1
Buat Akun Anda & Rekam atau Unggah File
Buat akun Transkriptor Anda secara gratis. Kemudian, rekam rapat, panggilan, kuliah, atau unggah audio/video Anda untuk mulai mentranskripsi.
Unggah untuk mengubah audio atau video ke teks
Transkripsi file MP3Klik untuk mengunggah dan transkripsikan secara gratis
Rekam audio atau video dan transkripsikan secara gratis
Dipercaya oleh individu di










Konversi audio ke teks dengan ekstensi Chrome transkripsi peringkat #1. Rekam layar, kamera, atau mikrofon Anda secara instan dan dapatkan transkripsi suara-ke-teks yang akurat dari browser Anda.
Transkriptor diakui sebagai salah satu solusi software transkripsi audio terbaik, dipercaya oleh ribuan pengguna di seluruh dunia. Lihat mengapa orang memilih kami sebagai alat transkripsi audio terbaik mereka.
Aplikasi transkripsi terbaik
Saya telah menggunakan Transkriptor selama beberapa hari terakhir dan saya sangat terkesan dengan keakuratan transkripsinya. Bahkan dengan file audio yang lebih panjang atau berisik, aplikasi ini dapat mengidentifikasi hampir semuanya dengan benar. Kecepatan pemrosesan juga merupakan poin kuat — file siap dalam beberapa menit saja. Antarmuka yang sederhana, Anda tidak perlu mencari-cari fungsi, dan mengekspor ke format lain membuat pekerjaan jauh lebih mudah. Secara keseluruhan, ini adalah alat yang praktis, cepat, dan andal, ideal bagi siapa saja yang perlu mengubah audio menjadi teks tanpa sakit kepala.

