan bahwa setiap Word yang diucapkan ditangkap dan diubah menjadi teks dengan presisi.
Bagaimana Cara Kerja Konversi Ucapan ke Teks?
Pengguna berbicara ke mikrofon yang terhubung ke perangkat atau aplikasi dalam konverter ucapan-ke-teks untuk memulai transkripsi. Setelah ini, konverter menggunakan algoritma canggih dan teknik pembelajaran mesin untuk menganalisis pola bicara dan mengubahnya menjadi teks tertulis. Proses ini melibatkan memecah pidato menjadi unit-unit yang lebih kecil, mengidentifikasi fonem, dan kemudian mencocokkannya dengan kata-kata dalam kosa katanya.
Selain itu, konverter terus belajar dari interaksinya, meningkatkan akurasinya dari waktu ke waktu. Pengguna dapat menyesuaikan pengaturan untuk meningkatkan akurasi, seperti preferensi bahasa dan peredam bising. Mereka dapat mengedit dan memformat teks sesuai kebutuhan setelah pidato ditranskripsikan.
Teknologi ini banyak digunakan dalam berbagai aplikasi, termasuk asisten virtual, layanan transkripsi , dan alat aksesibilitas, menawarkan cara yang efisien dan nyaman untuk mengubah kata-kata yang diucapkan menjadi teks tertulis.
Apa Teknologi Utama di Balik Konversi Ucapan-ke-Teks
Pengguna mengandalkan beberapa teknologi utama untuk konversi ucapan-ke-teks.
- Automatic Speech Recognition (ASR): Ini memainkan peran penting dalam menguraikan kata-kata yang diucapkan menjadi teks dengan menganalisis sinyal audio Selain itu, Natural Language Processing (NLP) meningkatkan akurasi transkripsi dengan menafsirkan nuansa dan konteks linguistik Algoritme Pembelajaran Mesin memungkinkan konverter ucapan-ke-teks untuk terus meningkatkan kinerjanya berdasarkan interaksi dan umpan balik pengguna, menyempurnakan akurasi transkripsi.
- Artificial Intelligence (AI): Ini mengintegrasikan teknologi ini, memungkinkan konverter untuk beradaptasi dengan aksen, bahasa, dan pola bicara yang berbeda Melalui AI, konverter belajar dari kumpulan data yang luas untuk mengenali dan mentranskripsikan ucapan dengan presisi yang meningkat.
Teknologi ini bekerja secara sinergis, memungkinkan pengguna untuk dengan mudah mengubah kata-kata yang diucapkan menjadi teks tertulis di berbagai aplikasi dan platform seperti Transkriptor, merevolusi komunikasi dan aksesibilitas di era digital.
Apa Aplikasi Konversi Ucapan ke Teks?
Konversi ucapan-ke-teks telah menjadi bagian integral dari banyak aspek kehidupan modern. Ini digunakan dalam berbagai cara, dan memahami di mana letak informasi penting sangat penting.
Layanan transkripsi
Layanan transkripsi memanfaatkan teknologi konversi ucapan ke teks untuk mengubah audio lisan menjadi teks tertulis secara efisien. Editor mendapat manfaat dari layanan transkripsi dalam berbagai skenario, seperti wawancara, rapat, ceramah, dan dikte.
Layanan ini menawarkan kepada pengguna kenyamanan menyalin konten audio dalam volume besar dengan cepat dan akurat, menghemat waktu dan tenaga. Profesional seperti jurnalis , peneliti, dan mahasiswa mengandalkan layanan transkripsi untuk membuat catatan tertulis wawancara, ceramah, dan temuan penelitian.
Bisnis menggunakan layanan transkripsi untuk menghasilkan transkrip tertulis rapat, konferensi, dan interaksi pelanggan untuk dokumentasi dan analisis.
Teknologi bantu untuk penyandang cacat
Teknologi bantuan untuk penyandang disabilitas memanfaatkan konversi ucapan ke teks untuk meningkatkan aksesibilitas dan kemandirian bagi pengguna penyandang disabilitas.
