Crea Tu Cuenta y Graba o Sube un Archivo
Crea tu cuenta de Transkriptor y comienza con acceso gratuito a la transcripción. Graba o sube tu audio/video para comenzar a transcribir al instante.
Sube para convertir audio o video en texto
Transcribe archivo MP3Haz clic para subir y transcribir gratis
Graba audio o video y transcribe gratis
Confiado por personas en

Convierte audio a texto con la extensión de Chrome para transcripción mejor valorada. Graba instantáneamente tu pantalla, cámara o micrófono y obtén transcripciones de voz a texto precisas desde tu navegador.
Transkriptor es reconocido como una de las mejores soluciones de software de transcripción de audio, confiado por miles de usuarios en todo el mundo. Descubre por qué la gente nos elige como su mejor herramienta de transcripción de audio.
He estado usando Transkriptor durante meses, y la precisión es consistentemente del 98-99%, incluso con términos técnicos. Soporta múltiples idiomas, incluyendo inglés, sueco y alemán. Convertir largas grabaciones en texto ahora es mucho más rápido y eficiente.

Lena Kaur
Especialista en Marketing Digital
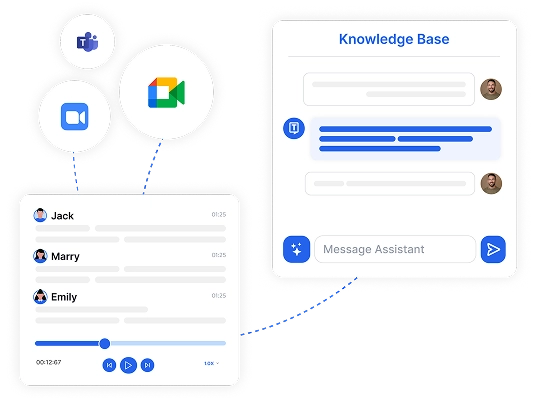
Pregunta cualquier cosa sobre tu transcripción, y deja que el Asistente de Transcripción de IA de Transkriptor proporcione respuestas precisas. Para obtener información más profunda a través de múltiples archivos transcritos, crea bases de conocimiento buscables usando tus transcripciones de audio u otros documentos subidos.
Obtén información de reuniones adaptada a ti con la inteligencia de transcripción de IA. Transkriptor funciona con Zoom, Google Meet y Microsoft Teams para capturar cada conversación. Elige entre plantillas especializadas para ventas, marketing, educación y más, o crea formatos personalizados para tus necesidades únicas. Convierte reuniones en información estructurada y procesable.
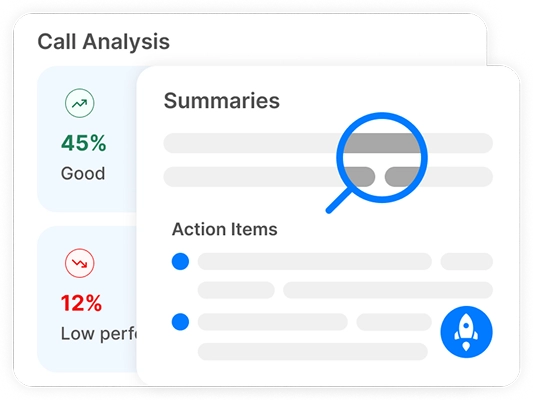
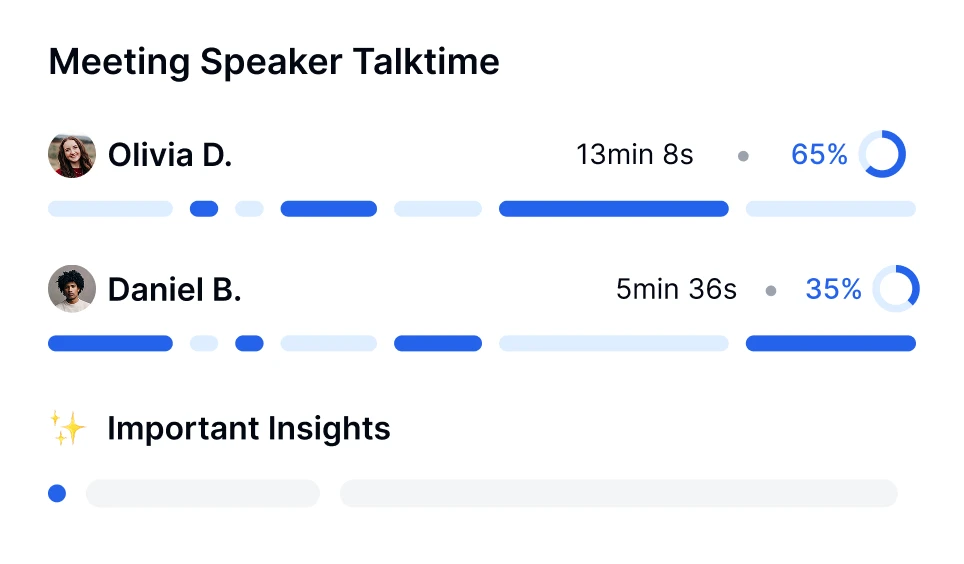
Profundiza en las conversaciones con la tecnología de transcripción de IA. Realiza análisis de sentimiento, rastrea los tiempos de los oradores y descubre información basada en datos de tus reuniones transcritas.
Convierte fácilmente video a texto gratis con nuestro potente motor de transcripción; no se necesita conversión de archivos. Soportamos una amplia gama de formatos, incluidos MP3, MP4, WAV y más. Puedes transcribir cualquier contenido rápidamente y sin problemas de compatibilidad.
Conecta Transkriptor con almacenamiento en la nube, CRM y otras aplicaciones a través de Zapier para transcribir automáticamente archivos multimedia y enviar tus transcripciones precisas a tus plataformas preferidas, ahorrando tiempo y manteniendo tu contenido transcrito perfectamente organizado.
Aprender a transcribir audio a texto es sencillo con Transkriptor. Sigue nuestro proceso paso a paso para convertir cualquier grabación, como reuniones, conferencias, entrevistas o notas de voz, en texto preciso y editable en segundos.
¿Buscas transcribir audio a texto para tu industria? Transkriptor ofrece características de transcripción específicas para equipos legales, proveedores de salud, psicólogos, consultores, gerentes de TI y profesionales de medios.

