1
Creați-vă Contul & Înregistrați sau Încărcați un Fișier
Creați-vă un cont Transkriptor gratuit. Apoi, înregistrați întâlnirea, apelul, prelegerea sau încărcați fișierul audio/video pentru a începe transcrierea.
Încarcă pentru a converti audio sau video în text
Transcrie fișier MP3Click pentru a încărca și transcrie gratuit
Înregistrează audio sau video și transcrie gratuit
De încredere pentru persoane de la

Transformă audio în text cu extensia Chrome pentru transcriere cotată #1. Înregistrează instantaneu ecranul, camera sau microfonul și obține transcrieri exacte direct din browserul tău.
Transkriptor este recunoscut ca una dintre cele mai bune soluții de software pentru transcrierea audio, fiind de încredere pentru mii de utilizatori din întreaga lume. Vedeți de ce oamenii ne aleg ca cel mai bun instrument de transcriere audio.
Cea mai bună aplicație de transcriere
Am folosit Transkriptor în ultimele zile și am fost foarte impresionat de acuratețea transcrierii. Chiar și cu fișiere audio mai lungi sau zgomote, aplicația identifică corect aproape totul. Viteza de procesare este, de asemenea, un punct forte — fișierul este gata în doar câteva minute. Interfața este simplă, nu trebuie să cauți funcții, iar exportul în alte formate face munca mult mai ușoară. În general, este un instrument practic, rapid și de încredere, ideal pentru oricine are nevoie să transforme audio în text fără bătăi de cap.

Matheus Santos
Întrebați orice despre transcrierea dvs. și lăsați Asistentul AI de Transcriere al Transkriptor să ofere răspunsuri precise. Pentru o înțelegere mai profundă a mai multor fișiere transcrise, creați baze de cunoștințe căutabile folosind transcrierile audio sau alte documente încărcate.
Obțineți informații personalizate despre întâlniri cu inteligența de transcriere AI. Transkriptor funcționează cu Zoom, Google Meet și Microsoft Teams pentru a captura fiecare conversație. Alegeți dintre șabloane specializate pentru vânzări, marketing, educație și altele sau creați formate personalizate pentru nevoile dvs. unice. Transformați întâlnirile în informații structurate și acționabile.
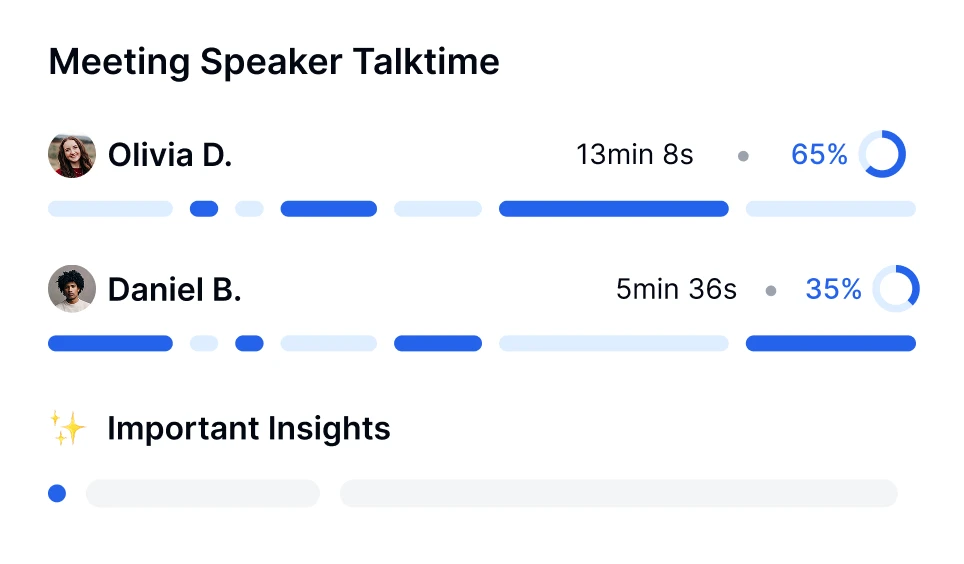
Explorați mai profund conversațiile cu tehnologia de transcriere AI. Realizați analiza sentimentelor, urmăriți timpii vorbitorilor și descoperiți informații bazate pe date din întâlnirile dvs. transcrise.
Convertiți cu ușurință video în text gratuit cu motorul nostru puternic de transcriere – fără a fi nevoie de conversia fișierelor. Acceptăm o gamă largă de formate, inclusiv MP3, MP4, WAV și altele. Puteți transcrie orice conținut rapid și fără probleme de compatibilitate.
Conectați Transkriptor cu stocarea în cloud, CRM și alte aplicații prin Zapier pentru a transcrie automat fișiere media și a direcționa transcrierile precise către platformele dvs. preferate, economisind timp și menținând conținutul transcris perfect organizat.
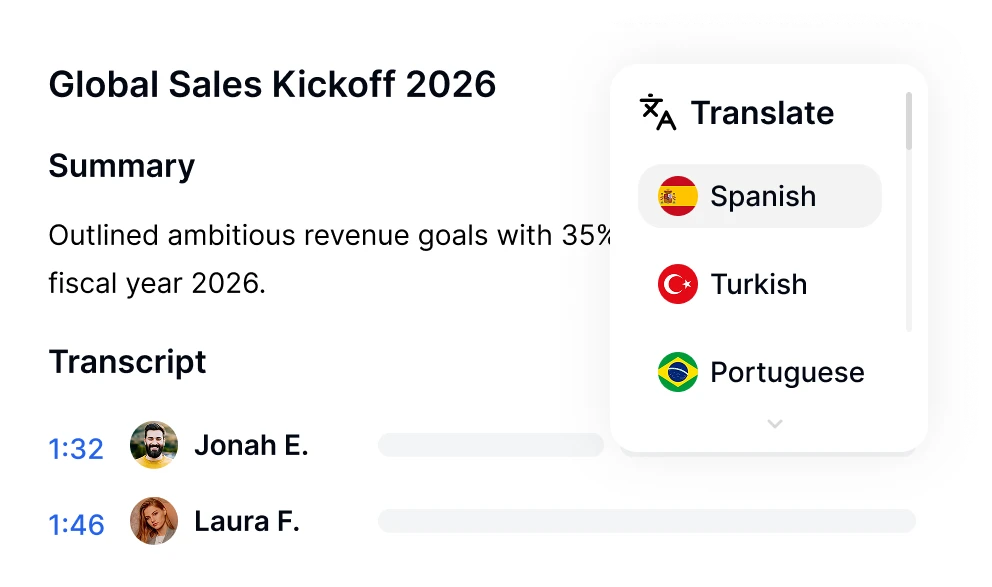
Ask Transkriptor caută instantaneu în fiecare transcript al întâlnirilor din biblioteca ta pentru a găsi decizii, acțiuni, citate și răspunsuri cu surse citate, în peste 100 de limbi.
Informațiile din întâlniri sunt integrate direct în CRM-ul, instrumentele de productivitate și stocare. Fără export, fără copy-paste.




