Individu dengan gangguan motorik, seperti kelumpuhan atau ketangkasan terbatas, dapat memanfaatkan konverter ucapan-ke-teks untuk mengoperasikan komputer, smartphone, dan perangkat lain secara handsfree. Teknologi ini memungkinkan editor untuk menulis email, menjelajah internet, dan berinteraksi dengan antarmuka digital menggunakan perintah suara.
Selain itu, konversi ucapan-ke-teks memfasilitasi komunikasi bagi individu dengan gangguan pendengaran dengan menyalin kata-kata yang diucapkan menjadi teks tertulis secara real time. Pengguna dapat terlibat dalam percakapan, berpartisipasi dalam rapat, dan mengakses konten audio dengan lebih mudah.
Sistem yang dikendalikan suara dan asisten virtual
Sistem yang dikendalikan suara dan asisten virtual menggunakan konversi ucapan-ke-teks untuk memungkinkan pengguna berinteraksi dengan perangkat dan aplikasi menggunakan perintah bahasa alami. Pengguna dapat melakukan berbagai tugas secara handsfree, seperti mengatur pengingat, mengirim pesan, atau mengendalikan perangkat rumah SMART hanya dengan berbicara dengan keras.
Asisten virtual seperti Siri, Alexa, dan Google Assistant memanfaatkan teknologi ucapan-ke-teks untuk memahami perintah pengguna, memprosesnya, dan memberikan respons atau tindakan yang relevan. Sistem ini meningkatkan kenyamanan dan produktivitas pengguna dengan menghilangkan kebutuhan untuk input manual dan menyederhanakan tugas melalui interaksi suara.
Editor dapat mengakses informasi, mengatur jadwal mereka, dan mengendalikan lingkungan mereka dengan lebih efisien, baik di rumah, di mobil, atau di perjalanan.
Selain itu, aplikasi lain dari konversi ucapan-ke-teks adalah bahwa Transkriptor terintegrasi dengan mulus dengan platform seperti Google Meet dan Zoom, memungkinkan pengguna untuk menyalin rapat secara langsung, meningkatkan aksesibilitas, dan memfasilitasi pencatatan yang efisien selama pertemuan virtual.
Layanan komunikasi dan terjemahan real-time
Layanan komunikasi dan terjemahan real-time menggunakan konversi ucapan-ke-teks untuk memfasilitasi interaksi tanpa batas antara pengguna yang berbicara dalam berbagai bahasa.
Pengguna dapat terlibat dalam percakapan langsung, baik secara langsung atau jarak jauh, dengan bantuan teknologi ucapan-ke-teks yang mentranskripsikan kata-kata yang diucapkan menjadi teks tertulis secara real time. Hal ini memungkinkan individu WHO berbicara bahasa yang berbeda untuk berkomunikasi secara efektif tanpa memerlukan penerjemah manusia.
Selain itu, layanan terjemahan memanfaatkan konversi ucapan-ke-teks untuk menerjemahkan kata-kata yang diucapkan ke dalam teks tertulis dan kemudian ke dalam bahasa yang diinginkan, memungkinkan editor untuk memahami dan menanggapi pesan dalam bahasa pilihan mereka.
Apa Manfaat Teknologi Ucapan-ke-Teks?
Mengadopsi teknologi ucapan-ke-teks memberdayakan pengguna dengan cara yang nyaman, efisien, dan inklusif untuk mengubah bahasa lisan menjadi teks tertulis, merevolusi cara kita berinteraksi dengan perangkat dan informasi digital. Ini menawarkan sejumlah besar keuntungan bagi pengguna di berbagai domain.