Transcripción médica segura y precisa para profesionales. Transforma interacciones con pacientes en transcripciones clínicas organizadas al instante.

Transforma reuniones con clientes en transcripciones de negocios organizadas y buscables con transcripción para consultores. Obtén ideas transcritas al instante, hallazgos clave y análisis de transcripción impulsado por IA para mejores resultados con los clientes.

Concéntrate completamente en tus clientes mientras Transkriptor actúa como tu transcriptor profesional para sesiones de terapia. Obtén notas de sesión organizadas, seguimiento del progreso y documentación segura automáticamente.

Transforma reuniones con clientes en transcripciones buscables con nuestra tecnología de transcripción legal. Accede a registros instantáneos de discusiones mientras mantienes la confidencialidad.

Transcripción de medios rápida y precisa para profesionales de transmisiones y producción de contenido. Convierte audio a texto al instante, con soporte para múltiples formatos e idiomas.
Transforma cada reunión en información accionable con transcripción, resúmenes y análisis impulsados por IA.
Transkriptor prioriza la seguridad y la privacidad en cada nivel. Nuestra plataforma de transcripción de nivel empresarial cumple con los estándares SOC 2, GDPR, ISO 27001 y SSL para garantizar que tus datos de audio y video estén completamente protegidos y transcritos de manera segura.