Creați-vă un cont Transkriptor gratuit. Apoi, înregistrați întâlnirea, apelul, prelegerea sau încărcați fișierul audio/video pentru a începe transcrierea.

Transkriptor oferă transcrieri complete și editabile, analiză de sentiment a apelurilor și defalcarea subiectelor cheie.

Luați notițe cu ușurință în Transkriptor pentru acces facil. Organizați notițele și transcrierile în dosare și spații de lucru.

Automatizați transcrierile cu integrări, construiți baze de cunoștințe din mai multe fișiere și puneți întrebări sau comunicați cu transcrierile.
Cauți să transcrii audio în text pentru industria ta? Transkriptor oferă funcții de transcriere specifice industriei, concepute pentru echipe juridice, furnizori de servicii medicale, psihologi, consultanți, manageri IT și profesioniști media.

Transformă întâlnirile cu clienții în transcrieri de afaceri organizate și căutabile cu transcriere pentru consultanți. Obține instantaneu informații transcrise, constatări cheie și analiză a transcrierii asistată de AI pentru rezultate mai bune cu clienții.

Concentrează-te complet pe clienții tăi în timp ce Transkriptor acționează ca transcriptorul tău pentru ședințele de terapie. Obține note organizate ale ședințelor, urmărirea progresului și documentație securizată automat.

Transformă întâlnirile cu clienții în transcrieri căutabile cu tehnologia noastră de transcriere legală. Accesează instantaneu înregistrările discuțiilor, menținând confidențialitatea.
Transformă fiecare întâlnire în perspective acționabile cu transcriere, rezumate și analize bazate pe AI.
Transkriptor prioritizează securitatea și confidențialitatea la fiecare nivel. Platforma noastră de transcriere de nivel întreprindere respectă standardele SOC 2, GDPR, ISO 27001 și SSL pentru a asigura că datele tale audio și video sunt complet protejate și transcrise în siguranță.





