1
Створіть свій акаунт та запишіть або завантажте файл
Створіть свій акаунт у Transkriptor безкоштовно. Потім запишіть вашу зустріч, дзвінок, лекцію або завантажте аудіо/відео, щоб почати транскрибування.
Завантажте, щоб перетворити аудіо або відео в текст
Транскрибування MP3 файлуНатисніть, щоб завантажити та транскрибувати безкоштовно
Записуйте аудіо або відео та транскрибуйте безкоштовно
Довіряють особи в

Перетворюйте аудіо в текст за допомогою #1 транскрипційного розширення для Chrome. Миттєво записуйте ваш екран, камеру або мікрофон і отримуйте точні транскрипції мови в текст прямо з вашого браузера.
Transkriptor визнано одним з найкращих рішень для транскрибування аудіо, яким довіряють тисячі користувачів по всьому світу. Дізнайтеся, чому люди обирають нас як найкращий інструмент для транскрибування аудіо.
Найкращий додаток для транскрибування
Я користуюся Transkriptor вже кілька днів і дуже вражений точністю транскрибування. Навіть з довшими аудіофайлами або шумами додаток майже все правильно визначає. Швидкість обробки також є сильною стороною — файл готовий всього за кілька хвилин. Інтерфейс простий, не потрібно шукати функції, а експорт в інші формати значно полегшує роботу. Загалом, це практичний, швидкий і надійний інструмент, ідеальний для тих, кому потрібно перетворити аудіо в текст без зайвих проблем.

