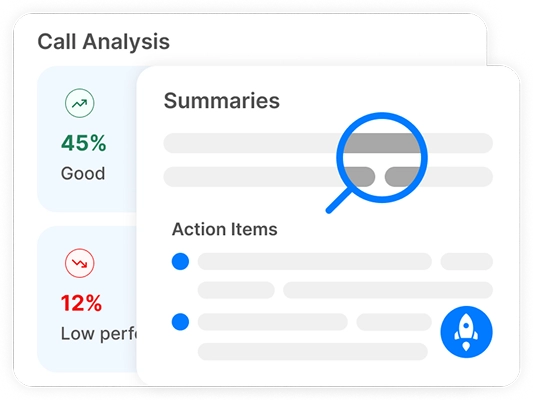
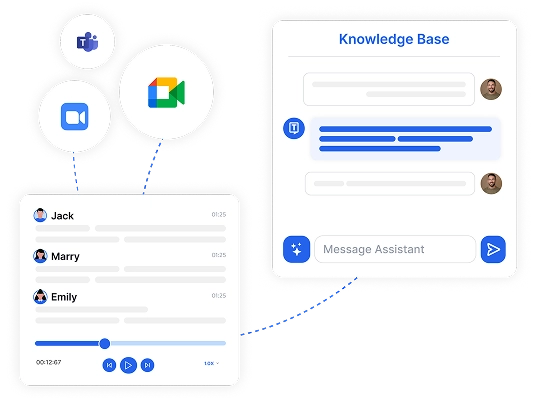
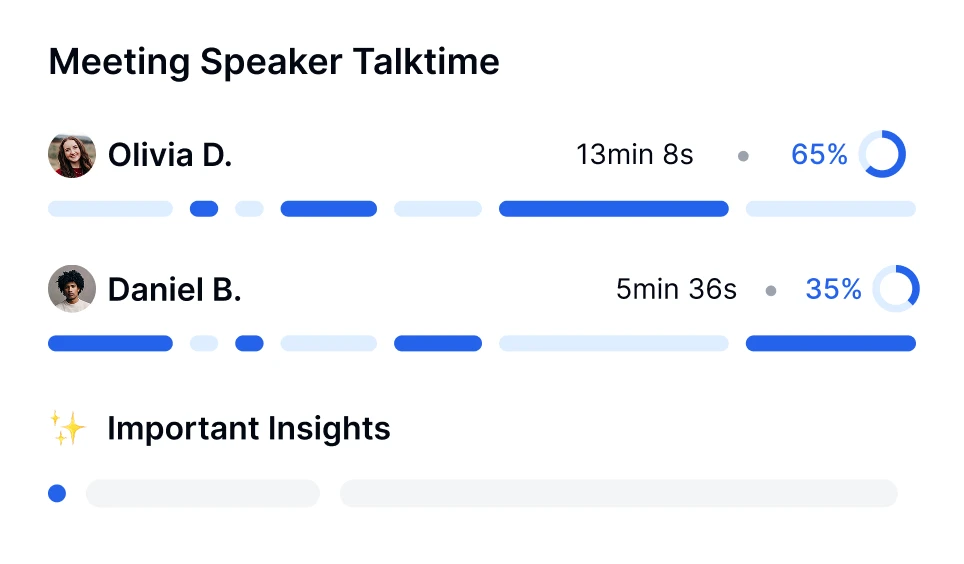
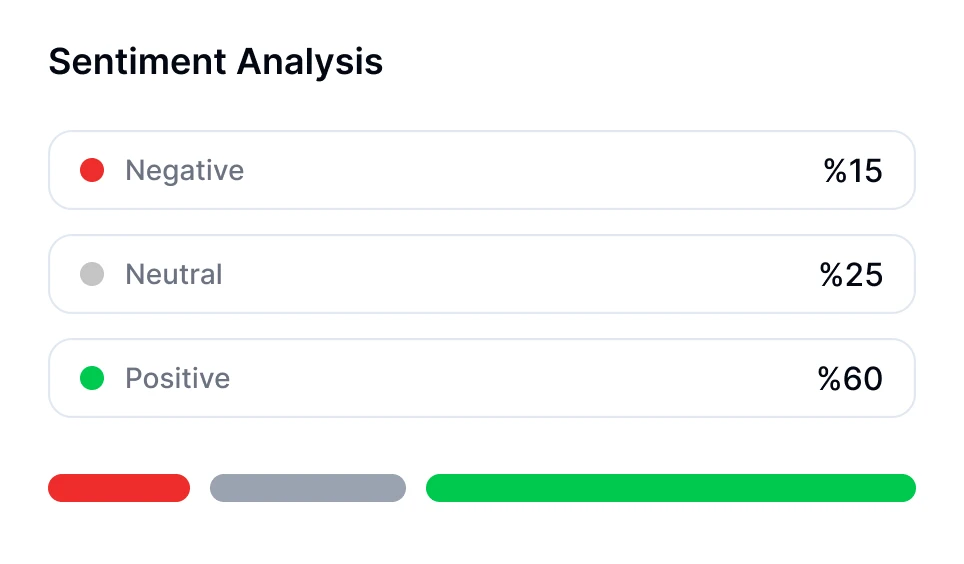
Erstellen Sie Ihr Konto & nehmen Sie eine Datei auf oder laden Sie sie hoch
Erstellen Sie Ihr Transkriptor-Konto und beginnen Sie mit kostenlosem Transkriptionszugang. Nehmen Sie Audio/Video auf oder laden Sie es hoch, um sofort mit der Transkription zu beginnen.