Analiza Sentymentu Wspierana przez AI
Analiza sentymentu Transkriptora oparta na sztucznej inteligencji przekształca Twoje nagrania audio w szczegółowe spostrzeżenia emocjonalne. Dokładnie wykrywaj czas mówienia, ton, emocje i intencje rozmówców w rozmowach z klientami, spotkaniach online i wywiadach, automatycznie konwertując mowę na tekst i wydobywając dane o sentymencie głosu za pomocą zaawansowanej transkrypcji i analizy sentymentu opartej na sztucznej inteligencji.
Transkrybuj i analizuj sentyment w ponad 100 językach
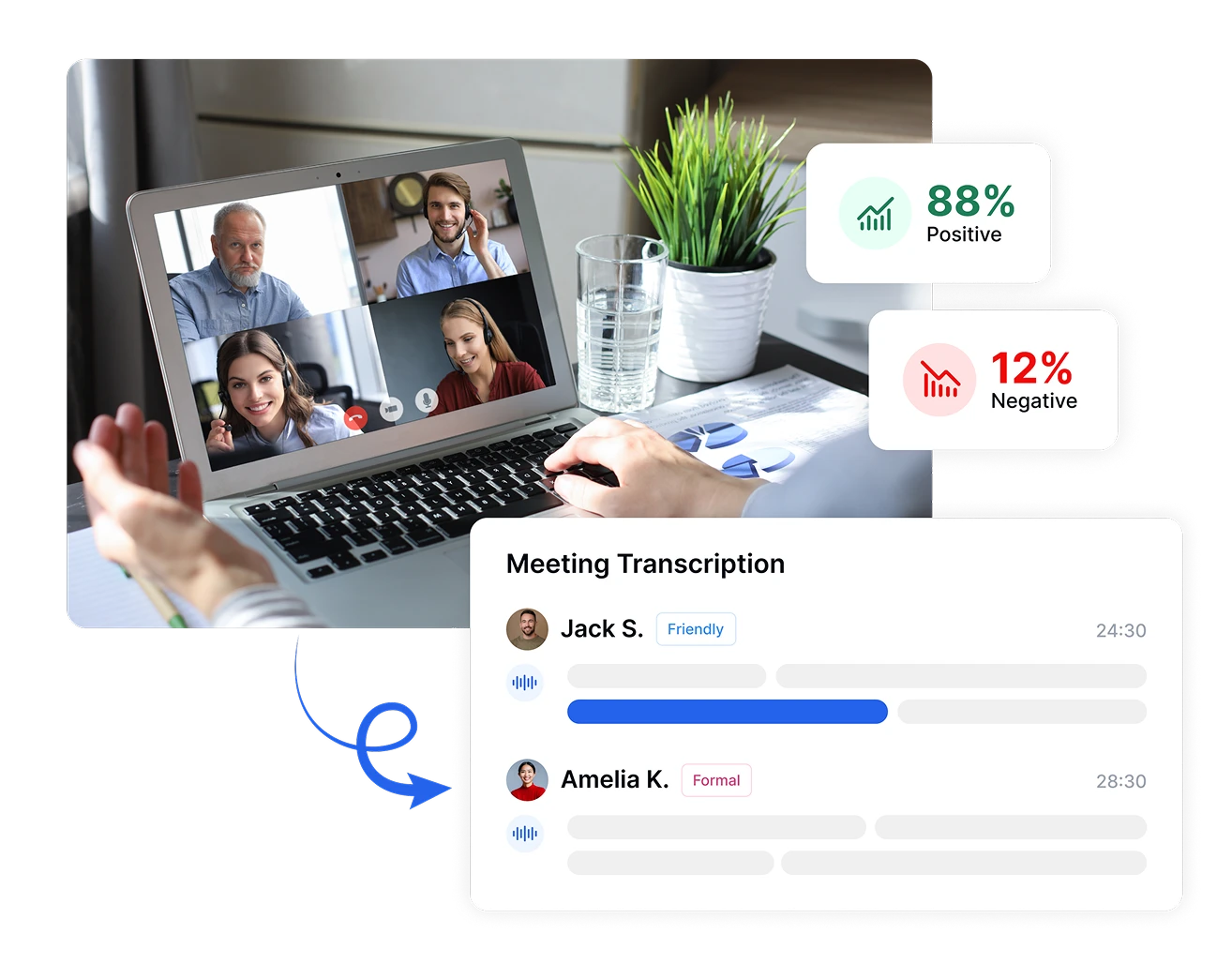
Podejmuj Decyzje Oparte na Danych dzięki Analizie Sentymentu
Przekształć subiektywne reakcje emocjonalne w obiektywne wskaźniki z Transkriptorem. Mierz intensywność sentymentu, śledź zmiany emocjonalne podczas rozmów i porównuj sentyment w różnych okresach lub segmentach klientów. Te precyzyjne pomiary przekształcają abstrakcyjne uczucia w konkretne punkty danych, umożliwiając podejmowanie decyzji opartych na dowodach, które poprawiają satysfakcję klientów i wyniki biznesowe.

