Klicken Sie, um hochzuladen und kostenlos zu transkribieren
Audio oder Video aufnehmen und kostenlos transkribieren
Vertraut von Einzelpersonen bei
Audio zu Text von Gerät (Mobil, Desktop, Tablet) und Browser (Chrome, Firefox, Microsoft Edge, Safari) transkribieren
Konvertieren Sie Audio zu Text mit der am besten bewerteten Transkriptions-Chrome-Erweiterung. Nehmen Sie sofort Ihren Bildschirm, Ihre Kamera oder Ihr Mikrofon auf und erhalten Sie genaue Sprach-zu-Text-Transkriptionen direkt aus Ihrem Browser.
Erhalten Sie präzise Transkripte in Sekundenschnelle. Transkriptor sorgt dafür, dass jedes Wort genau transkribiert wird — direkt aus Ihrem Webbrowser. Das Online-Tool von Transkriptor für Audio zu Text ist perfekt, um Besprechungen, Interviews, Vorträge und mehr schnell und präzise zu transkribieren.
Nehmen Sie Ihre Meetings mit der Transkriptor Desktop-App auf. Kein Bot tritt Ihrem Anruf bei. Ein automatisches Popup erscheint, sobald Sie einem Meeting beitreten, sodass Sie mit einem Klick mit der Aufnahme beginnen können.
Verpassen Sie kein Wort, egal wo Sie sind. Erfassen Sie Vorträge, Besprechungen und Sprachnotizen mühelos mit der am besten bewerteten Android-Audio-Transkriptor-App — perfekt für Arbeit, Studium und Alltag.
Verwandeln Sie Ihr iPhone in eine leistungsstarke Sprach-zu-Text-Transkriptionsmaschine. Konvertieren Sie gesprochene Worte sofort in durchsuchbare Transkripte — perfekt für Besprechungen, Vorträge und Content-Erstellung unterwegs mit unserer Transkriptions-App für iPhone.
Bestes Audio-Transkriptionsprogramm Transkriptor Bewertungen und Erfahrungsberichte
Transkriptor wird als eines der besten Audio-Transkriptionsprogramme anerkannt und von Tausenden von Nutzern weltweit geschätzt. Erfahren Sie, warum Menschen uns als ihr bevorzugtes Werkzeug zur Audio-Transkription wählen.
Ich habe Transkriptor kürzlich ausprobiert und bin wirklich positiv überrascht! Die Transkriptionen waren nicht nur schnell fertig, sondern auch äußerst präzise. Ich kann Transkriptor jedem empfehlen, der eine schnelle und zuverlässige Transkriptionslösung sucht!
Intelligentere Meetings mit KI-Einblicken freischalten
Jedes Audio oder Video in Sekunden in Text umwandeln
Zugriff auf Notizen jederzeit mit Cloud-Synchronisation über Plattformen hinweg
Fragen Sie alles über Ihre Transkription, und lassen Sie den KI-Transkriptionsassistenten von Transkriptor genaue Antworten liefern. Für tiefere Einblicke in mehrere transkribierte Dateien erstellen Sie durchsuchbare Wissensdatenbanken mit Ihren Audio-Transkripten oder anderen hochgeladenen Dokumenten.
Erhalten Sie maßgeschneiderte Meeting-Einblicke mit KI-gestützter Transkription. Transkriptor arbeitet mit [Zoom](https://www.zoom.com/), [Google Meet](https://meet.google.com/landing) und [Microsoft Teams](https://www.microsoft.com/en-us/microsoft-teams/join-a-meeting), um jedes Gespräch zu erfassen. Wählen Sie aus spezialisierten Vorlagen für Vertrieb, Marketing, Bildung und mehr oder erstellen Sie benutzerdefinierte Formate für Ihre individuellen Bedürfnisse. Verwandeln Sie Meetings in strukturierte, umsetzbare Einblicke.
