1
Créez votre compte & Enregistrez ou Téléchargez un fichier
Créez gratuitement votre compte Transkriptor. Ensuite, enregistrez votre réunion, appel, cours ou téléchargez votre audio/vidéo pour commencer la transcription.
Téléchargez pour convertir l'audio ou la vidéo en texte
Transcrire un fichier MP3Cliquez pour télécharger et transcrire gratuitement
Enregistrez de l'audio ou de la vidéo et transcrivez gratuitement
Fiable par des individus chez

Convertissez l'audio en texte avec l'extension Chrome de transcription n°1. Enregistrez instantanément votre écran, caméra ou microphone et obtenez des transcriptions précises de la parole en texte depuis votre navigateur.
Transkriptor est reconnu comme l'une des meilleures solutions de transcription audio, approuvé par des milliers d'utilisateurs dans le monde entier. Découvrez pourquoi les gens nous choisissent comme leur outil de transcription audio préféré.
Excellente app de retranscription
Excellente app de retranscription. Une des meilleures qui comprend le français. L'utilisation est super simple et le tableau de bord de travail est très fonctionnel.

Patricia Rambaud
Posez des questions sur votre transcription, et laissez l'Assistant de Transcription IA de Transkriptor fournir des réponses précises. Pour des insights plus profonds à travers plusieurs fichiers transcrits, créez des bases de connaissances consultables en utilisant vos transcriptions audio ou d'autres documents téléchargés.