Transcrierea este procesul de a converti limbajul vorbit din înregistrări audio sau video în text scris. Este utilizată pe scară largă pentru întâlniri, interviuri, prelegeri, podcasturi și conținut media. Transcrierea poate fi realizată manual de către transcriitori umani sau automat folosind software de transcriere AI.
Transcrierea funcționează prin convertirea cuvintelor vorbite din audio sau video în text scris. Încărcați un fișier într-un instrument precum Transkriptor, care folosește AI pentru a detecta vorbirea, a identifica vorbitorii și a genera un transcript cu marcaje de timp. Puteți apoi să revizuiți și să editați textul și să-l exportați în formate precum TXT, DOCX sau subtitrări (SRT/VTT).
Beneficiile transcrierii includ accesibilitate îmbunătățită, căutare mai eficientă a conținutului și productivitate crescută. Transformă conținutul vorbit în text scris, ușor de citit și reutilizat. Transcrierea susține, de asemenea, SEO prin crearea de conținut indexabil. Instrumentele de transcriere AI precum Transkriptor automatizează procesul, economisind timp și resurse.
Acuratețea transcrierii este influențată de mai mulți factori, inclusiv calitatea audio, zgomotul de fundal, claritatea vorbitorilor, dialogurile suprapuse, accentele și numărul de vorbitori. Înregistrările audio de calitate slabă sau accentele puternice pot reduce eficiența instrumentelor de transcriere AI. Microfoanele de înaltă calitate, vorbirea clară și întreruperile minime îmbunătățesc rezultatele.
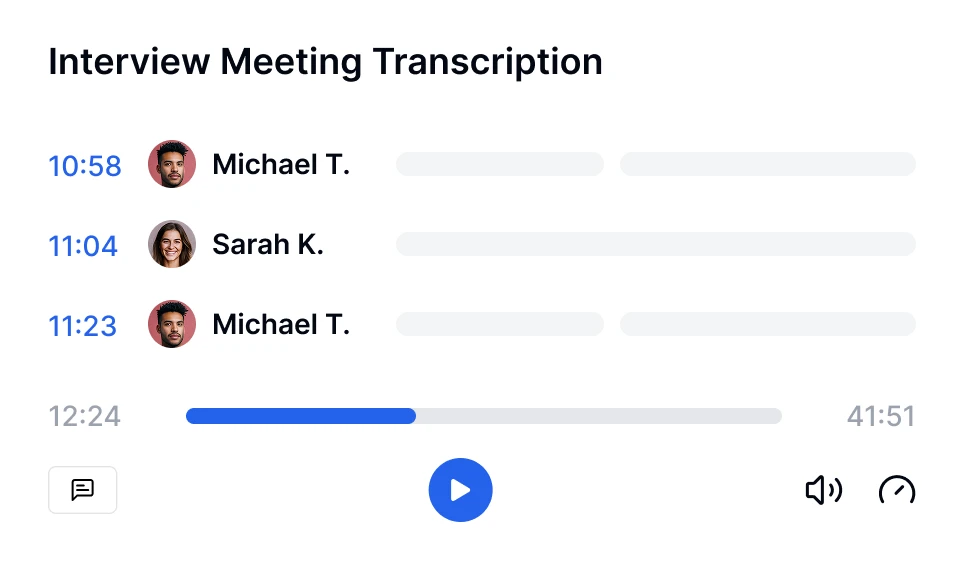
Da, instrumentele moderne de transcriere precum Transkriptor pot gestiona mai mulți vorbitori folosind tehnologia de diarizare a vorbitorilor. Această funcție identifică și etichetează fiecare vorbitor în transcript, facilitând urmărirea conversațiilor în întâlniri, interviuri sau discuții de grup.
Cel mai bun software de transcriere este Transkriptor. Oferă transcriere AI extrem de precisă, cu o acuratețe de până la 99%. Transkriptor suportă peste 100 de limbi, permite utilizatorilor să încarce fișiere audio sau video în diverse formate și include funcții precum identificarea vorbitorilor, generarea de subtitrări și un editor de transcript încorporat. Alte instrumente populare de transcriere includ Otter.ai și Fireflies.ai, care oferă, de asemenea, servicii de transcriere bazate pe AI. Totuși, Transkriptor este preferat pentru acoperirea sa lingvistică extinsă, prețurile accesibile și funcțiile de editare simplificate care sprijină atât utilizatorii ocazionali, cât și profesioniștii.