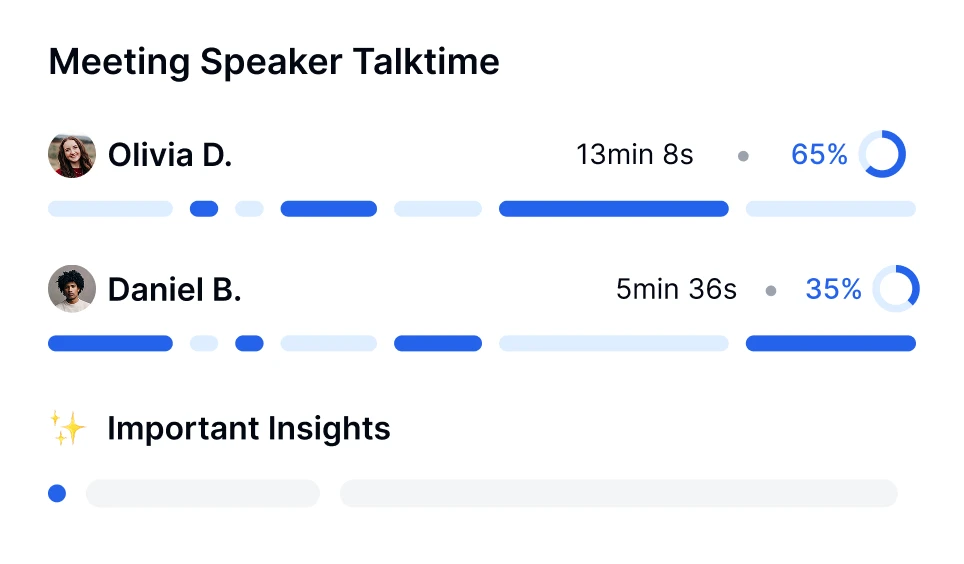
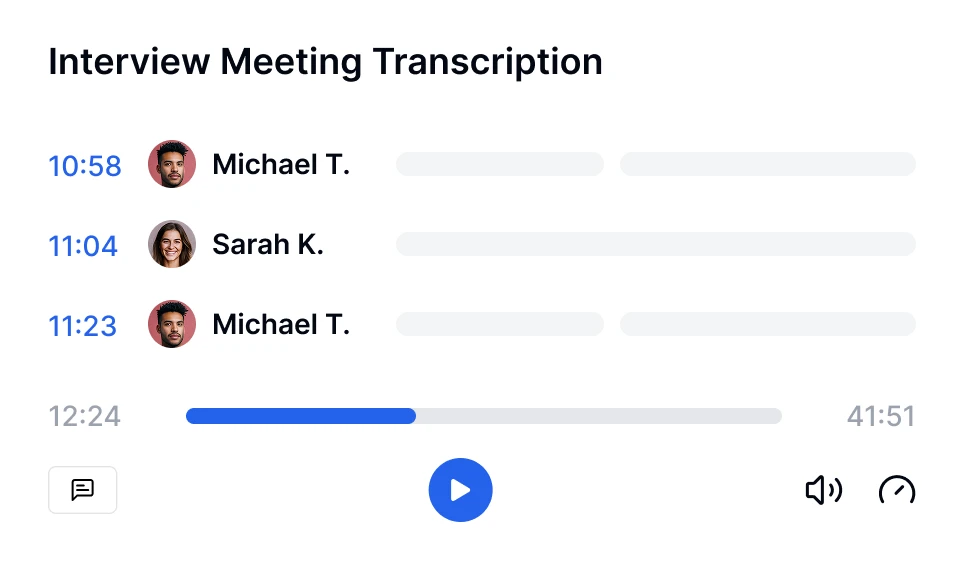
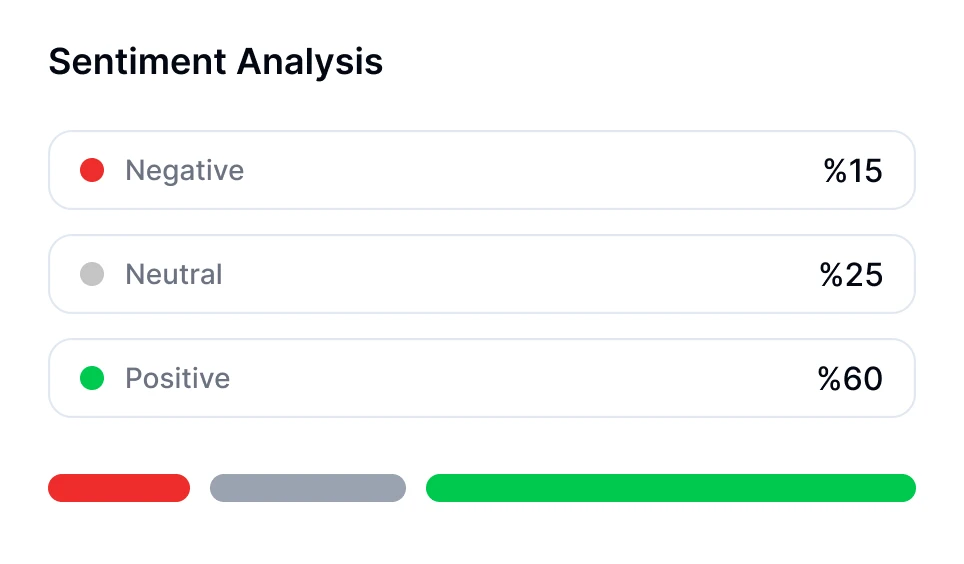
Tauchen Sie tiefer in Gespräche ein mit KI-Transkriptionstechnologie. Führen Sie [Sentiment-Analysen](sentiment-analysis) durch, verfolgen Sie Sprecherzeiten und entdecken Sie datengesteuerte Einblicke aus Ihren transkribierten Meetings.
Wandeln Sie [Video in Text](video-to-text) kostenlos um mit unserer leistungsstarken Transkriptionsmaschine – keine Dateikonvertierung erforderlich. Wir unterstützen eine Vielzahl von Formaten, einschließlich MP3, MP4, WAV und mehr. Sie können Inhalte schnell und ohne Kompatibilitätsprobleme transkribieren.
Verbinden Sie Transkriptor mit Cloud-Speicher, CRM und anderen Apps über Zapier, um Mediendateien automatisch zu transkribieren und Ihre genauen Transkripte an Ihre bevorzugten Plattformen zu leiten, was Zeit spart und Ihre transkribierten Inhalte perfekt organisiert hält.
Chatten Sie mit Ihren Gesprächen
Fragen Sie alles über Ihre Transkription, und lassen Sie den KI-Transkriptionsassistenten von Transkriptor genaue Antworten liefern. Für tiefere Einblicke in mehrere transkribierte Dateien erstellen Sie durchsuchbare Wissensdatenbanken mit Ihren Audio-Transkripten oder anderen hochgeladenen Dokumenten.
Erhalten Sie maßgeschneiderte Meeting-Einblicke mit KI-gestützter Transkription. Transkriptor arbeitet mit Zoom, Google Meet und Microsoft Teams, um jedes Gespräch zu erfassen. Wählen Sie aus spezialisierten Vorlagen für Vertrieb, Marketing, Bildung und mehr oder erstellen Sie benutzerdefinierte Formate für Ihre individuellen Bedürfnisse. Verwandeln Sie Meetings in strukturierte, umsetzbare Einblicke.
Intelligentere Meetings mit KI-Einblicken freischalten
Tauchen Sie tiefer in Gespräche ein mit KI-Transkriptionstechnologie. Führen Sie Sentiment-Analysen durch, verfolgen Sie Sprecherzeiten und entdecken Sie datengesteuerte Einblicke aus Ihren transkribierten Meetings.