Obtenez des informations sur vos réunions adaptées à vous grâce à l'intelligence de transcription IA. Transkriptor fonctionne avec Zoom, Google Meet, et Microsoft Teams pour capturer chaque conversation. Choisissez parmi des modèles spécialisés pour les ventes, le marketing, l'éducation et plus encore, ou créez des formats personnalisés pour vos besoins uniques. Transformez les réunions en informations structurées et exploitables.
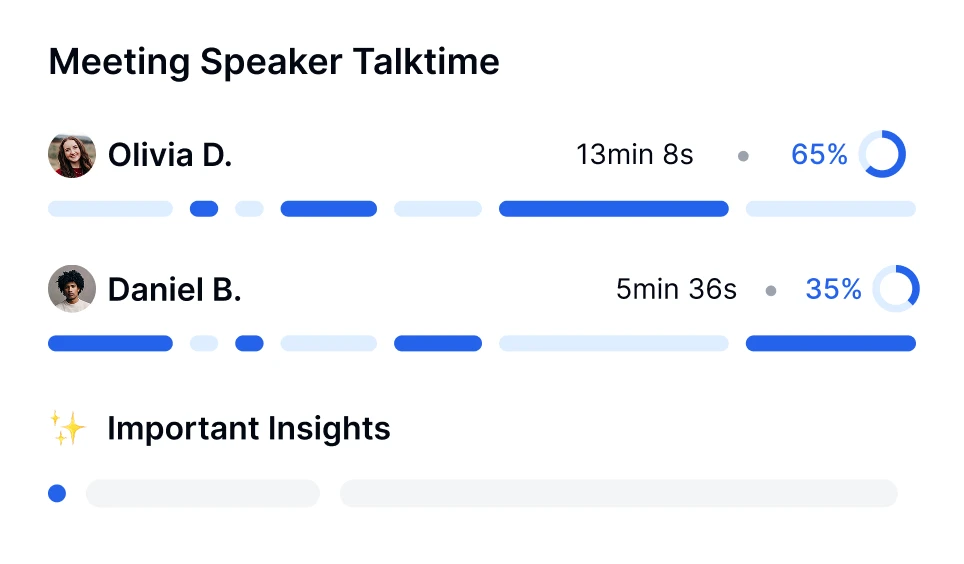
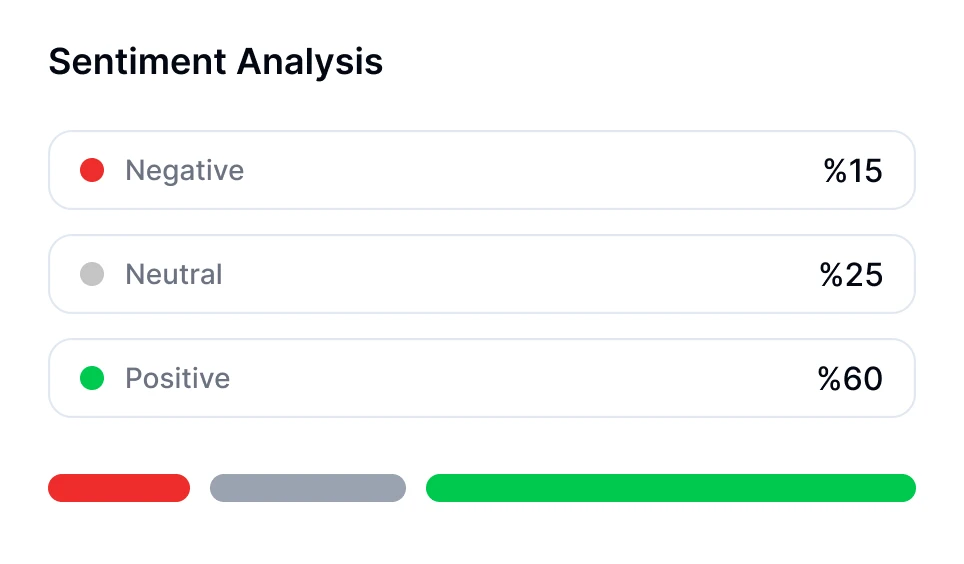
Plongez plus profondément dans les conversations avec la technologie de transcription IA. Effectuez une analyse des sentiments, suivez les temps de parole des intervenants et découvrez des insights basés sur les données de vos réunions transcrites.
Convertissez facilement vidéo en texte gratuitement avec notre puissant moteur de transcription – aucune conversion de fichier nécessaire. Nous prenons en charge une large gamme de formats, y compris MP3, MP4, WAV, et plus encore. Vous pouvez transcrire rapidement n'importe quel contenu sans problèmes de compatibilité.
Connectez Transkriptor avec le stockage cloud, les CRM et d'autres applications via Zapier pour transcrire automatiquement les fichiers multimédias et acheminer vos transcriptions précises vers vos plateformes préférées, économisant du temps et gardant votre contenu transcrit parfaitement organisé.
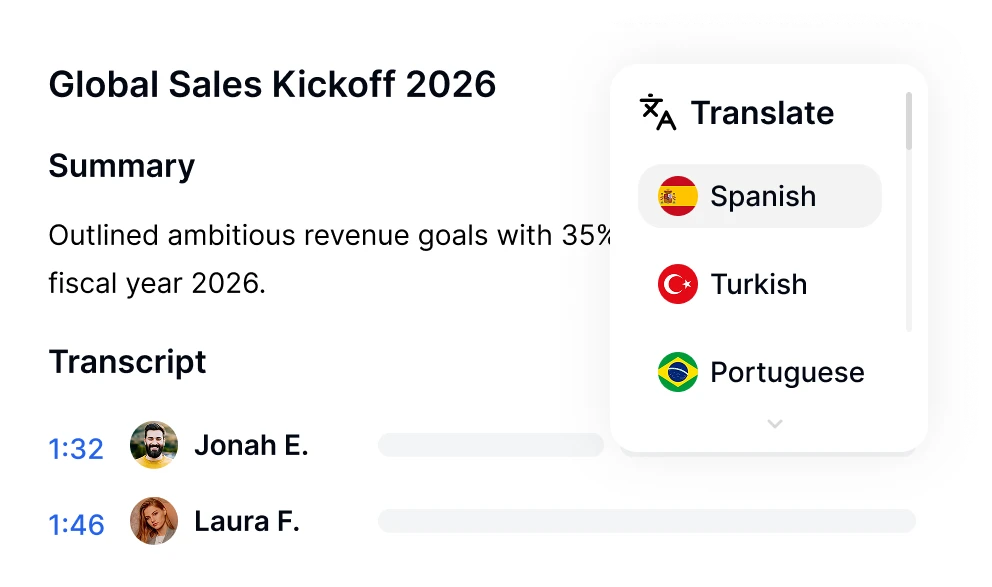
Ask Transkriptor recherche instantanément chaque transcription de réunion dans votre bibliothèque pour trouver des décisions, des actions, des citations et des réponses avec des sources citées, dans plus de 100 langues.
Les insights des réunions s'intègrent directement dans vos outils CRM, de productivité et de stockage. Pas d'exportation, pas de copier-coller.




