Matheus Santos
Запитайте будь-що про вашу транскрипцію, і AI-помічник Transkriptor надасть точні відповіді. Для глибшого аналізу кількох транскрибованих файлів створюйте пошукові бази знань, використовуючи ваші аудіо транскрипти або інші завантажені документи.
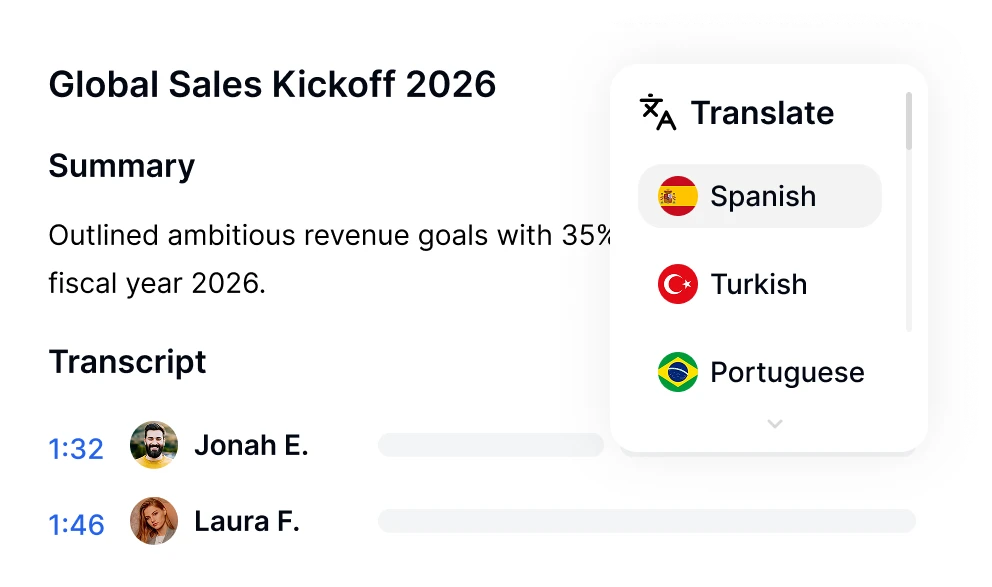
Отримайте інсайти з зустрічей, пристосовані до вас, завдяки інтелекту Транскрипції AI. Transkriptor працює з Zoom, Google Meet та Microsoft Teams, щоб фіксувати кожну розмову. Вибирайте зі спеціалізованих шаблонів для продажів, маркетингу, освіти та інших сфер або створюйте власні формати для ваших унікальних потреб. Перетворюйте зустрічі на структуровані, придатні до дії інсайти.
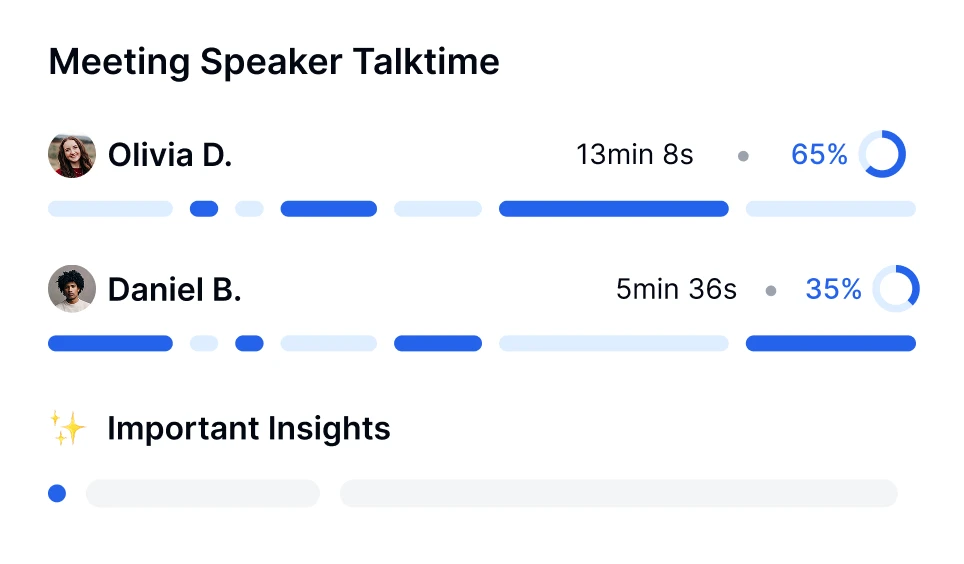
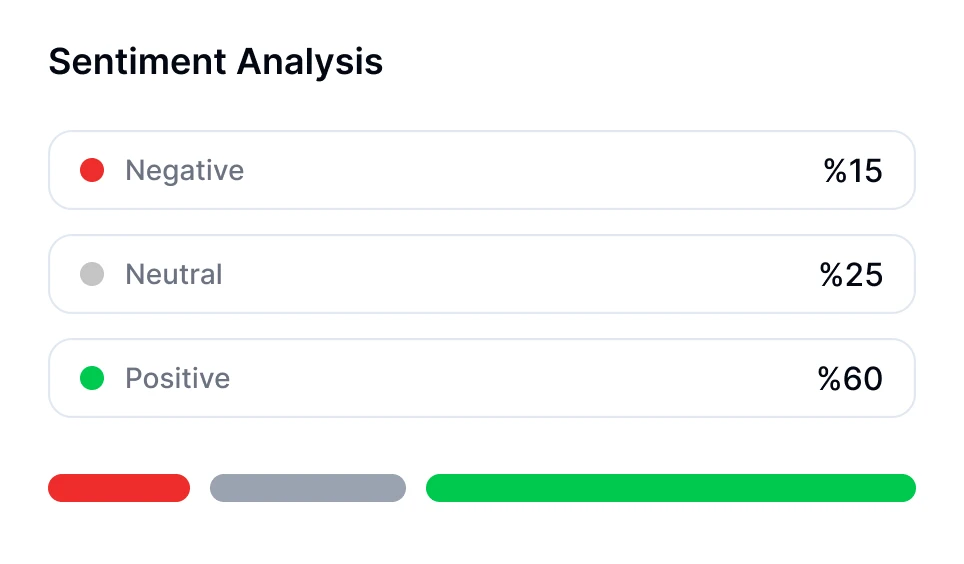
Занурюйтесь глибше в розмови з технологією AI-транскрипції. Проводьте аналіз настроїв, відстежуйте часи виступу спікерів і відкривайте інсайти, засновані на даних, з ваших транскрибованих зустрічей.
Легко перетворюйте відео в текст безкоштовно за допомогою нашого потужного двигуна транскрипції – без потреби у конвертації файлів. Ми підтримуємо широкий спектр форматів, включаючи MP3, MP4, WAV та інші. Ви можете швидко транскрибувати будь-який контент без проблем з сумісністю.
Підключіть Transkriptor до хмарного сховища, CRM та інших додатків через Zapier, щоб автоматично транскрибувати медіафайли та пересилати ваші точні транскрипції на ваші улюблені платформи, економлячи час та підтримуючи ваші транскрибовані матеріали в ідеальному порядку.
Ask Transkriptor миттєво шукає кожен транскрипт зустрічі у вашій бібліотеці, щоб знайти рішення, завдання, цитати та відповіді з джерелами, які зазначені, на понад 100 мовах.
Інсайти зі зустрічей безпосередньо інтегруються у ваші CRM, інструменти продуктивності та зберігання. Без експортування, без копіювання-вставки.




