1 Peningkatan aksesibilitas dan inklusivitas
Teknologi ucapan-ke-teks menawarkan peningkatan aksesibilitas dan inklusivitas bagi pengguna dengan berbagai kebutuhan dan preferensi. Individu dengan gangguan pendengaran dapat mengakses informasi lisan melalui transkripsi teks , memungkinkan mereka untuk berpartisipasi penuh dalam percakapan, ceramah, dan interaksi verbal lainnya. Pengguna dengan cacat motorik dapat menavigasi antarmuka digital handsfree, menggunakan perintah suara untuk tugas-tugas seperti mengetik, browsing, dan mengoperasikan perangkat.
Selain itu, teknologi ucapan-ke-teks memecah hambatan bahasa, memungkinkan pengguna untuk berkomunikasi dan mengakses informasi dalam bahasa pilihan mereka, terlepas dari perbedaan linguistik.
Selain itu, ini meningkatkan pengalaman belajar dengan menyediakan teks, subtitle , dan transkrip untuk video dan ceramah pendidikan, melayani beragam gaya belajar dan kebutuhan aksesibilitas.
2 Peningkatan produktivitas dan efisiensi
Teknologi ucapan ke teks secara signifikan meningkatkan produktivitas dan efisiensi di berbagai sektor.
Wartawan mentranskripsikan wawancara dan mendikte artikel dengan cepat, dengan mudah memenuhi tenggat waktu yang ketat. Profesional hukum mendikte catatan kasus dan dokumen, mengurangi waktu yang dihabiskan untuk transkripsi manual dan meningkatkan fokus pada kebutuhan klien.
Dokter secara efisien mendikte catatan pasien selama pemeriksaan, meningkatkan akurasi dokumentasi dan membebaskan lebih banyak waktu untuk perawatan pasien. Karyawan mendikte email, laporan, dan memo di lingkungan perusahaan, menyederhanakan komunikasi dan proses manajemen tugas.
3 Peningkatan akurasi dan analisis data
Kemajuan dalam teknologi ucapan-ke-teks secara signifikan meningkatkan akurasi dan analisis data bagi pengguna di berbagai industri. Teknologi ini meminimalkan kesalahan yang dapat terjadi melalui entri data manual dengan menyalin kata-kata yang diucapkan secara akurat ke dalam teks tertulis.
Editor dapat mengandalkan transkripsi yang tepat untuk dokumentasi penting, seperti notulen rapat, wawancara, dan catatan medis, memastikan integritas data dan kepatuhan terhadap standar peraturan.
Selain itu, teknologi ucapan-ke-teks memfasilitasi analisis data audio dalam volume besar dengan mengubahnya menjadi format teks yang dapat dicari dan dianalisis. Peneliti, analis, dan bisnis memanfaatkan kemampuan ini untuk mengekstrak wawasan, mengidentifikasi pola, dan membuat keputusan berdasarkan data dengan lebih efisien.
Selain itu, integrasi dengan algoritma Natural Language Processing dan pembelajaran mesin semakin meningkatkan kemampuan analisis data, memungkinkan pengguna untuk mengungkap wawasan dan tren berharga dari konten lisan.
Apa Tantangan dalam Konversi Ucapan ke Teks?
Teknologi konversi ucapan-ke-teks juga menghadirkan beberapa tantangan kepada editor yang memengaruhi efektivitas dan keandalannya meskipun banyak manfaatnya. Memahami tantangan ini sangat penting bagi pengguna untuk menavigasi keterbatasan teknologi ini dan membuat keputusan berdasarkan informasi mengenai penggunaannya.
1 Berurusan dengan aksen dan dialek
Pengguna sering menghadapi tantangan dengan konversi ucapan-ke-teks ketika berhadapan dengan aksen dan dialek. Aksen sangat bervariasi di antara pembicara, menghadirkan kesulitan untuk sistem pengenalan suara dalam menyalin kata-kata yang diucapkan secara akurat. Pengguna dengan aksen atau dialek non-standar dapat mengalami akurasi transkripsi yang lebih rendah, yang menyebabkan kesalahan dalam teks yang dikonversi.