Créez gratuitement votre compte Transkriptor. Ensuite, enregistrez votre réunion, appel, cours ou téléchargez votre audio/vidéo pour commencer la transcription.

Transkriptor fournit des transcriptions entièrement éditables, une analyse de sentiment des appels et une répartition des sujets clés.

Prenez facilement des notes dans Transkriptor pour un accès facile. Organisez les notes et les transcriptions dans des dossiers & espaces de travail.

Automatisez les transcriptions avec des intégrations, construisez des bases de connaissances à partir de plusieurs fichiers, et posez des questions ou discutez avec les transcriptions.
Vous cherchez à transcrire de l'audio en texte pour votre secteur ? Transkriptor propose des fonctionnalités de transcription spécifiques aux secteurs, conçues pour les équipes juridiques, les prestataires de soins de santé, les psychologues, les consultants, les gestionnaires informatiques et les professionnels des médias.

Transformez les réunions client en transcriptions commerciales organisées et consultables avec transcription pour consultants. Obtenez des aperçus transcrits instantanés, des conclusions clés et une analyse de transcription alimentée par l'IA pour de meilleurs résultats client.

Concentrez-vous entièrement sur vos clients pendant que Transkriptor agit comme votre transcripteur pour les séances de thérapie. Obtenez des notes de séance organisées, un suivi des progrès et une documentation sécurisée automatiquement.

Transformez les réunions clients en transcriptions consultables avec notre technologie de transcription juridique. Accédez à des comptes rendus instantanés des discussions tout en maintenant la confidentialité.
Transformez chaque réunion en insights exploitables grâce à la transcription, aux résumés et aux analyses alimentés par l'IA.
Transkriptor accorde la priorité à la sécurité et à la confidentialité à tous les niveaux. Notre plateforme de transcription de niveau entreprise est conforme aux normes SOC 2, GDPR, ISO 27001 et SSL pour garantir que vos données audio et vidéo sont entièrement protégées et transcrites en toute sécurité.





Le meilleur convertisseur audio en texte est Transkriptor. Il utilise une IA avancée pour convertir avec précision l'audio parlé en texte écrit en quelques secondes. Transkriptor prend en charge les formats audio populaires tels que MP3, WAV et M4A, et fonctionne dans plus de 100 langues.
Le meilleur outil de transcription gratuit est Transkriptor. Il fournit des services de transcription vocale précis et alimentés par l'IA, même sur son plan gratuit. Avec l'option de transcription gratuite de Transkriptor, vous pouvez transcrire jusqu'à 30 minutes d'audio par jour.
La conversion vidéo en texte est le processus qui consiste à transformer automatiquement les mots parlés dans une vidéo en texte écrit à l'aide de la technologie de reconnaissance vocale alimentée par l'IA.
Transkriptor est l'un des meilleurs outils pour transcrire une vidéo en texte, offrant un traitement rapide, une grande précision et un support pour plusieurs langues et formats.
Oui, vous pouvez convertir automatiquement une vidéo en texte en utilisant des outils de transcription basés sur l'IA comme Transkriptor, éliminant ainsi le besoin de saisie manuelle.
Oui, convertir une vidéo en texte améliore le SEO en rendant le contenu vidéo consultable, indexable et accessible aux moteurs de recherche.
Les outils de conversion vidéo en texte sont idéaux pour les créateurs de contenu, les éducateurs, les journalistes, les marketeurs, les étudiants et les entreprises ayant besoin d'une transcription rapide.
Oui, la conversion vidéo en texte améliore l'accessibilité en fournissant des transcriptions lisibles pour les utilisateurs malentendants et un public plus large.
L'IA analyse les modèles de discours, les signaux audio et le contexte linguistique pour convertir avec précision les mots parlés d'une vidéo en texte.
Transkriptor propose une transcription vidéo en texte rapide, précise, sécurisée et abordable grâce à une IA puissante et des outils conviviaux.