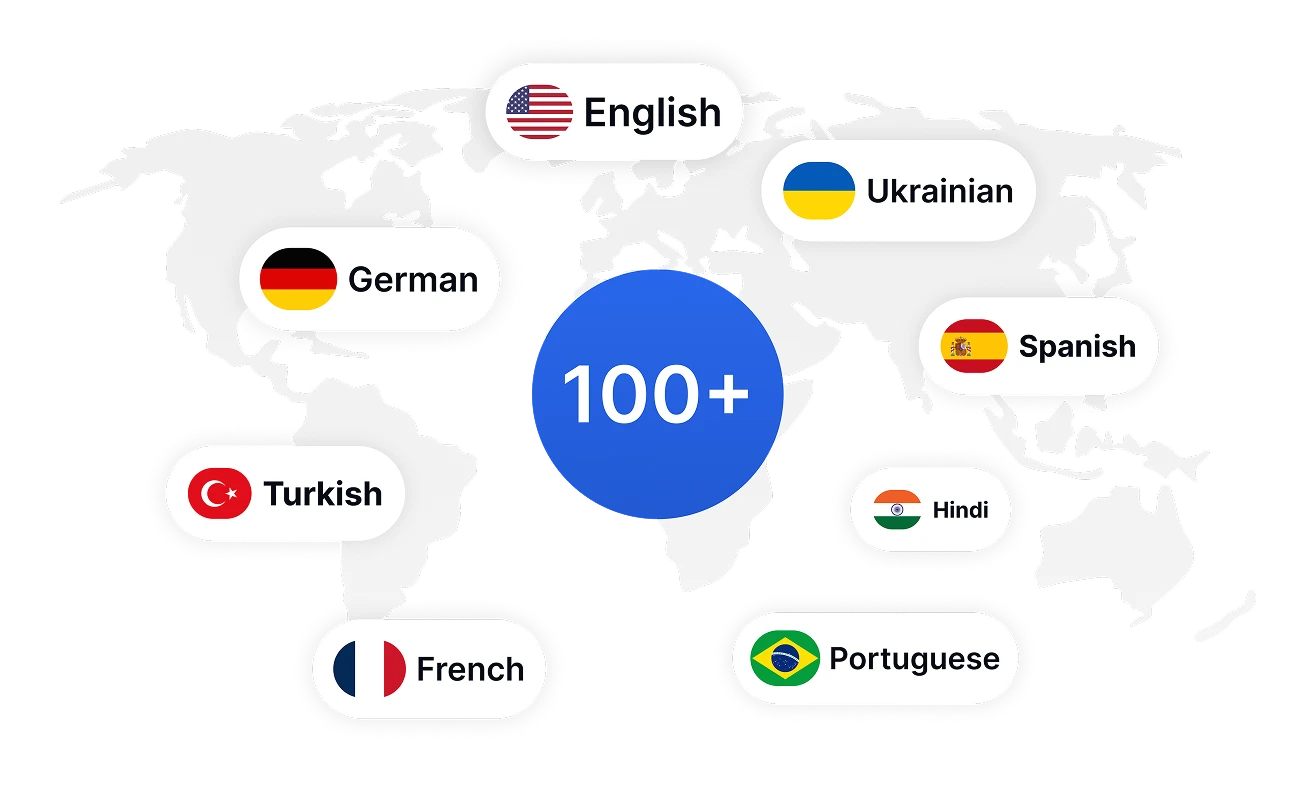
Analizuj Sentyment Głosu w Ponad 100 Językach
Przełam bariery językowe dzięki wielojęzycznym możliwościom analizy sentymentu Transkriptora. Wykrywaj niuanse emocjonalne w ponad 100 językach, umożliwiając globalnym zespołom zrozumienie sentymentu klientów niezależnie od regionu czy języka. To kompleksowe pokrycie językowe zapewnia spójne śledzenie sentymentu na międzynarodowych rynkach z wysokim wskaźnikiem dokładności do 99%.