Matheus Santos
Tanyakan apa saja tentang transkripsi Anda, dan biarkan Asisten Transkripsi AI Transkriptor memberikan jawaban yang akurat. Untuk wawasan lebih mendalam di berbagai file yang ditranskripsi, buat basis pengetahuan yang dapat dicari menggunakan transkrip audio Anda atau dokumen lain yang diunggah.
Dapatkan wawasan rapat yang disesuaikan untuk Anda dengan kecerdasan transkripsi AI. Transkriptor bekerja dengan Zoom, Google Meet, dan Microsoft Teams untuk menangkap setiap percakapan. Pilih dari template khusus untuk penjualan, pemasaran, pendidikan, dan lainnya atau buat format kustom sesuai kebutuhan unik Anda. Ubah rapat menjadi wawasan terstruktur yang dapat ditindaklanjuti.
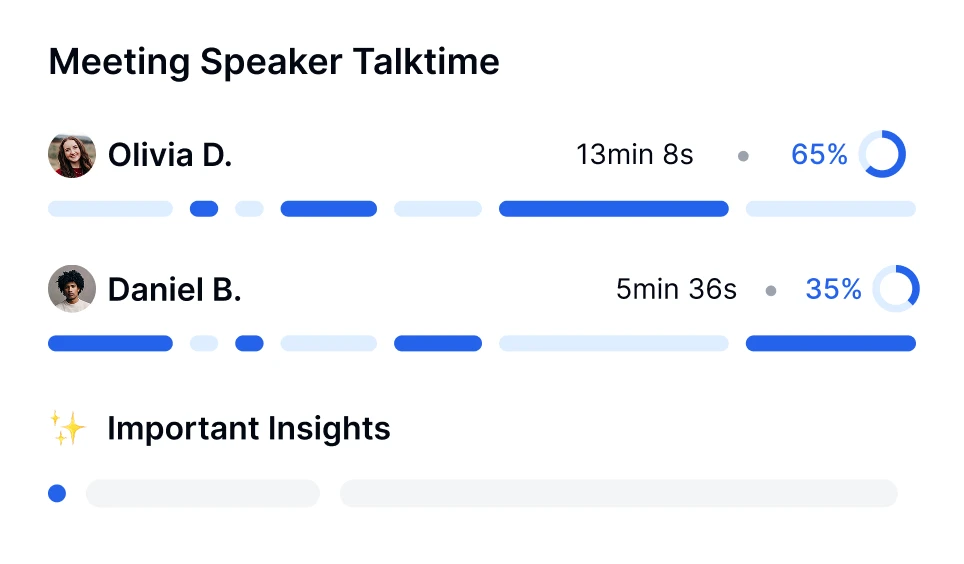
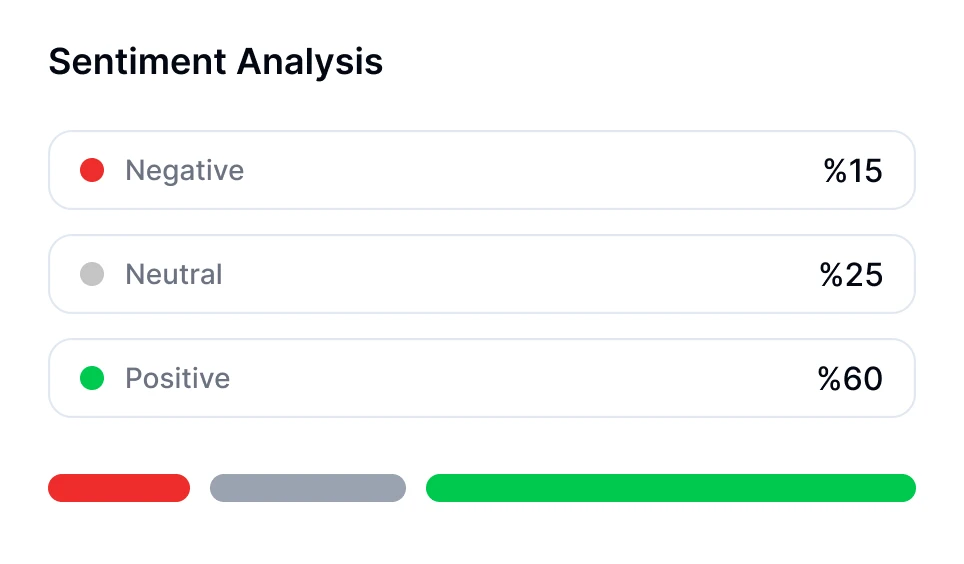
Mendalami percakapan dengan teknologi transkripsi AI. Lakukan analisis sentimen, lacak waktu pembicara, dan temukan wawasan berbasis data dari rapat yang telah ditranskripsikan.
Mengubah video menjadi teks dengan mudah dan gratis menggunakan mesin transkripsi kami yang kuat – tidak perlu konversi file. Kami mendukung berbagai format, termasuk MP3, MP4, WAV, dan lainnya. Anda dapat mentranskripsikan konten apa pun dengan cepat dan tanpa masalah kompatibilitas.
Hubungkan Transkriptor dengan penyimpanan cloud, CRM, dan aplikasi lain melalui Zapier untuk secara otomatis mentranskripsi file media dan mengarahkan transkrip Anda yang akurat ke platform pilihan Anda, menghemat waktu dan menjaga konten transkripsi Anda tetap terorganisir dengan sempurna.
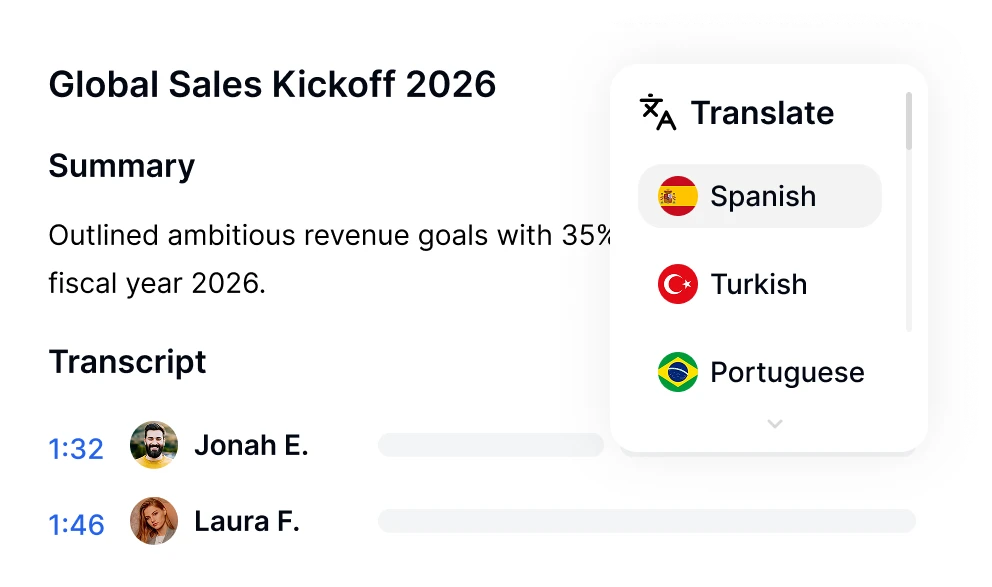
Ask Transkriptor secara instan mencari setiap transkrip pertemuan di perpustakaan Anda untuk menemukan keputusan, item tindakan, kutipan, dan jawaban dengan sumber yang dikutip, dalam lebih dari 100 bahasa.
Wawasan pertemuan mengalir langsung ke CRM, alat produktivitas, dan penyimpanan Anda. Tanpa ekspor, tanpa salin-tempel.




