Jedes Audio oder Video in Sekunden in Text umwandeln
Wandeln Sie Video in Text kostenlos um mit unserer leistungsstarken Transkriptionsmaschine – keine Dateikonvertierung erforderlich. Wir unterstützen eine Vielzahl von Formaten, einschließlich MP3, MP4, WAV und mehr. Sie können Inhalte schnell und ohne Kompatibilitätsprobleme transkribieren.
Zugriff auf Notizen jederzeit mit Cloud-Synchronisation über Plattformen hinweg
Verbinden Sie Transkriptor mit Cloud-Speicher, CRM und anderen Apps über Zapier, um Mediendateien automatisch zu transkribieren und Ihre genauen Transkripte an Ihre bevorzugten Plattformen zu leiten, was Zeit spart und Ihre transkribierten Inhalte perfekt organisiert hält.
Verwandeln Sie jedes Meeting in durchsuchbares Wissen mit der Funktion Ask Transkriptor
Ask Transkriptor durchsucht sofort jedes Meeting-Transkript in Ihrer Bibliothek, um Entscheidungen, Aufgaben, Zitate und Antworten mit Quellenangaben in über 100 Sprachen zu finden.
Finden Sie jede Erwähnung eines Themas, jedes Versprechen eines Teammitglieds und jede Antwort, die Sie bereits gehört haben — ohne ein einziges Meeting erneut anzuhören.
Jede Antwort von Ask Transkriptor basiert auf einem bestimmten Moment in einem bestimmten Meeting, sodass Sie den Kontext überprüfen und die Originalquelle mit einem Klick teilen können.
Ask Transkriptor verwandelt Ihre Meeting-Bibliothek in einen arbeitenden Assistenten — es fasst wiederkehrende Themen zusammen, entwirft Nachverfolgungen und extrahiert nächste Schritte aus Wochen von Gesprächen.
Funktioniert mit den Tools, die Ihr Team bereits verwendet
Meeting-Einblicke fließen direkt in Ihre CRM-, Produktivitäts- und Speichertools. Kein Exportieren, kein Kopieren und Einfügen.
CRM
Projektmanagement
Speicherung
Kalender
Videokonferenz
Notizen & Dokumentation
VoIP
API
MCP
Zusammenarbeit
CRM
Projektmanagement
Speicherung
Kalender
Videokonferenz
Notizen & Dokumentation
VoIP
API
MCP
Zusammenarbeit
CRM
Projektmanagement
Speicherung
Kalender
Videokonferenz
Notizen & Dokumentation
VoIP
API
MCP
Zusammenarbeit
Wie man Audio zu Text transkribiert
1. Erstellen Sie Ihr Konto & nehmen Sie auf oder laden Sie eine Datei hoch
2. Erhalten Sie Zusammenfassungen, Einblicke, Analysen
3. Notizen machen & Dateien organisieren
4. Automatisieren & mit Transkripten sprechen
1
Erstellen Sie Ihr Konto & nehmen Sie auf oder laden Sie eine Datei hoch
Erstellen Sie kostenlos Ihr Transkriptor-Konto. Nehmen Sie dann Ihr Meeting, Ihren Anruf, Ihren Vortrag auf oder laden Sie Ihre Audio-/Videodatei hoch, um mit der Transkription zu beginnen.
2
Erhalten Sie Zusammenfassungen, Einblicke, Analysen
Transkriptor bietet vollständige bearbeitbare Transkriptionen, Stimmungsanalysen von Anrufen und Aufschlüsselungen der wichtigsten Themen.
3
Notizen machen & Dateien organisieren
Machen Sie einfach Notizen innerhalb von Transkriptor für einen einfachen Zugriff. Organisieren Sie Notizen und Transkripte in Ordnern & Arbeitsbereichen.
4
Automatisieren & mit Transkripten sprechen
Automatisieren Sie Transkriptionen mit Integrationen, erstellen Sie Wissensdatenbanken aus mehreren Dateien und stellen Sie Fragen oder sprechen Sie mit Transkripten.
Kostenlose Audio zu Text Transkription
Laden Sie Audio hoch oder nehmen Sie es auf, um es in Sekundenschnelle kostenlos mit schnellen und genauen Ergebnissen mit Transkriptor, der besten kostenlosen Transkriptions-App, zu transkribieren.