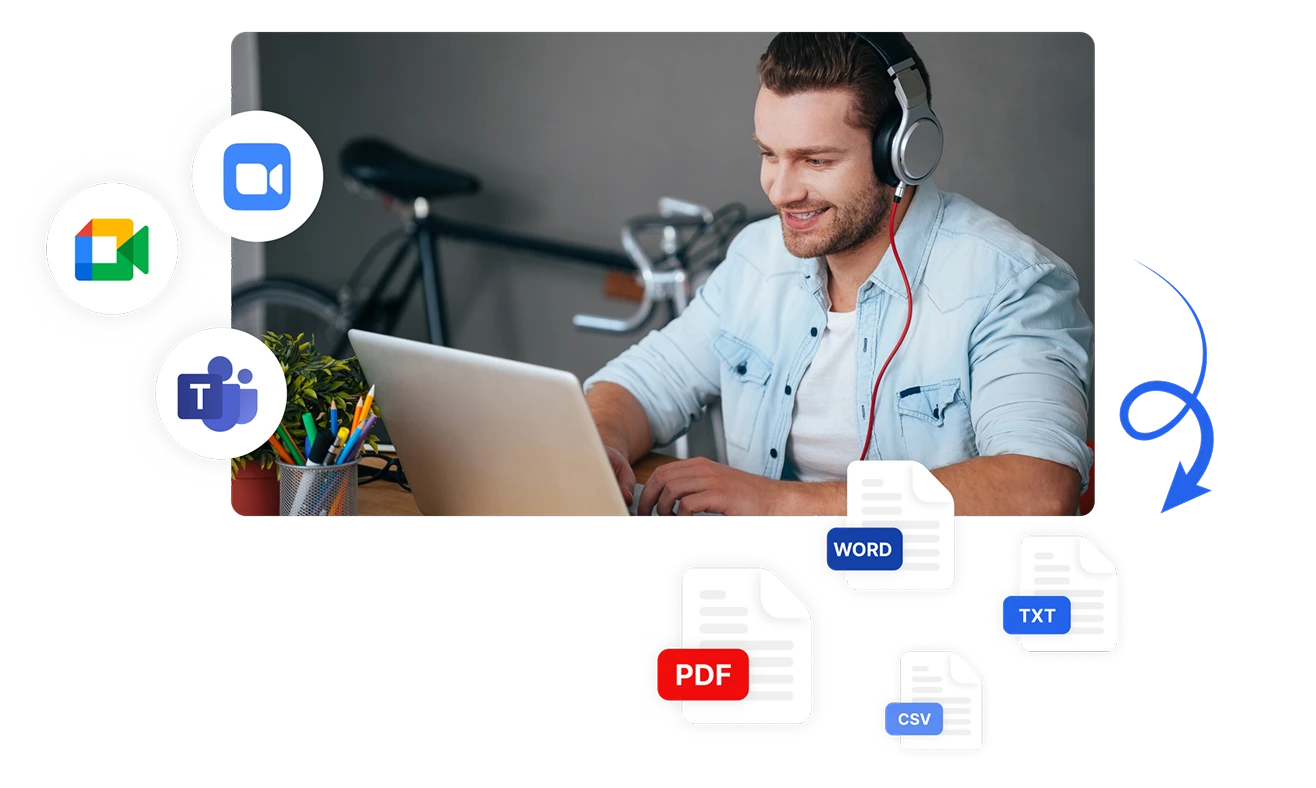
Przechwytuj i Analizuj Sentyment we Wszystkich Kanałach
Analizuj sentyment z wielu kanałów komunikacji dzięki wszechstronnym opcjom wprowadzania Transkriptora. Automatycznie transkrybuj i analizuj sentyment z przesłanych plików audio, bezpośrednio nagranych spotkań lub zintegrowanych platform, takich jak Zoom, Microsoft Teams i Google Meet. Eksportuj wyniki analizy sentymentu w formatach PDF, Word, TXT, CSV lub udostępniaj je natychmiast członkom zespołu.

