1
Crie Sua Conta & Grave ou Envie um Arquivo
Crie sua conta no Transkriptor gratuitamente. Em seguida, grave sua reunião, chamada, palestra ou envie seu áudio/vídeo para começar a transcrever.
Envie para converter áudio ou vídeo em texto
Transcrever arquivo MP3Clique para enviar e transcrever gratuitamente
Grave áudio ou vídeo e transcreva gratuitamente
Confiado por indivíduos em



















Converta áudio em texto com a extensão do Chrome de transcrição mais bem avaliada transcription Chrome Extension. Grave instantaneamente sua tela, câmera ou microfone e obtenha transcrições precisas de fala para texto diretamente do seu navegador.
O Transkriptor é reconhecido como uma das melhores soluções de software para transcrição de áudio, confiado por milhares de usuários em todo o mundo. Veja por que as pessoas nos escolhem como sua melhor ferramenta de transcrição de áudio.
Os atendentes foram muito resolutivos
Os atendentes foram muito resolutivos, resolvendo todas as pendencias.

Cacá Filho
Pergunte qualquer coisa sobre sua transcrição e deixe o Assistente de Transcrição por IA da Transkriptor fornecer respostas precisas. Para insights mais profundos em vários arquivos transcritos, crie bases de conhecimento pesquisáveis usando suas transcrições de áudio ou outros documentos enviados.
