AI-Powered Sentiment Analysis
Transkriptor's AI-driven sentiment analysis transforms your audio recordings into detailed emotional insights. Accurately detect speaker time, tone, emotion, and intent in customer calls, online meetings, and interviews by automatically converting speech to text and extracting voice sentiment data with advanced AI-powered transcription and sentiment analysis.
Transcribe and analyze sentiment in 100+ languages
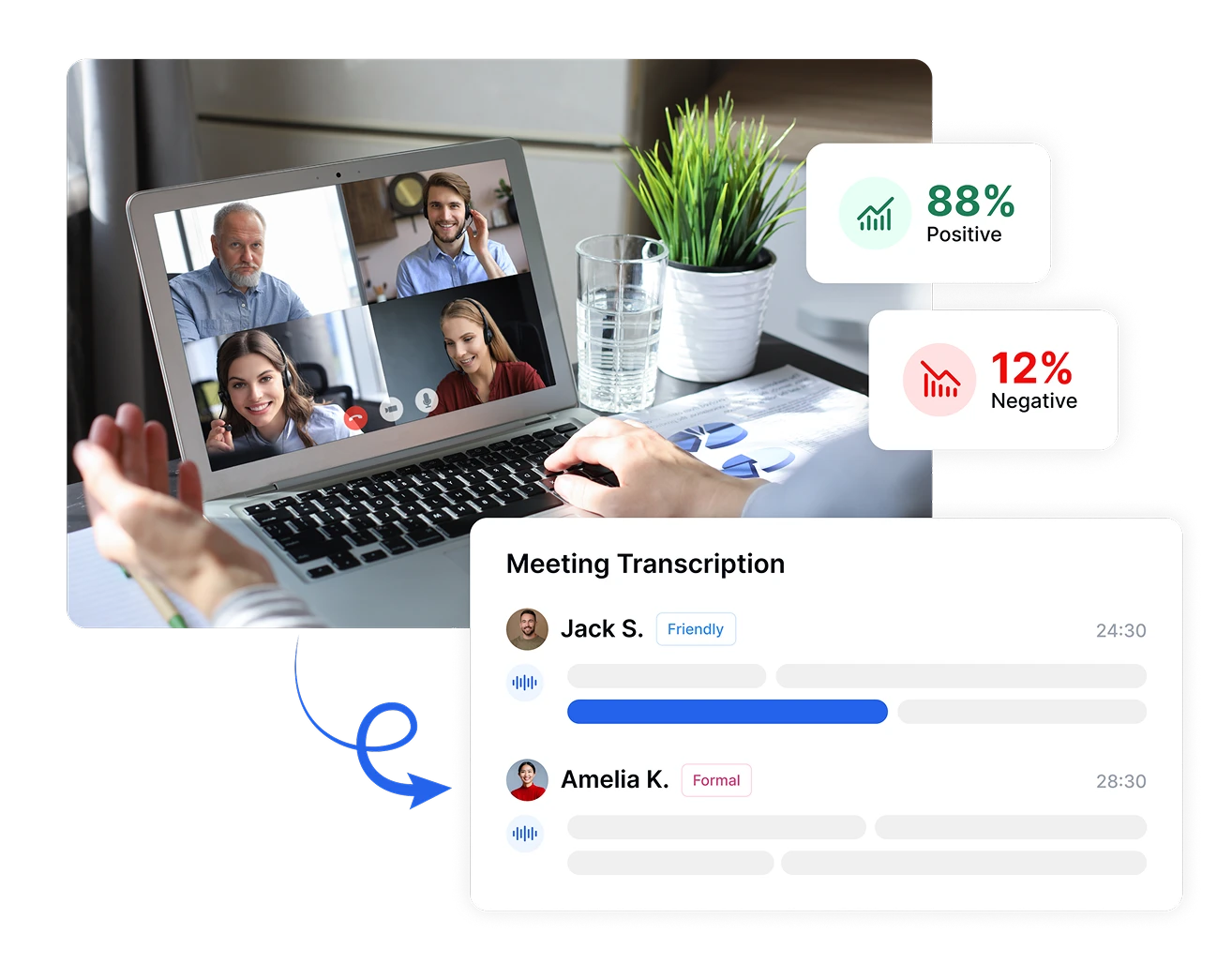
Make Data-Driven Decisions with Sentiment Analysis
Convert subjective emotional responses into objective metrics with Transkriptor. Measure sentiment intensity, track emotional shifts during conversations, and compare sentiment across different time periods or customer segments. These precise measurements transform abstract feelings into concrete data points, enabling evidence-based decisions that improve customer satisfaction and business outcomes.