Analizuj Sentyment Głosu w Zaledwie 4 Prostych Krokach
- 1KROK 1
Prześlij Swoje Audio lub Połącz Swoje Spotkanie
- 2KROK 2
Transkriptor Transkrybuje i Analizuje
- 3KROK 3
Przeglądaj Analizę Sentymentu
- 4KROK 4
Eksportuj lub Udostępniaj Spostrzeżenia Sentymentu
Kto Najbardziej Korzysta z Analizy Sentymentu Transkriptora

Zespół Obsługi Klienta
Śledź trendy zadowolenia klientów we wszystkich interakcjach serwisowych dzięki analizie sentymentu opartej na sztucznej inteligencji.

Specjaliści ds. Sprzedaży
Optymalizuj rozmowy sprzedażowe dzięki analizie sentymentu rozmów z potencjalnymi klientami, wspomaganej sztuczną inteligencją.

Specjaliści Prawni
Analizuj wzorce sentymentu w nagranych zeznaniach, wywiadach z klientami i oświadczeniach świadków.

Specjaliści HR
Udoskonalaj ocenę rozmów kwalifikacyjnych i sesje informacji zwrotnych dla pracowników dzięki obiektywnej analizie sentymentu.
All-in-One Sentiment Analysis Solution
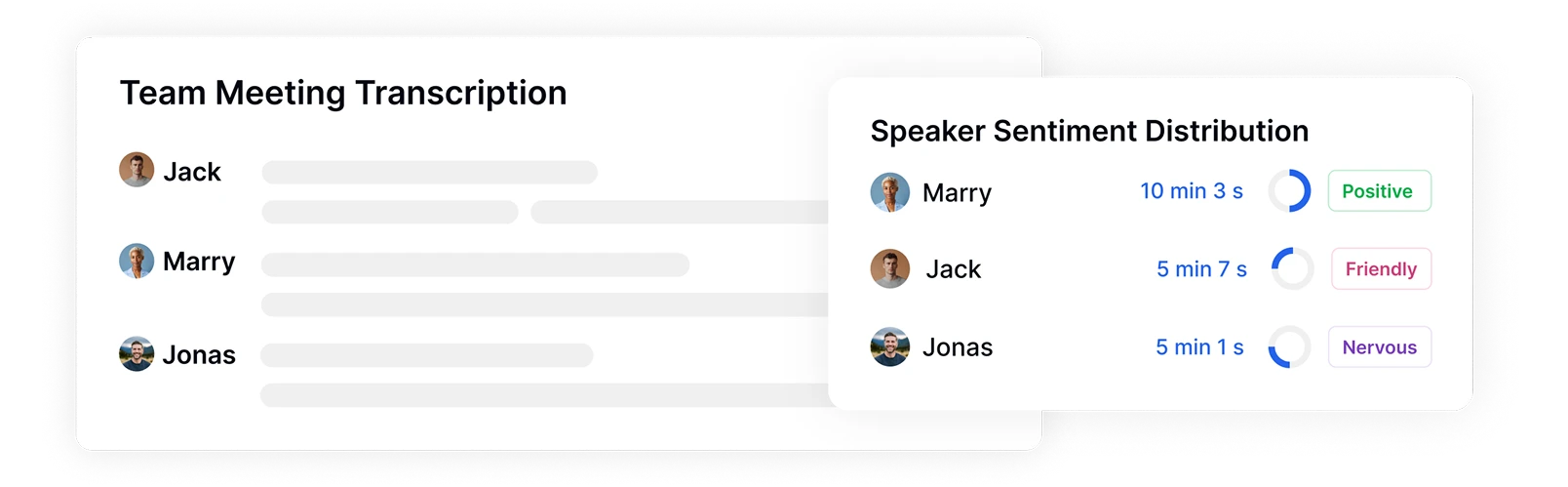
Identify Speakers and Track Sentiment Distribution
Transkriptor automatically identifies and tags different speakers in your recordings while measuring their talk time and emotional patterns. See exactly who spoke when, for how long, and with what sentiment, providing critical context for analyzing emotional dynamics between participants during meetings, interviews, or customer interactions.
Identify Speakers and Track Sentiment Distribution
Transkriptor automatically identifies and tags different speakers in your recordings while measuring their talk time and emotional patterns. See exactly who spoke when, for how long, and with what sentiment, providing critical context for analyzing emotional dynamics between participants during meetings, interviews, or customer interactions.