Створіть свій акаунт у Transkriptor безкоштовно. Потім запишіть вашу зустріч, дзвінок, лекцію або завантажте аудіо/відео, щоб почати транскрибування.

Transkriptor надає повні редаговані транскрипції, аналіз настрою дзвінків і розбивку ключових тем.

Легко записуйте нотатки в Transkriptor для зручного доступу. Організовуйте нотатки та транскрипції в папках і робочих просторах.

Автоматизуйте транскрипції за допомогою інтеграцій, створюйте бази знань з кількох файлів і задавайте питання або спілкуйтеся з транскрипціями.
Шукаєте, як транскрибувати аудіо в текст для вашої галузі? Transkriptor надає функції транскрипції, спеціально розроблені для юридичних команд, медичних працівників, психологів, консультантів, ІТ-менеджерів та медіа-професіоналів.

Перетворюйте зустрічі з клієнтами в організовані, пошукові бізнес-транскрипції з транскрипцією для консультантів. Отримуйте миттєві транскрибовані інсайти, ключові висновки та аналіз транскрипції на основі AI для кращих результатів для клієнтів.

Зосередьтеся повністю на своїх клієнтах, поки Transkriptor виступає вашим професійним транскрибатором для терапевтичних сесій. Отримуйте організовані нотатки сесій, відстеження прогресу та безпечну документацію автоматично.

Перетворюйте клієнтські зустрічі на пошукові транскрипти за допомогою нашої технології юридичного транскрибування. Отримуйте миттєвий доступ до записів обговорень, зберігаючи конфіденційність.
Перетворіть кожну зустріч на корисні інсайти за допомогою транскрибування, резюме та аналітики на основі AI.
Transkriptor пріоритизує безпеку та конфіденційність на кожному рівні. Наша платформа транскрипції рівня підприємства відповідає стандартам SOC 2, GDPR, ISO 27001 та SSL, щоб забезпечити повний захист ваших аудіо та відео даних.