La transcripción es el proceso de convertir el lenguaje hablado de grabaciones de audio o video en texto escrito. Se utiliza ampliamente para reuniones, entrevistas, conferencias, podcasts y contenido multimedia. La transcripción puede realizarse manualmente por transcriptores humanos o automáticamente utilizando software de transcripción por IA.
La transcripción funciona convirtiendo palabras habladas de audio o video en texto escrito. Subes un archivo a una herramienta como Transkriptor, que utiliza IA para detectar el habla, identificar a los hablantes y generar una transcripción con marcas de tiempo. Luego puedes revisar y editar el texto, y exportarlo en formatos como TXT, DOCX o subtítulos (SRT/VTT).
Los beneficios de la transcripción incluyen una mejor accesibilidad, mejor capacidad de búsqueda de contenido y mayor productividad. Convierte contenido hablado en texto escrito que es fácil de leer y reutilizar. La transcripción también apoya el SEO al crear contenido indexable. Las herramientas de transcripción por IA como Transkriptor automatizan el proceso, ahorrando tiempo y recursos.
La precisión de la transcripción se ve afectada por varios factores, incluyendo la calidad del audio, el ruido de fondo, la claridad del hablante, el diálogo superpuesto, los acentos y el número de hablantes. El audio mal grabado o los acentos fuertes pueden reducir la efectividad de las herramientas de transcripción por IA. Micrófonos de alta calidad, discurso claro y mínimas interrupciones mejoran los resultados.
Sí, las herramientas de transcripción modernas como Transkriptor pueden manejar múltiples hablantes utilizando tecnología de diarización de hablantes. Esta función identifica y etiqueta a cada hablante en la transcripción, facilitando el seguimiento de las conversaciones en reuniones, entrevistas o discusiones grupales.
El mejor software de transcripción es Transkriptor. Ofrece transcripción altamente precisa impulsada por IA con hasta un 99% de exactitud. Transkriptor admite más de 100 idiomas, permite a los usuarios subir archivos de audio o video en varios formatos, e incluye funciones como identificación de hablantes, generación de subtítulos y un editor de transcripciones incorporado. Otras herramientas populares de transcripción incluyen Otter.ai y Fireflies.ai, que también ofrecen servicios de transcripción basados en IA. Sin embargo, Transkriptor es preferido por su amplia cobertura de idiomas, precios asequibles y funciones de edición simplificadas que apoyan tanto a usuarios ocasionales como a profesionales.
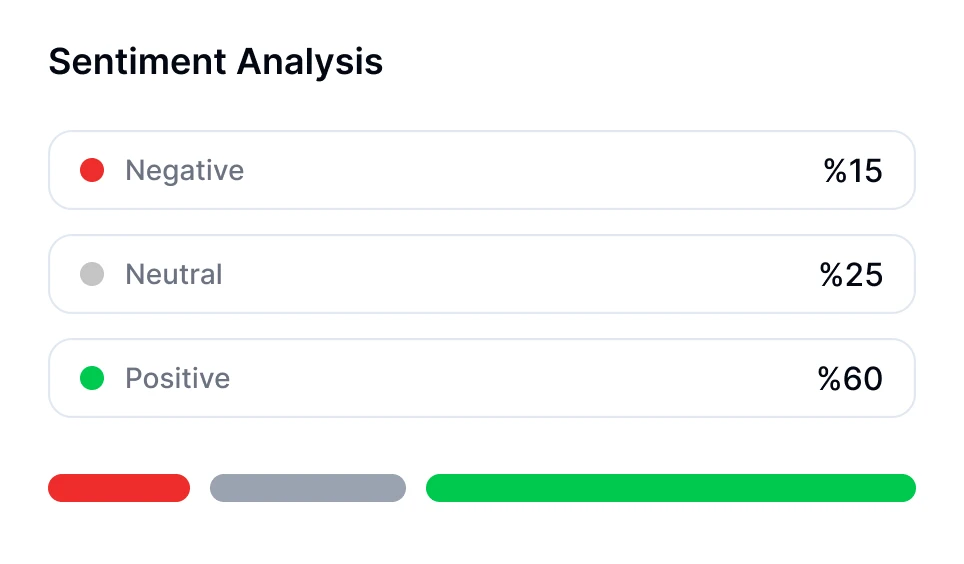
Puedes realizar un análisis de sentimiento para conversaciones usando herramientas impulsadas por IA como Transkriptor. El bot de reuniones de Transkriptor puede unirse a tus reuniones en línea directamente o analizar grabaciones subidas. Después de la transcripción, evalúa automáticamente el tono emocional de la conversación, clasificando segmentos como positivos, neutrales o negativos.
El mejor convertidor de audio a texto es Transkriptor. Utiliza IA avanzada para convertir con precisión el audio hablado en texto escrito en solo segundos. Transkriptor admite formatos de audio populares como MP3, WAV y M4A, y funciona en más de 100 idiomas.
La mejor herramienta de transcripción gratuita es Transkriptor. Proporciona servicios de transcripción de voz a texto altamente precisos e impulsados por IA, incluso en su plan gratuito. Con la opción de transcripción gratuita de Transkriptor, puedes transcribir hasta 30 minutos de audio por día.
La conversión de video a texto es el proceso de convertir automáticamente las palabras habladas en un video en texto escrito utilizando tecnología de reconocimiento de voz impulsada por IA.
Transkriptor es una de las mejores herramientas para transcribir video a texto, ofreciendo un procesamiento rápido, alta precisión y soporte para múltiples idiomas y formatos.
Sí, puedes convertir video a texto automáticamente usando herramientas de transcripción basadas en IA como Transkriptor, eliminando la necesidad de escribir manualmente.
Sí, convertir video a texto mejora el SEO al hacer que el contenido de video sea buscable, indexable y accesible para los motores de búsqueda.
Las herramientas de video a texto son ideales para creadores de contenido, educadores, periodistas, mercadólogos, estudiantes y empresas que necesitan transcripciones rápidas.
Sí, la conversión de video a texto mejora la accesibilidad al proporcionar transcripciones legibles para usuarios con discapacidad auditiva y audiencias más amplias.
La IA analiza patrones de habla, señales de audio y contexto del lenguaje para convertir con precisión las palabras habladas de un video en texto.
Transkriptor ofrece una transcripción de video a texto rápida, precisa, segura y asequible con una potente IA y herramientas fáciles de usar.