Loading...
Audio zu Text für jede Branche transkribieren
Möchten Sie Audio zu Text für Ihre Branche transkribieren? Transkriptor bietet branchenspezifische Transkriptionsfunktionen für Rechtsteams, Gesundheitsdienstleister, Psychologen, Berater, IT-Manager und Medienprofis.
Audio zu Text Transkription für Berater
Verwandeln Sie Mandantengespräche in organisierte, durchsuchbare Geschäftstranskripte mit Transkription für Berater. Erhalten Sie sofort transkribierte Einblicke, wichtige Erkenntnisse und KI-gestützte Transkriptionsanalysen für bessere Ergebnisse mit Ihren Klienten.
Sofortige Sitzungszusammenfassungen
35+ Berichtsvorlagen
Wissensdatenbank-Erstellung
Audio zu Text Transkription für Psychologen
Konzentrieren Sie sich voll und ganz auf Ihre Klienten, während Transkriptor als Ihr professioneller Transkribierer für Therapiesitzungen fungiert. Erhalten Sie organisierte Sitzungsnotizen, Fortschrittsverfolgung und sichere Dokumentation automatisch.
Sichere Sitzungsaufzeichnungen
Fortschrittsverfolgung
Automatisierte Sitzungszusammenfassungen
Audio zu Text Transkription für Anwälte & Rechtsanwälte
Verwandeln Sie Kundengespräche in durchsuchbare Transkripte mit unserer juristischen Transkription Technologie. Greifen Sie auf sofortige Aufzeichnungen von Diskussionen zu und wahren Sie dabei die Vertraulichkeit.
Sichere, vertrauliche Transkription
Sofortige Sitzungszusammenfassungen
Durchsuchbare Falldokumentation
Lassen Sie unsere KI-gestützte Transkriptionssoftware Ihre Notizen übernehmen – Konzentrieren Sie sich auf das Wesentliche
Verzichten Sie auf manuelles Notieren. Transkriptor transkribiert automatisch jedes Wort, fasst die wichtigsten Punkte zusammen und organisiert Ihre professionellen Transkripte – so können Sie sich auf das Gespräch konzentrieren.
KI-Transkription von Audio zu Text
Sprache zu Text leicht gemacht
Wandeln Sie gesprochene Worte automatisch in präzisen geschriebenen Text um. Spracherkennung Werkzeuge ermöglichen es Ihnen, Notizen, Nachrichten oder Dokumente schneller zu diktieren als zu tippen, was Zeit und Mühe spart.
KI-Meeting-Assistent
Ein KI-Meeting-Assistent zeichnet Gespräche auf, transkribiert sie live und erstellt Zusammenfassungen und Aktionspunkte. Ideal für Teams, die strukturierte Ergebnisse aus jedem Meeting wünschen.
Beste kostenlose Transkriptionssoftware
Kostenlose Transkriptionssoftware ermöglicht es Nutzern, Audio- oder Videodateien ohne Abonnements zu transkribieren. Eine großartige Option für Studenten, Forscher und Personen mit gelegentlichem Transkriptionsbedarf.
Vorlesungen und Kurse transkribieren
Verwandeln Sie Vorlesungen und Präsentationen in durchsuchbaren Text. Transkriptionssoftware hilft Studenten, Material zu überprüfen, wichtige Konzepte hervorzuheben und effizienter zu lernen.
Sprachnotizen zu schriftlichem Inhalt
Nehmen Sie Sprachnotizen auf und verwandeln Sie sie sofort in schriftlichen Inhalt. Dieser Workflow ist ideal für Brainstorming, Content-Erstellung und das Festhalten von Ideen, bevor sie vergessen werden.
Automatisierte Transkription für Anrufe
Transkribieren Sie automatisch Telefonanrufe, Interviews oder Online-Meetings. Transkripte verbessern die Dokumentation, Compliance und Klarheit im Kundenservice und in der internen Kommunikation.