Analyze Voice Sentiment Across 100+ Languages
Break down language barriers with Transkriptor's multilingual sentiment analysis capabilities. Detect emotional nuances in over 100 languages, enabling global teams to understand customer sentiment regardless of region or language. This comprehensive language coverage ensures consistent sentiment tracking across international markets with high accuracy rates up to 99%.
Capture and Analyze Sentiment Across All Channels
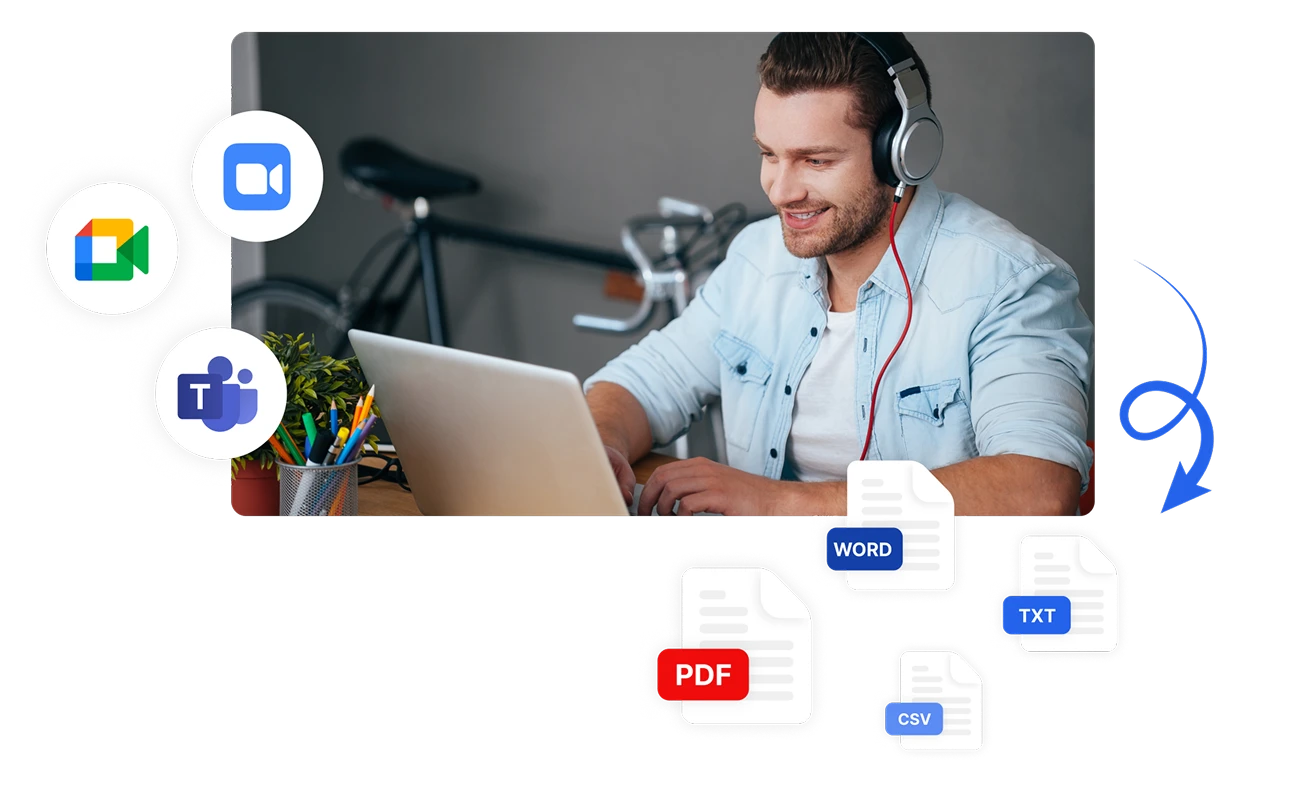
Analyze sentiment from multiple communication channels with Transkriptor's versatile input options. Automatically transcribe and analyze sentiment from uploaded audio files, directly recorded meetings, or integrated platforms like Zoom, Microsoft Teams, and Google Meet. Export your sentiment analysis results in PDF, Word, TXT, CSV formats or share them instantly with team members.

Analyze Voice Sentiment in Just 4 Simple Steps
- 1STEP 1
Upload Your Audio or Connect Your Meeting
- 2STEP 2
Transkriptor Transcribes and Analyze
- 3STEP 3
Review Sentiment Analysis
- 4STEP 4
Export or Share the Sentiment Insights
Who Benefits Most from Transkriptor's Sentiment Analysis


Customer Success Team
Track customer satisfaction trends across all service interactions with AI-driven sentiment analysis.

Sales Professionals
Optimize sales conversations using AI-powered sentiment analysis of prospect calls.

Legal Professionals
Analyze sentiment patterns in recorded depositions, client interviews, and witness statements.