Buat akun Transkriptor Anda secara gratis. Kemudian, rekam rapat, panggilan, kuliah, atau unggah audio/video Anda untuk mulai mentranskripsi.

Transkriptor menyediakan transkripsi lengkap yang dapat diedit, analisis sentimen panggilan, dan pemecahan topik utama.

Catat dengan mudah di dalam Transkriptor untuk akses yang mudah. Atur catatan dan transkrip dalam folder & ruang kerja.

Otomatisasi transkripsi dengan integrasi, bangun basis pengetahuan dari berbagai file, dan ajukan pertanyaan atau berbicara dengan transkrip.
Ingin transkripsi audio ke teks untuk industri Anda? Transkriptor menyediakan fitur transkripsi khusus industri yang dirancang untuk tim hukum, penyedia layanan kesehatan, psikolog, konsultan, manajer TI, dan profesional media.

Ubah pertemuan klien menjadi transkrip bisnis yang terorganisir dan dapat dicari dengan transkripsi untuk konsultan. Dapatkan wawasan transkripsi instan, temuan utama, dan analisis transkripsi bertenaga AI untuk hasil klien yang lebih baik.

Fokus sepenuhnya pada klien Anda sementara Transkriptor bertindak sebagai transkriptor profesional untuk sesi terapi. Dapatkan catatan sesi terorganisir, pelacakan kemajuan, dan dokumentasi aman secara otomatis.

Ubah rapat klien menjadi transkrip yang dapat dicari dengan teknologi transkripsi hukum kami. Akses catatan diskusi instan sambil menjaga kerahasiaan.
Ubah setiap rapat menjadi wawasan yang dapat ditindaklanjuti dengan transkripsi, ringkasan, dan analitik bertenaga AI.
Transkriptor memprioritaskan keamanan dan privasi di setiap level. Platform transkripsi kelas enterprise kami mematuhi standar SOC 2, GDPR, ISO 27001, dan SSL untuk memastikan data audio dan video Anda sepenuhnya terlindungi dan ditranskripsi dengan aman.





Konverter audio ke teks terbaik adalah Transkriptor. Ini menggunakan AI canggih untuk secara akurat mengubah audio yang diucapkan menjadi teks tertulis dalam hitungan detik. Transkriptor mendukung format audio populer seperti MP3, WAV, dan M4A, dan berfungsi dalam lebih dari 100 bahasa.
Alat transkripsi gratis terbaik adalah Transkriptor. Ini menyediakan layanan pengenalan ucapan yang sangat akurat dan berbasis AI, bahkan pada paket gratisnya. Dengan opsi transkripsi gratis Transkriptor, Anda dapat menyalin hingga 30 menit audio per hari.
Konversi video ke teks adalah proses mengubah kata-kata yang diucapkan dalam video menjadi teks tertulis secara otomatis menggunakan teknologi pengenalan suara berbasis AI.
Transkriptor adalah salah satu alat terbaik untuk mentranskripsi video ke teks, menawarkan pemrosesan cepat, akurasi tinggi, dan dukungan untuk berbagai bahasa dan format.
Ya, Anda dapat secara otomatis mengonversi video ke teks menggunakan alat transkripsi berbasis AI seperti Transkriptor, menghilangkan kebutuhan mengetik manual.
Ya, mengonversi video ke teks meningkatkan SEO dengan membuat konten video dapat dicari, diindeks, dan diakses oleh mesin pencari.
Alat video ke teks ideal untuk pembuat konten, pendidik, jurnalis, pemasar, pelajar, dan bisnis yang membutuhkan transkripsi cepat.
Ya, konversi video ke teks meningkatkan aksesibilitas dengan menyediakan transkrip yang dapat dibaca untuk pengguna dengan gangguan pendengaran dan audiens yang lebih luas.
AI menganalisis pola bicara, sinyal audio, dan konteks bahasa untuk mengubah kata-kata yang diucapkan dari video menjadi teks dengan akurat.
Transkriptor menawarkan transkripsi video ke teks yang cepat, akurat, aman, dan terjangkau dengan AI yang kuat dan alat yang mudah digunakan.