KI-Meeting-Tools
Verwandeln Sie jedes Meeting in umsetzbare Erkenntnisse mit KI-gestützter Transkription, Zusammenfassungen und Analysen.
KI-Meeting-Engagement-Metriken
Verfolgen Sie Redezeit, Teilnahme und Engagement-Niveaus. Verwandeln Sie Meeting-Daten in Erkenntnisse, die die Teamarbeit verbessern.
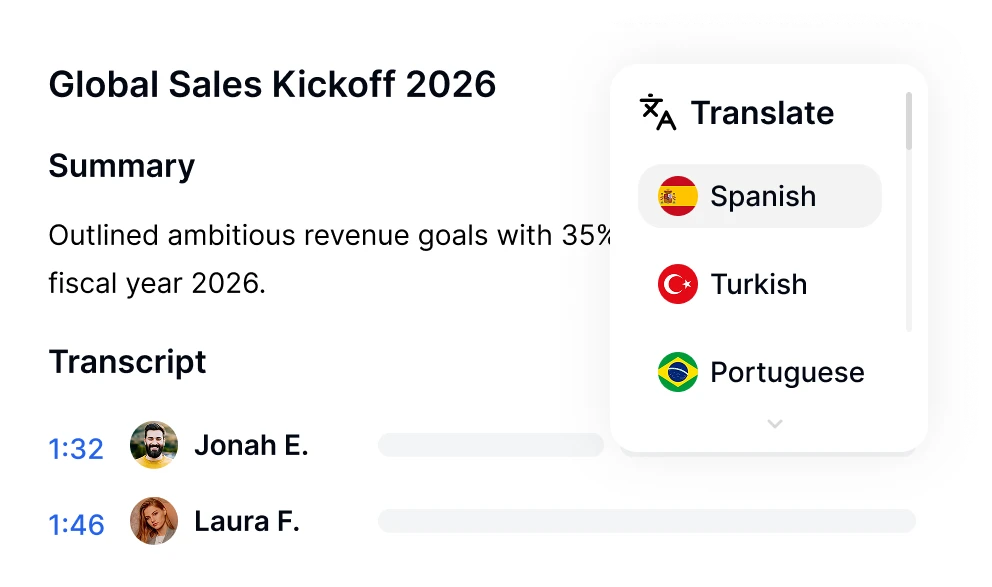
KI-Meeting-Übersetzer
Übersetzen Sie Meeting-Transkripte und Zusammenfassungen in über 100 Sprachen. Überwinden Sie Sprachbarrieren in globalen Teams.
KI-Mehrsprachige Transkription für Meetings
Transkribieren Sie Meetings in über 100 Sprachen mit 99% Genauigkeit. Erfassen Sie jedes Wort, unabhängig von der Sprache.
KI-Meeting-Sprecher-Diarisierung
Identifizieren und kennzeichnen Sie automatisch jeden Sprecher in Ihren Meetings. Wissen Sie genau, wer was gesagt hat.
KI-Executive-Zusammenfassungen
Erhalten Sie in Sekundenschnelle prägnante, KI-generierte Meeting-Zusammenfassungen. Konzentrieren Sie sich auf Entscheidungen und wichtige Erkenntnisse, nicht auf das Notieren.
KI-Meeting-Aktionspunkte
Extrahieren Sie automatisch Aktionspunkte, Fristen und Verantwortliche aus jedem Meeting. Verpassen Sie nie wieder eine Nachverfolgung.
KI-Stimmungsanalyse
Analysieren Sie Ton und Emotionen in Ihren Meetings. Verstehen Sie die Stimmung der Teilnehmer, um die Zusammenarbeit zu verbessern.
KI-Meeting-Engagement-Metriken
Verfolgen Sie Redezeit, Teilnahme und Engagement-Niveaus. Verwandeln Sie Meeting-Daten in Erkenntnisse, die die Teamarbeit verbessern.