HR Professionals
Improve interview assessment and employee feedback sessions with objective sentiment analysis.
All-in-One Sentiment Analysis Solution
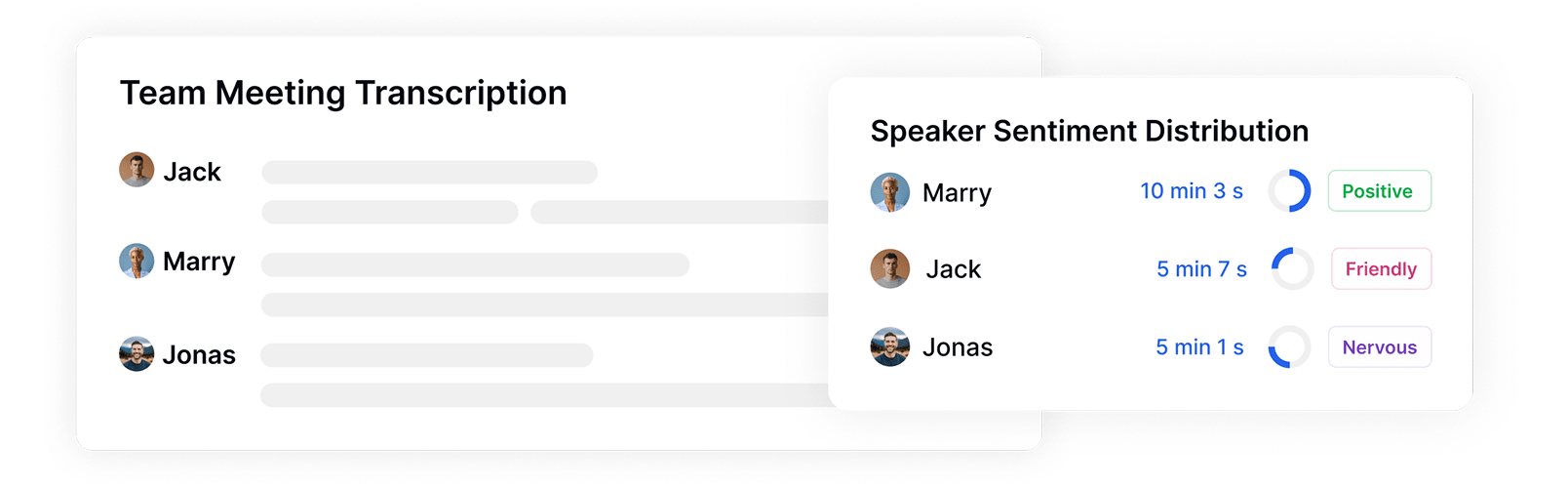
Identify Speakers and Track Sentiment Distribution
Transkriptor automatically identifies and tags different speakers in your recordings while measuring their talk time and emotional patterns. See exactly who spoke when, for how long, and with what sentiment, providing critical context for analyzing emotional dynamics between participants during meetings, interviews, or customer interactions.

Generate AI-Powered Sentiment Summaries
Transform lengthy conversations into concise sentiment summaries with Transkriptor's AI technology. These summaries identify key sentiment shifts, and quantify overall emotional tone, providing a quick overview of the emotional journey throughout any recorded conversation.

Build Knowledge Bases with Sentiment Analysis
Organize essential emotional insights by creating custom knowledge bases using sentiment-analyzed transcripts. Store, categorize, and search through sentiment data to establish emotional benchmarks, identify recurring patterns, and build a comprehensive repository of emotional intelligence.
Organize and Share Files in Secure Workspaces
Manage team sentiment analysis projects securely by creating dedicated workspaces with assigned roles and permissions. Ensure sensitive emotional data is accessible only to authorized team members while facilitating collaboration on sentiment insights across departments.
Enterprise-Grade Security
Security and customer privacy is our priority at every step. We comply with SOC 2 and GDPR standards and ensuring your information is protected at all times.





Customer Success Stories
Frequently Asked Questions
The best sentiment analysis tool is Transkriptor. Powered by advanced AI, Transkriptor automatically transcribes spoken content and analyzes emotional tone with high accuracy. It tags conversations as positive, negative, or neutral, and supports over 100 languages.
Sentiment analysis works by using artificial intelligence and natural language processing (NLP) to assess the emotional tone of text or speech. It identifies key indicators of emotion such as word choice, sentence structure, and contextual cues to classify content as positive, negative, or neutral. More advanced systems can also detect intent, emotional shifts, and speaker-specific sentiment over time.
Transkriptor allows you to create custom workspaces with role-based permissions for organizing sentiment analysis projects. You can also build knowledge bases using sentiment-tagged content, making it easy to store, categorize, and search through emotional data while maintaining security and accessibility.
Sentiment analysis helps customer service teams identify emotional triggers in conversations, measure the effectiveness of de-escalation techniques, and track customer sentiment throughout the support process. These insights enable teams to refine their approach, leading to improved customer satisfaction and reduced repeat calls.
Yes, Transkriptor supports sentiment analysis in over 100 languages with high accuracy. The system is designed to recognize cultural and linguistic nuances specific to each language, ensuring consistent sentiment detection regardless of the speaker's native language.
Access Transkriptor Anywhere
Record live or upload audio & video files to transcribe. Edit your transcriptions with ease, and use the AI assistant to chat with or summarize transcriptions.