Generate AI-Powered Sentiment Summaries
Transform lengthy conversations into concise sentiment summaries with Transkriptor's AI technology. These summaries identify key sentiment shifts, and quantify overall emotional tone, providing a quick overview of the emotional journey throughout any recorded conversation.

Build Knowledge Bases with Sentiment Analysis
Organize essential emotional insights by creating custom knowledge bases using sentiment-analyzed transcripts. Store, categorize, and search through sentiment data to establish emotional benchmarks, identify recurring patterns, and build a comprehensive repository of emotional intelligence.
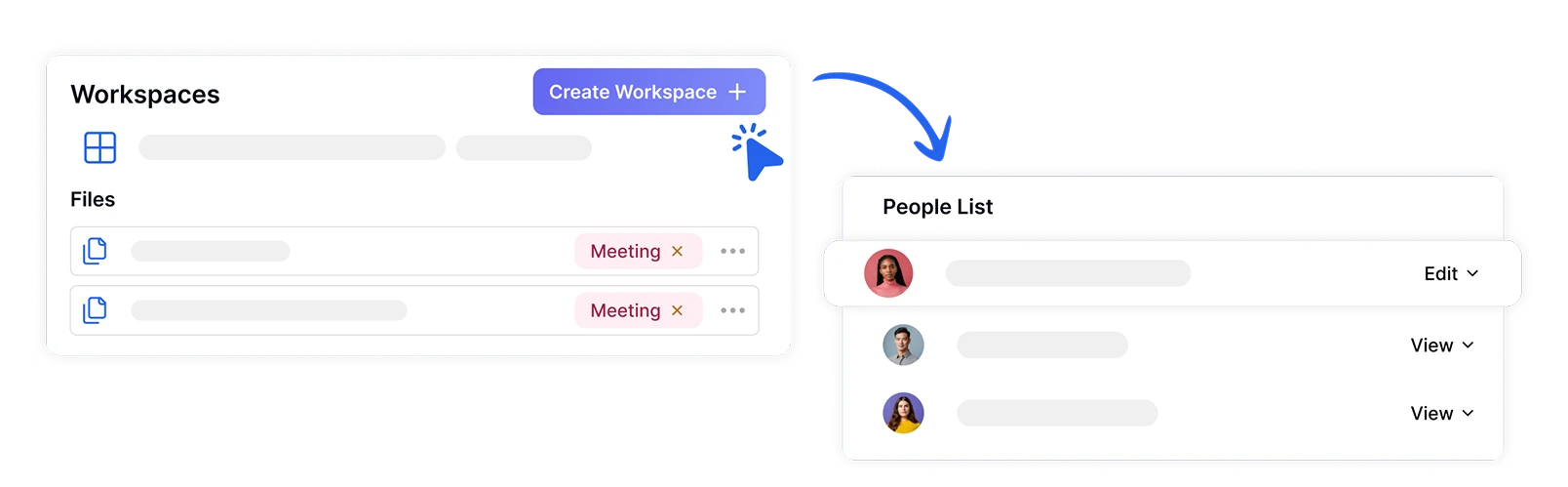
Organize and Share Files in Secure Workspaces
Manage team sentiment analysis projects securely by creating dedicated workspaces with assigned roles and permissions. Ensure sensitive emotional data is accessible only to authorized team members while facilitating collaboration on sentiment insights across departments.
Enterprise-Grade Security
Security and customer privacy is our priority at every step. We comply with SOC 2 and GDPR standards and ensuring your information is protected at all times.