Selain itu, dialek regional dan istilah slang dapat mempersulit proses transkripsi lebih lanjut, karena sistem pengenalan suara berjuang untuk menafsirkan variasi linguistik yang tidak dikenal. Editor biasanya memilih konverter ucapan-ke-teks dengan fitur penyesuaian aksen dan dialek untuk mengurangi tantangan ini, memungkinkan sistem untuk beradaptasi dengan pola bicara tertentu.
Selain itu, kemajuan berkelanjutan dalam teknologi pengenalan suara bertujuan untuk meningkatkan akurasi di berbagai aksen dan dialek melalui pelatihan yang ditingkatkan dan algoritme pembelajaran mesin.
2 Masalah kebisingan latar belakang dan kualitas suara
Pengguna sering menghadapi masalah kebisingan latar belakang dan kualitas suara saat menggunakan teknologi konversi ucapan ke teks. Kebisingan latar belakang, seperti obrolan, musik, atau suara sekitar, dapat mengganggu keakuratan sistem pengenalan suara, yang menyebabkan kesalahan dalam teks yang ditranskripsikan.
Kualitas suara yang buruk, termasuk volume rendah, ucapan teredam, atau audio yang terdistorsi, semakin memperburuk tantangan ini karena algoritme pengenalan ucapan berjuang untuk menguraikan pola bicara yang tidak jelas atau tidak jelas. Editor dapat mengalami frustrasi dan penurunan akurasi transkripsi saat mencoba mengonversi ucapan di lingkungan yang bising atau dengan kondisi perekaman yang kurang optimal.
Pengguna dapat meminimalkan kebisingan latar belakang dengan memilih lingkungan yang tenang untuk input ucapan dan mengoptimalkan pengaturan mikrofon untuk kualitas suara yang lebih baik untuk mengatasi tantangan ini. Selain itu, konverter ucapan ke teks yang dilengkapi dengan fitur peredam bising membantu mengurangi dampak kebisingan latar belakang, meningkatkan akurasi transkripsi dan pengalaman pengguna secara keseluruhan.
3 Pemahaman kontekstual dan homofon
Pengguna sering menghadapi tantangan dengan pemahaman kontekstual dan homofon saat menggunakan teknologi konversi ucapan-ke-teks. Perangkat lunak pengenalan suara mampu berjuang untuk menafsirkan kata-kata yang diucapkan secara akurat tanpa konteks yang tepat, yang menyebabkan kesalahan dalam transkripsi.
Frasa ambigu atau homofon (kata-kata yang terdengar sama tetapi memiliki arti yang berbeda) menimbulkan kesulitan tertentu, karena konverter ucapan-ke-teks salah menafsirkan Word yang dimaksudkan berdasarkan konteksnya. Misalnya, membedakan antara "tulis" dan "benar" atau "mereka," "di sana," dan "mereka" menantang untuk sistem ini.
Editor perlu mengoreksi atau mengedit teks yang ditranskripsikan secara manual untuk memastikan keakuratan, terutama dalam konteks di mana bahasa yang tepat sangat penting, seperti pengaturan akademis atau profesional.
Kemajuan Natural Language Processing dan pembelajaran mesin yang berkelanjutan bertujuan untuk meningkatkan pemahaman kontekstual dan pengenalan homofon dalam konversi ucapan-ke-teks, meningkatkan akurasi transkripsi pengguna secara keseluruhan.
Bagaimana Cara Memilih Konverter Ucapan-ke-Teks?
Pengguna harus mempertimbangkan berbagai faktor untuk memastikannya memenuhi kebutuhan mereka saat memilih konverter ucapan-ke-teks. Akurasi adalah yang terpenting, karena editor mengandalkan konverter untuk mentranskripsikan ucapan dengan tepat. Kecepatan adalah aspek penting lainnya, terutama bagi pengguna yang membutuhkan transkripsi real-time.