Obtenha insights de reuniões personalizados para você com a inteligência de transcrição por IA. O Transkriptor funciona com Zoom, Google Meet e Microsoft Teams para capturar cada conversa. Escolha entre modelos especializados para vendas, marketing, educação e mais, ou crie formatos personalizados para suas necessidades únicas. Transforme reuniões em insights estruturados e acionáveis.
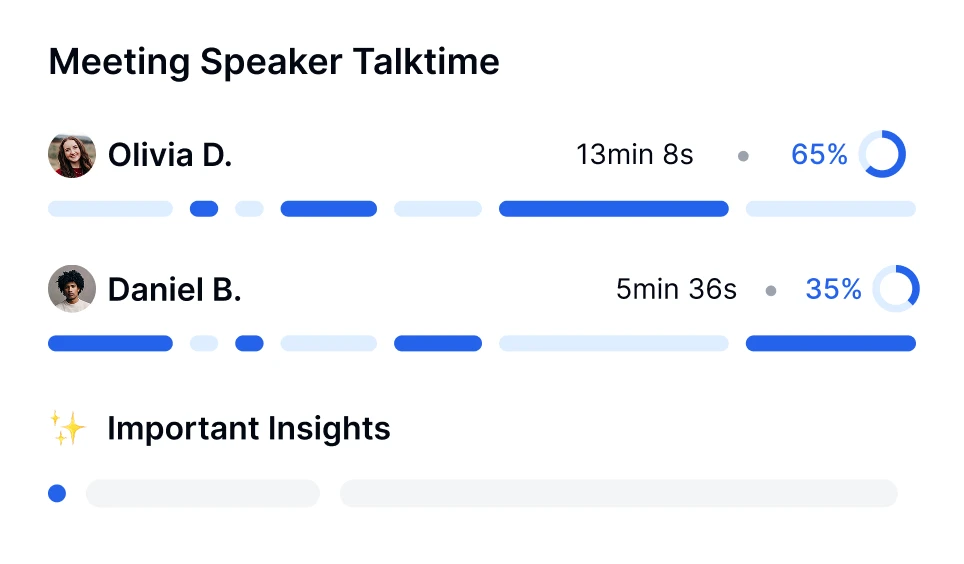
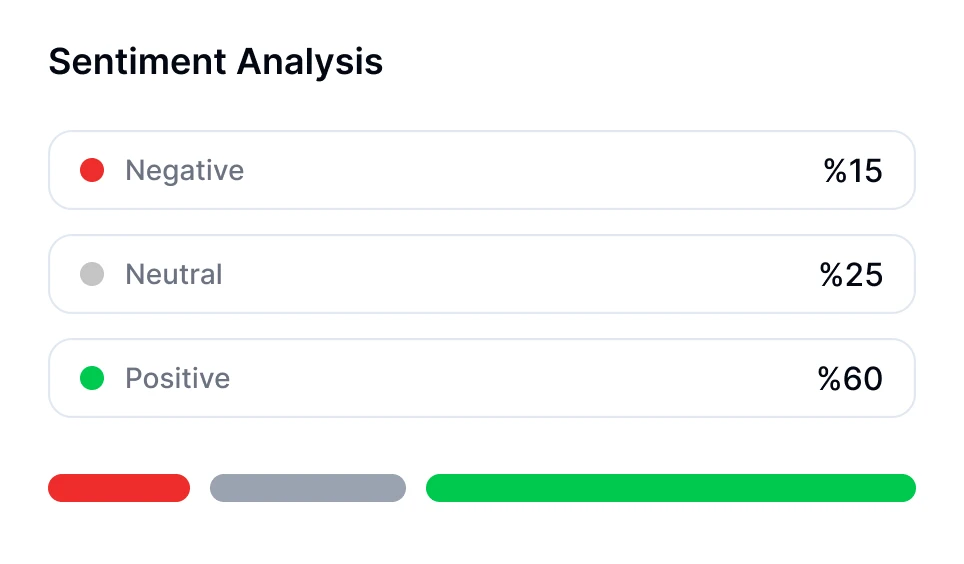
Aprofunde-se nas conversas com a tecnologia de transcrição por IA. Realize análise de sentimento, acompanhe tempos de fala e descubra insights baseados em dados de suas reuniões transcritas.
Converta facilmente vídeo em texto gratuitamente com nosso poderoso mecanismo de transcrição – sem necessidade de conversão de arquivos. Suportamos uma ampla gama de formatos, incluindo MP3, MP4, WAV e mais. Você pode transcrever qualquer conteúdo rapidamente e sem problemas de compatibilidade.
Conecte o Transkriptor com armazenamento em nuvem, CRM e outros aplicativos através do Zapier para transcrever automaticamente arquivos de mídia e direcionar suas transcrições precisas para suas plataformas preferidas, economizando tempo e mantendo seu conteúdo transcrito perfeitamente organizado.
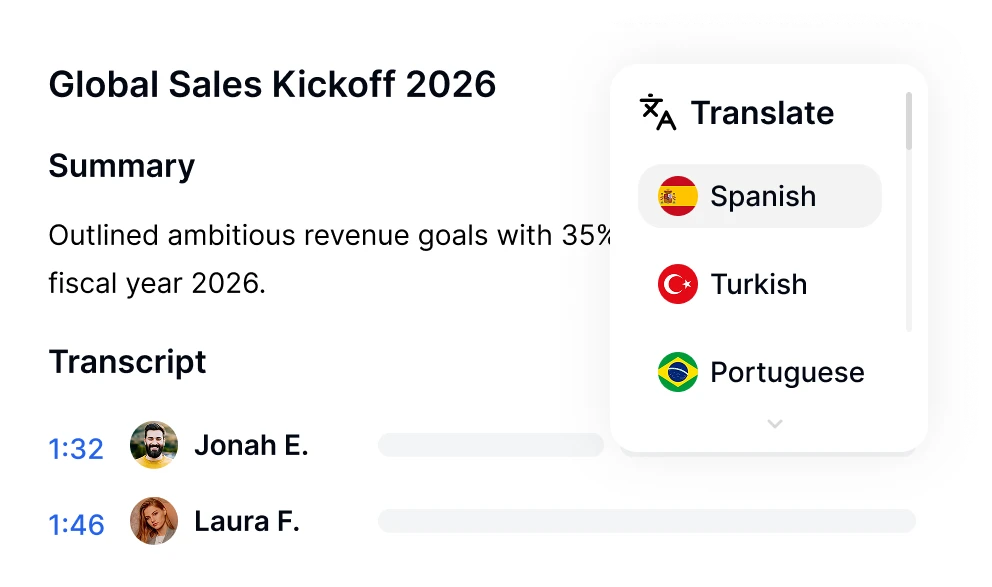
O Ask Transkriptor pesquisa instantaneamente cada transcrição de reunião na sua biblioteca para encontrar decisões, itens de ação, citações e respostas com fontes citadas, em mais de 100 idiomas.
Os insights das reuniões fluem diretamente para suas ferramentas de CRM, produtividade e armazenamento. Sem exportação, sem copiar e colar.




