Customer Success Stories
Reduced Churn by Using Sentiment Data
Transkriptor zrewolucjonizował sposób, w jaki nasz 14-osobowy zespół zarządza relacjami z klientami. Analizując sentyment w rozmowach wdrożeniowych i kontrolnych, identyfikujemy zagrożone konta, zanim pokażą to tradycyjne wskaźniki. Obsługa wielu języków radzi sobie z naszą globalną bazą klientów, a niestandardowe szablony pomagają ustandaryzować nasze podejście w całym zespole.

Kira Johnson
Customer Success Lead
30% Reduction in Bad Hires
Transkriptor has transformed our interview process over 7 months of use. The sentiment analysis helps identify emotional inconsistencies in candidate responses we might miss. Tracking sentiment across different interview topics gives deeper insights into cultural fit, significantly improving our hiring success rate.

Amira Khan
HR Director
Często Zadawane Pytania
Najlepszym narzędziem do analizy sentymentu jest Transkriptor. Napędzany zaawansowaną sztuczną inteligencją, Transkriptor automatycznie transkrybuje mowę i analizuje ton emocjonalny z wysoką dokładnością. Oznacza rozmowy jako pozytywne, negatywne lub neutralne i obsługuje ponad 100 języków.
Analiza sentymentu działa poprzez wykorzystanie sztucznej inteligencji i przetwarzania języka naturalnego (NLP) do oceny emocjonalnego tonu tekstu lub mowy. Identyfikuje kluczowe wskaźniki emocji, takie jak dobór słów, struktura zdania i kontekstowe wskazówki, aby klasyfikować treść jako pozytywną, negatywną lub neutralną. Bardziej zaawansowane systemy mogą również wykrywać intencje, zmiany emocjonalne i sentyment specyficzny dla mówcy w czasie.
Transkriptor umożliwia tworzenie niestandardowych przestrzeni roboczych z uprawnieniami opartymi na rolach do organizowania projektów analizy sentymentu. Możesz również budować bazy wiedzy wykorzystując treści oznaczone sentymentem, co ułatwia przechowywanie, kategoryzowanie i wyszukiwanie danych emocjonalnych przy zachowaniu bezpieczeństwa i dostępności.
Analiza sentymentu pomaga zespołom obsługi klienta identyfikować emocjonalne wyzwalacze w rozmowach, mierzyć skuteczność technik deeskalacji i śledzić nastrój klienta w całym procesie wsparcia. Te spostrzeżenia umożliwiają zespołom udoskonalenie ich podejścia, prowadząc do poprawy zadowolenia klientów i zmniejszenia liczby powtarzających się połączeń.
Tak, Transkriptor obsługuje analizę sentymentu w ponad 100 językach z wysoką dokładnością. System jest zaprojektowany do rozpoznawania niuansów kulturowych i językowych specyficznych dla każdego języka, zapewniając spójne wykrywanie sentymentu niezależnie od języka ojczystego mówcy.
Dostęp do Transkriptora Wszędzie
Nagrywaj na żywo lub przesyłaj pliki audio i wideo do transkrypcji. Edytuj swoje transkrypcje z łatwością i korzystaj z asystenta AI, aby prowadzić czat lub podsumowywać transkrypcje.