Kompatibilitas dengan berbagai bahasa dan aksen memastikan fleksibilitas dan inklusivitas dalam komunikasi. Pengguna juga harus menilai kemudahan penggunaan dan kompatibilitas konverter dengan perangkat dan platform mereka.
Selain itu, mempertimbangkan fitur seperti tanda baca dan opsi pemformatan meningkatkan kegunaan konverter untuk tugas-tugas tertentu. Integrasi dengan aplikasi dan layanan lain juga penting untuk integrasi alur kerja yang mulus. Akhirnya, editor harus mengevaluasi langkah-langkah privasi dan keamanan konverter untuk melindungi informasi sensitif.
Bagaimana Mengkonversi File Ucapan ke Teks dengan Transkriptor?
Pengguna yang mencari metode mudah dan efisien untuk mengonversi file ucapan menjadi teks akan menemukan Transkriptor alat yang berharga. Dirancang dengan mempertimbangkan kenyamanan pengguna, Transkriptor menawarkan platform yang lugas dan intuitif untuk konversi ucapan-ke-teks yang akurat.
1 Tandatangan
Pengguna harus menavigasi ke situs web Transkriptordan menemukan halaman pendaftaran untuk mendaftar Transkriptor dan mengonversi file ucapan menjadi teks. Mereka akan diminta untuk memberikan informasi dasar pada halaman pendaftaran, seperti alamat email dan kata sandi yang diinginkan.
Setelah memasukkan informasi ini, editor harus mengklik tombol "Daftar" untuk melanjutkan. Setelah proses pendaftaran selesai, mereka harus masuk ke akun Transkriptor mereka dan mulai mengunggah file ucapan untuk konversi.
Selain itu, pengguna memiliki opsi untuk menyesuaikan pengaturan akun mereka, seperti preferensi bahasa atau nama pengguna dan email, agar sesuai dengan kebutuhan dan preferensi khusus mereka.
2 Unggah atau Rekam Ucapan