Crie sua conta no Transkriptor gratuitamente. Em seguida, grave sua reunião, chamada, palestra ou envie seu áudio/vídeo para começar a transcrever.

O Transkriptor fornece transcrições totalmente editáveis, análise de sentimento de chamadas e divisão de tópicos chave.

Faça anotações facilmente dentro do Transkriptor para fácil acesso. Organize notas e transcrições em pastas e espaços de trabalho.

Automatize transcrições com integrações, construa bases de conhecimento a partir de múltiplos arquivos e faça perguntas ou converse com transcrições.
Procurando transcrever áudio em texto para o seu setor? A Transkriptor oferece recursos de transcrição específicos para indústrias, projetados para equipes jurídicas, profissionais de saúde, psicólogos, consultores, gerentes de TI e profissionais de mídia.

Transforme reuniões com clientes em transcrições de negócios organizadas e pesquisáveis com transcrição para consultores. Obtenha insights transcritos instantâneos, principais descobertas e análise de transcrição por IA para melhores resultados com clientes.

Concentre-se totalmente em seus clientes enquanto a Transkriptor atua como seu transcritor para sessões de terapia profissional. Obtenha notas organizadas das sessões, acompanhamento de progresso e documentação segura automaticamente.

Transforme reuniões com clientes em transcrições pesquisáveis com nossa tecnologia de transcrição jurídica. Acesse registros instantâneos das discussões enquanto mantém a confidencialidade.
Transforme cada reunião em insights acionáveis com transcrição, resumos e análises impulsionados por IA.
O Transkriptor prioriza segurança e privacidade em todos os níveis. Nossa plataforma de transcrição de nível empresarial está em conformidade com os padrões SOC 2, GDPR, ISO 27001 e SSL para garantir que seus dados de áudio e vídeo estejam totalmente protegidos e transcritos com segurança.





Transcrição é o processo de converter a linguagem falada de gravações de áudio ou vídeo em texto escrito. É amplamente utilizada para reuniões, entrevistas, palestras, podcasts e conteúdo de mídia. A transcrição pode ser feita manualmente por transcritores humanos ou automaticamente usando software de transcrição por IA.
A transcrição funciona convertendo palavras faladas de áudio ou vídeo em texto escrito. Você faz o upload de um arquivo em uma ferramenta como o Transkriptor, que usa IA para detectar fala, identificar falantes e gerar uma transcrição com marcação de tempo. Você pode então revisar e editar o texto, e exportá-lo em formatos como TXT, DOCX ou legendas (SRT/VTT).
Os benefícios da transcrição incluem melhor acessibilidade, melhor capacidade de busca de conteúdo e aumento da produtividade. Ela transforma conteúdo falado em texto escrito que é fácil de ler e reutilizar. A transcrição também apoia o SEO ao criar conteúdo indexável. Ferramentas de transcrição por IA como o Transkriptor automatizam o processo, economizando tempo e recursos.
A precisão da transcrição é afetada por vários fatores, incluindo qualidade do áudio, ruído de fundo, clareza dos falantes, diálogo sobreposto, sotaques e número de falantes. Áudio mal gravado ou sotaques fortes podem reduzir a eficácia das ferramentas de transcrição por IA. Microfones de alta qualidade, fala clara e mínimas interrupções melhoram os resultados.
Sim, ferramentas modernas de transcrição como o Transkriptor conseguem lidar com múltiplos falantes usando tecnologia de diarização de falantes. Este recurso identifica e rotula cada falante na transcrição, facilitando o acompanhamento de conversas em reuniões, entrevistas ou discussões em grupo.
O melhor software de transcrição é o Transkriptor. Ele oferece transcrição por IA altamente precisa, com até 99% de precisão. O Transkriptor suporta mais de 100 idiomas, permite que os usuários façam upload de arquivos de áudio ou vídeo em vários formatos e inclui recursos como identificação de falantes, geração de legendas e um editor de transcrições embutido. Outras ferramentas de transcrição populares incluem Otter.ai e Fireflies.ai, que também oferecem serviços de transcrição baseados em IA. No entanto, o Transkriptor é preferido por sua ampla cobertura de idiomas, preços acessíveis e recursos de edição simplificados que atendem tanto a usuários casuais quanto a profissionais.
Você pode realizar análise de sentimento para conversas usando ferramentas com tecnologia de IA como o Transkriptor. O bot de reuniões do Transkriptor pode participar diretamente de suas reuniões online ou analisar gravações enviadas. Após a transcrição, ele avalia automaticamente o tom emocional da conversa—classificando segmentos como positivos, neutros ou negativos.
O melhor conversor de áudio em texto é o Transkriptor. Ele usa IA avançada para converter com precisão o áudio falado em texto escrito em apenas segundos. O Transkriptor suporta formatos de áudio populares como MP3, WAV e M4A, e funciona em mais de 100 idiomas.
A melhor ferramenta gratuita de transcrição é o Transkriptor. Ele oferece serviços de transcrição de fala para texto altamente precisos e alimentados por IA, mesmo em seu plano gratuito. Com a opção gratuita de transcrição do Transkriptor, você pode transcrever até 30 minutos de áudio por dia.
A conversão de vídeo para texto é o processo de transformar automaticamente as palavras faladas em um vídeo em texto escrito, usando tecnologia de reconhecimento de fala avançada por IA.
O Transkriptor é uma das melhores ferramentas para transcrever vídeo em texto, oferecendo processamento rápido, alta precisão e suporte para vários idiomas e formatos.
Sim, você pode converter vídeo em texto automaticamente usando ferramentas de transcrição baseadas em IA, como o Transkriptor, eliminando a necessidade de digitação manual.
Sim, converter vídeo em texto melhora o SEO ao tornar o conteúdo de vídeo pesquisável, indexável e acessível aos mecanismos de busca.
Ferramentas de vídeo em texto são ideais para criadores de conteúdo, educadores, jornalistas, profissionais de marketing, estudantes e empresas que precisam de transcrição rápida.
Sim, a conversão de vídeo em texto melhora a acessibilidade ao fornecer transcrições legíveis para usuários com deficiência auditiva e públicos mais amplos.
A IA analisa padrões de fala, sinais de áudio e contexto de linguagem para converter com precisão as palavras faladas de um vídeo em texto.
O Transkriptor oferece transcrição de vídeo em texto rápida, precisa, segura e acessível, com IA poderosa e ferramentas fáceis de usar.