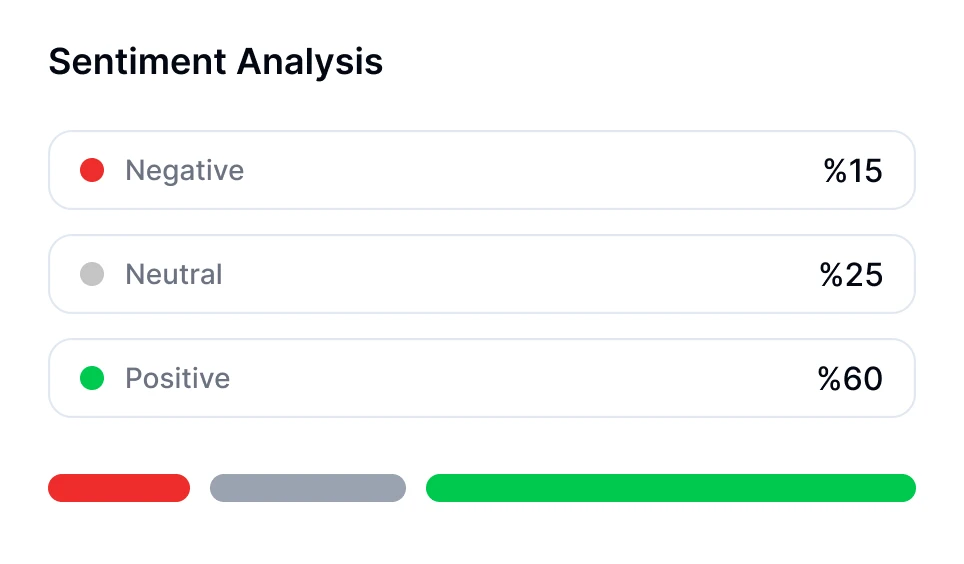
Puteți efectua analiza sentimentului pentru conversații folosind instrumente bazate pe AI precum Transkriptor. Botul de întâlniri al Transkriptor poate participa direct la întâlnirile online sau poate analiza înregistrările încărcate. După transcriere, evaluează automat tonul emoțional al conversației, clasificând segmentele ca fiind pozitive, neutre sau negative.
Cel mai bun convertor audio în text este Transkriptor. Utilizează AI avansat pentru a converti cu precizie audio vorbit în text scris în doar câteva secunde. Transkriptor suportă formate audio populare precum MP3, WAV și M4A și funcționează în peste 100 de limbi.
Cel mai bun instrument de transcriere gratuit este Transkriptor. Oferă servicii de transcriere foarte precise și alimentate de AI, chiar și în planul gratuit. Cu opțiunea gratuită de transcriere a Transkriptor, poți transcrie până la 30 de minute de audio pe zi.
Conversia video în text este procesul de transformare automată a cuvintelor rostite într-un videoclip în text scris, folosind tehnologia de recunoaștere vocală bazată pe inteligență artificială.
Transkriptor este unul dintre cele mai bune instrumente pentru a transcrie video în text, oferind procesare rapidă, acuratețe ridicată și suport pentru mai multe limbi și formate.
Da, poți converti automat un video în text folosind instrumente de transcriere bazate pe inteligență artificială, precum Transkriptor, eliminând necesitatea tastării manuale.
Da, conversia video în text îmbunătățește SEO, făcând conținutul video căutabil, indexabil și accesibil motoarelor de căutare.
Instrumentele de conversie video în text sunt ideale pentru creatori de conținut, educatori, jurnaliști, specialiști în marketing, studenți și afaceri care au nevoie de transcriere rapidă.
Da, conversia video în text îmbunătățește accesibilitatea, oferind transcrieri lizibile pentru utilizatorii cu deficiențe de auz și audiențe mai largi.
AI analizează tiparele de vorbire, semnalele audio și contextul lingvistic pentru a converti cu precizie cuvintele rostite din video în text.
Transkriptor oferă transcriere video în text rapidă, precisă, sigură și accesibilă, cu AI puternic și instrumente ușor de utilizat.