Pengguna harus masuk ke akun mereka dan menavigasi ke alat konversi ucapan untuk mengunggah atau merekam ucapan di Transkriptor. Dari sana, mereka dapat mengunggah file ucapan yang telah direkam sebelumnya dalam format umum seperti MP3, MP4, atau WAV atau memilih untuk merekam ucapan secara langsung menggunakan mikrofon perangkat mereka.
Editor hanya perlu mengklik tombol "Unggah" dan memilih file yang diinginkan dari komputer atau perangkat mereka untuk mengunggah file. Atau, mereka harus mengklik tombol "Rekam" untuk merekam ucapan secara real time.
Transkriptor kemudian akan memproses ucapan yang diunggah atau direkam dan mengubahnya menjadi teks tertulis menggunakan algoritme konversi ucapan-ke-teks tingkat lanjut.
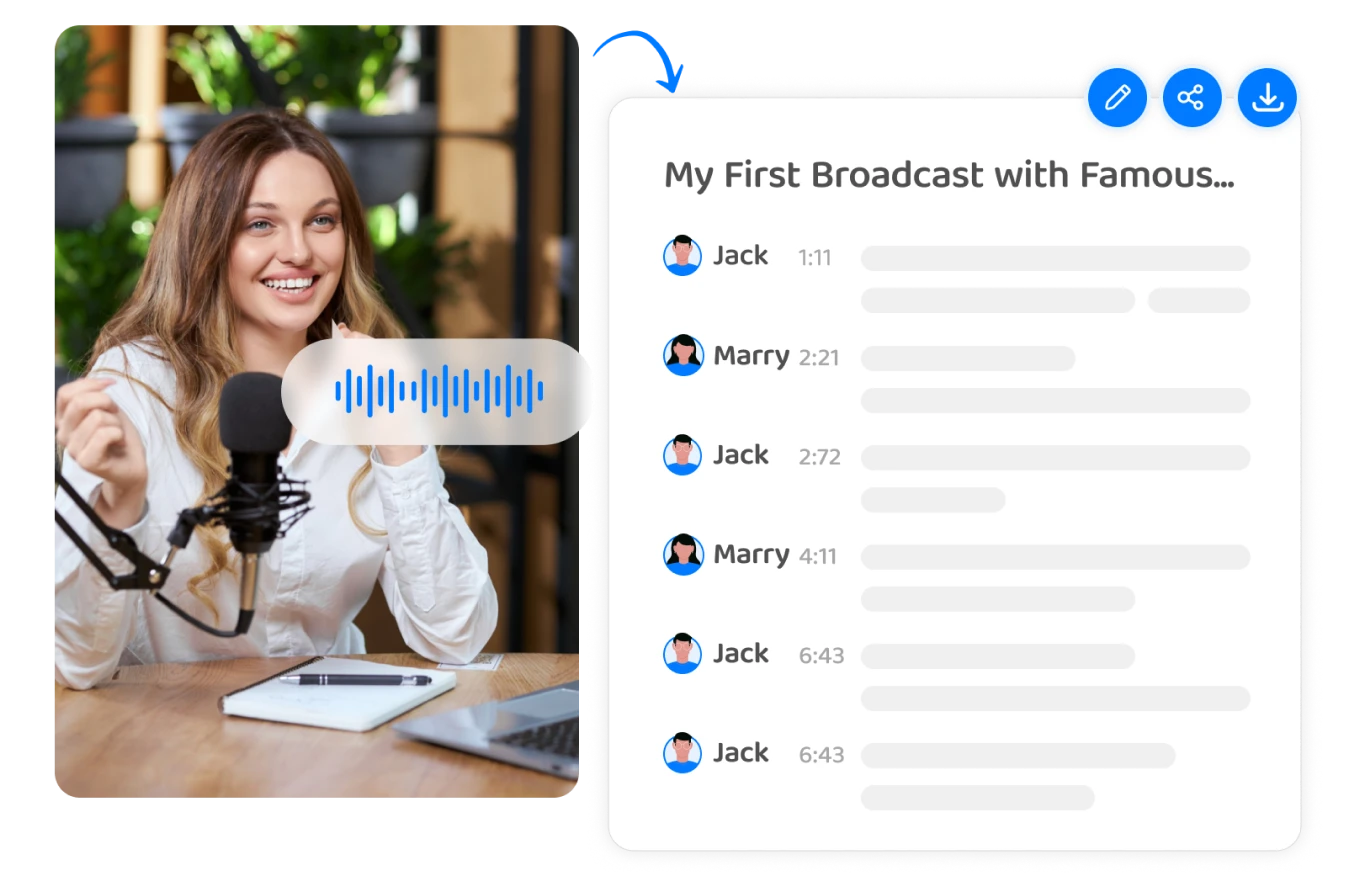
3 Edit, Unduh, atau Bagikan
Editor dapat dengan mudah mengedit, mengunduh, atau membagikan transkrip mereka setelah mengonversi ucapan menjadi teks dengan Transkriptor. Mereka akan menemukan opsi untuk mengedit teks yang ditranskripsikan langsung di dalam antarmuka Transkriptor , membuat koreksi atau penyesuaian yang diperlukan untuk akurasi.
Pengguna dapat mengunduhnya dalam berbagai format file seperti TXT, DOCx, atau SRT puas dengan transkrip, tergantung pada preferensi dan kebutuhan mereka.
Selain itu, mereka dapat membagikan transkrip dengan orang lain dengan membuat tautan yang dapat dibagikan dan mengirimkannya melalui email atau aplikasi perpesanan. Fitur ini memfasilitasi kolaborasi dan komunikasi di antara anggota tim atau pemangku kepentingan WHO membutuhkan akses ke konten yang ditranskripsikan.
Transkriptor memberdayakan pengguna untuk mengelola konten ucapan transkripsi mereka secara efisien sesuai dengan kebutuhan dan alur kerja mereka dengan menawarkan kemampuan pengeditan, pengunduhan, dan berbagi yang mulus.