Транскрипція — це процес перетворення усної мови з аудіо або відеозаписів у письмовий текст. Вона широко використовується для зустрічей, інтерв'ю, лекцій, подкастів та медіаконтенту. Транскрипція може виконуватися вручну людьми або автоматично за допомогою програмного забезпечення для транскрипції на базі штучного інтелекту.
Транскрипція працює шляхом перетворення усних слів з аудіо або відео у письмовий текст. Ви завантажуєте файл у такий інструмент, як Transkriptor, який використовує штучний інтелект для розпізнавання мови, ідентифікації спікерів та створення транскрибованого тексту з часовими мітками. Потім ви можете переглянути та відредагувати текст і експортувати його у формати, такі як TXT, DOCX або субтитри (SRT/VTT).
Переваги транскрипції включають покращену доступність, кращу пошуковість контенту та підвищену продуктивність. Вона перетворює усний контент у письмовий текст, який легко читати та використовувати повторно. Транскрипція також підтримує SEO, створюючи індексований контент. Інструменти транскрипції на базі штучного інтелекту, такі як Transkriptor, автоматизують процес, заощаджуючи час і ресурси.
На точність транскрипції впливають кілька факторів, включаючи якість аудіо, фоновий шум, чіткість мовлення, перекриття діалогів, акценти та кількість спікерів. Погано записане аудіо або сильні акценти можуть знизити ефективність інструментів транскрипції на базі штучного інтелекту. Якісні мікрофони, чітке мовлення та мінімальні перерви покращують результати.
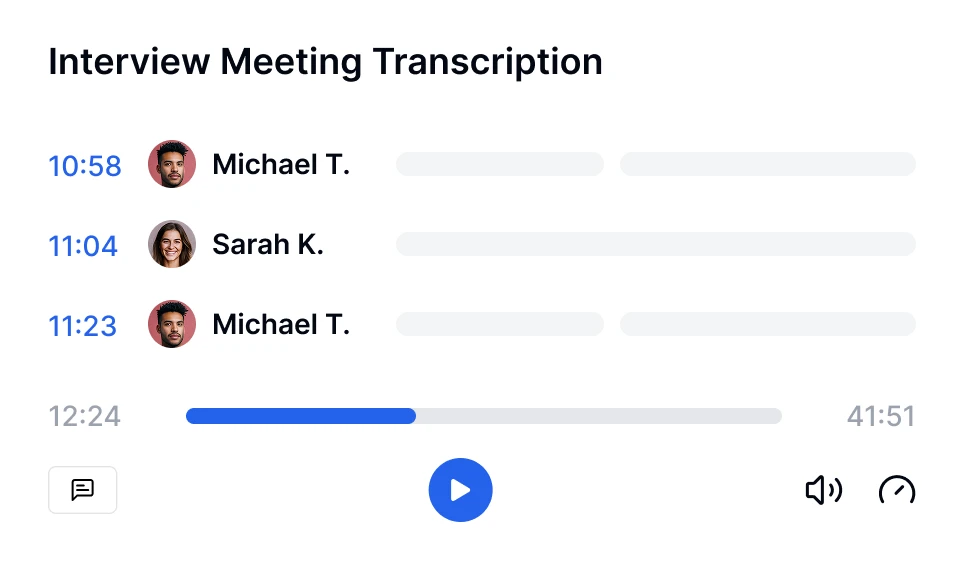
Так, сучасні інструменти транскрипції, такі як Transkriptor, можуть обробляти кілька спікерів, використовуючи технологію діаризації спікерів. Ця функція ідентифікує та позначає кожного спікера у транскрипті, що полегшує стеження за розмовами на зустрічах, інтерв'ю або групових обговореннях.
Найкраще програмне забезпечення для транскрипції — це Transkriptor. Воно пропонує високоточну транскрипцію на базі штучного інтелекту з точністю до 99%. Transkriptor підтримує понад 100 мов, дозволяє користувачам завантажувати аудіо або відеофайли у різних форматах та включає функції, такі як ідентифікація спікерів, генерація субтитрів та вбудований редактор транскриптів. Інші популярні інструменти транскрипції включають Otter.ai та Fireflies.ai, які також пропонують послуги транскрипції на базі штучного інтелекту. Однак Transkriptor надає перевагу завдяки ширшому охопленню мов, доступним цінам та зручним функціям редагування, які підтримують як звичайних користувачів, так і професіоналів.
Ви можете провести аналіз настроїв для розмов, використовуючи інструменти на базі штучного інтелекту, такі як Transkriptor. Бот для зустрічей Transkriptor може приєднатися безпосередньо до ваших онлайн-зустрічей або проаналізувати завантажені записи. Після транскрипції він автоматично оцінює емоційний тон розмови, класифікуючи сегменти як позитивні, нейтральні або негативні.
Найкращий конвертер аудіо в текст — це Transkriptor. Він використовує передові AI-технології для точного перетворення усного аудіо в письмовий текст за лічені секунди. Transkriptor підтримує популярні аудіоформати, такі як MP3, WAV і M4A, та працює більш ніж на 100 мовах.
Найкращий безкоштовний інструмент для транскрипції — це Transkriptor. Він надає високоточні та AI-підтримувані послуги перетворення мови в текст, навіть у безкоштовному плані. З безкоштовною опцією транскрипції Transkriptor ви можете транскрибувати до 30 хвилин аудіо на день.
Перетворення відео в текст - це процес автоматичного перетворення сказаних слів у відео на письмовий текст за допомогою технології розпізнавання мови на базі штучного інтелекту.
Transkriptor - один з найкращих інструментів для транскрибування відео в текст, що пропонує швидку обробку, високу точність та підтримку багатьох мов і форматів.
Так, ви можете автоматично перетворити відео в текст, використовуючи інструменти транскрибування на базі штучного інтелекту, такі як Transkriptor, без необхідності ручного набору.
Так, перетворення відео в текст покращує SEO, роблячи відеоконтент доступним для пошуку, індексування та доступним для пошукових систем.
Інструменти для перетворення відео в текст ідеальні для творців контенту, викладачів, журналістів, маркетологів, студентів і бізнесів, які потребують швидкого транскрибування.
Так, перетворення відео в текст покращує доступність, надаючи читабельні транскрипти для користувачів з вадами слуху та ширшої аудиторії.
Штучний інтелект аналізує мовні зразки, аудіосигнали та мовний контекст, щоб точно перетворити сказані слова з відео в текст.
Transkriptor пропонує швидке, точне, безпечне та доступне транскрибування відео в текст із потужним штучним інтелектом та зручними інструментами.