KI-Meeting-Übersetzer
Übersetzen Sie Meeting-Transkripte und Zusammenfassungen in über 100 Sprachen. Überwinden Sie Sprachbarrieren in globalen Teams.
KI-Mehrsprachige Transkription für Meetings
Transkribieren Sie Meetings in über 100 Sprachen mit 99% Genauigkeit. Erfassen Sie jedes Wort, unabhängig von der Sprache.
KI-Meeting-Sprecher-Diarisierung
Identifizieren und kennzeichnen Sie automatisch jeden Sprecher in Ihren Meetings. Wissen Sie genau, wer was gesagt hat.
KI-Executive-Zusammenfassungen
Erhalten Sie in Sekundenschnelle prägnante, KI-generierte Meeting-Zusammenfassungen. Konzentrieren Sie sich auf Entscheidungen und wichtige Erkenntnisse, nicht auf das Notieren.
KI-Meeting-Aktionspunkte
Extrahieren Sie automatisch Aktionspunkte, Fristen und Verantwortliche aus jedem Meeting. Verpassen Sie nie wieder eine Nachverfolgung.
KI-Stimmungsanalyse
Analysieren Sie Ton und Emotionen in Ihren Meetings. Verstehen Sie die Stimmung der Teilnehmer, um die Zusammenarbeit zu verbessern.
KI-Meeting-Engagement-Metriken
Verfolgen Sie Redezeit, Teilnahme und Engagement-Niveaus. Verwandeln Sie Meeting-Daten in Erkenntnisse, die die Teamarbeit verbessern.
KI-Meeting-Übersetzer
Übersetzen Sie Meeting-Transkripte und Zusammenfassungen in über 100 Sprachen. Überwinden Sie Sprachbarrieren in globalen Teams.
Sicherheit auf Unternehmensebene in der Transkription
Transkriptor legt auf jeder Ebene Wert auf Sicherheit und Datenschutz. Unsere Transkriptionsplattform auf Unternehmensebene entspricht den SOC 2-, GDPR-, ISO 27001- und SSL-Standards, um sicherzustellen, dass Ihre Audio- und Videodaten vollständig geschützt und sicher transkribiert werden.
Häufig gestellte Fragen für Allgemeines
Transkription ist der Prozess, bei dem gesprochene Sprache aus Audio- oder Videoaufnahmen in geschriebenen Text umgewandelt wird. Sie wird häufig für Besprechungen, Interviews, Vorträge, Podcasts und Medieninhalte verwendet. Transkription kann manuell von menschlichen Transkriptoren oder automatisch mit KI-Transkriptionssoftware durchgeführt werden.
Transkription funktioniert, indem gesprochene Wörter aus Audio oder Video in geschriebenen Text umgewandelt werden. Sie laden eine Datei in ein Tool wie Transkriptor hoch, das KI verwendet, um Sprache zu erkennen, Sprecher zu identifizieren und ein Zeitstempel-Transkript zu erstellen. Sie können dann den Text überprüfen und bearbeiten und ihn in Formaten wie TXT, DOCX oder Untertiteln (SRT/VTT) exportieren.
Die Vorteile der Transkription umfassen verbesserte Zugänglichkeit, bessere Durchsuchbarkeit von Inhalten und gesteigerte Produktivität. Sie verwandelt gesprochene Inhalte in geschriebenen Text, der leicht zu lesen und wiederzuverwenden ist. Transkription unterstützt auch SEO, indem sie indexierbare Inhalte erstellt. KI-Transkriptionswerkzeuge wie Transkriptor automatisieren den Prozess, was Zeit und Ressourcen spart.
Die Genauigkeit der Transkription wird von mehreren Faktoren beeinflusst, darunter die Audioqualität, Hintergrundgeräusche, die Klarheit der Sprecher, überlappende Dialoge, Akzente und die Anzahl der Sprecher. Schlecht aufgenommene Audiodateien oder starke Akzente können die Effektivität von KI-Transkriptionswerkzeugen verringern. Hochwertige Mikrofone, klare Sprache und minimale Unterbrechungen verbessern die Ergebnisse.
Ja, moderne Transkriptionswerkzeuge wie Transkriptor können mehrere Sprecher verarbeiten, indem sie die Sprecher-Diarisierungstechnologie verwenden. Diese Funktion identifiziert und kennzeichnet jeden Sprecher im Transkript, was es einfacher macht, Gesprächen in Besprechungen, Interviews oder Gruppendiskussionen zu folgen.
Die beste Transkriptionssoftware ist Transkriptor. Sie bietet hochgenaue KI-gestützte Transkription mit bis zu 99% Genauigkeit. Transkriptor unterstützt über 100 Sprachen, ermöglicht Benutzern das Hochladen von Audio- oder Videodateien in verschiedenen Formaten und bietet Funktionen wie Sprecheridentifikation, Untertitelgenerierung und einen integrierten Transkript-Editor. Weitere beliebte Transkriptionswerkzeuge sind Otter.ai und Fireflies.ai, die ebenfalls KI-basierte Transkriptionsdienste anbieten. Transkriptor wird jedoch aufgrund seiner breiteren Sprachabdeckung, erschwinglichen Preise und optimierten Bearbeitungsfunktionen, die sowohl Gelegenheitssuchende als auch Profis unterstützen, bevorzugt.
Sie können eine Stimmungsanalyse für Gespräche mit KI-gestützten Tools wie Transkriptor durchführen. Der Meeting-Bot von Transkriptor kann direkt an Ihren Online-Meetings teilnehmen oder hochgeladene Aufnahmen analysieren. Nach der Transkription bewertet er automatisch den emotionalen Ton des Gesprächs und klassifiziert Segmente als positiv, neutral oder negativ.
Der beste Audio zu Text Konverter ist Transkriptor. Es nutzt fortschrittliche KI, um gesprochene Audiodaten in nur wenigen Sekunden präzise in geschriebenen Text umzuwandeln. Transkriptor unterstützt beliebte Audioformate wie MP3, WAV und M4A und funktioniert in über 100 Sprachen.
Das beste kostenlose Transkriptionstool ist Transkriptor. Es bietet hochpräzise und KI-gestützte Sprach-zu-Text-Dienste, sogar im kostenlosen Plan. Mit der kostenlosen Transkriptionsoption von Transkriptor können Sie bis zu 30 Minuten Audio pro Tag transkribieren.
Die Umwandlung von Video zu Text ist der Prozess, bei dem gesprochene Worte in einem Video automatisch in geschriebenen Text umgewandelt werden, indem KI-gestützte Spracherkennungstechnologie verwendet wird.
Transkriptor ist eines der besten Tools, um Video zu Text zu transkribieren. Es bietet schnelle Verarbeitung, hohe Genauigkeit und Unterstützung für mehrere Sprachen und Formate.
Ja, Sie können Video automatisch in Text umwandeln, indem Sie KI-basierte Transkriptionstools wie Transkriptor verwenden, wodurch manuelles Tippen entfällt.
Ja, die Umwandlung von Video zu Text verbessert SEO, indem sie Videoinhalte durchsuchbar, indexierbar und für Suchmaschinen zugänglich macht.
Tools zur Umwandlung von Video zu Text sind ideal für Content-Ersteller, Pädagogen, Journalisten, Vermarkter, Studenten und Unternehmen, die eine schnelle Transkription benötigen.
Ja, die Umwandlung von Video zu Text verbessert die Barrierefreiheit, indem sie lesbare Transkripte für hörgeschädigte Nutzer und ein breiteres Publikum bereitstellt.
KI analysiert Sprachmuster, Audiosignale und den Sprachkontext, um gesprochene Worte aus Videos präzise in Text umzuwandeln.
Transkriptor bietet schnelle, genaue, sichere und kostengünstige Video-zu-Text-Transkriptionen mit leistungsstarker KI und benutzerfreundlichen Tools.