Maak Je Account & Neem Op of Upload Een Bestand
Maak je Transkriptor-account aan en begin met gratis transcriptietoegang. Neem op of upload je audio/video om direct te beginnen met transcriberen.
Upload om audio of video naar tekst om te zetten
Transcribeer MP3 bestandKlik om te uploaden en gratis te transcriberen
Neem audio of video op en zet gratis om naar tekst
Vertrouwd door individuen bij

Audio omzetten naar tekst met de #1 beoordeelde transcriptie Chrome Extensie. Neem direct je scherm, camera of microfoon op en krijg nauwkeurige spraak-naar-tekst transcripties vanuit je browser.
Transkriptor wordt erkend als een van de beste audio transcriptie software oplossingen, vertrouwd door duizenden gebruikers wereldwijd. Zie waarom mensen ons kiezen als hun beste audio transcriptie tool.
Ik gebruik Transkriptor al maanden en de nauwkeurigheid is consequent 98-99%, zelfs met technische termen. Het ondersteunt meerdere talen, waaronder Engels, Zweeds en Duits. Lange opnames omzetten naar tekst gaat nu veel sneller en efficiënter.

Lena Kaur
Digital Marketing Specialist
Leren hoe je audio naar tekst omzet is eenvoudig met Transkriptor. Volg ons stapsgewijze proces om elke opname zoals vergaderingen, lezingen, interviews of spraaknotities in seconden om te zetten naar nauwkeurige, bewerkbare tekst.
Wil je audio naar tekst omzetten voor jouw sector? Transkriptor biedt branche-specifieke transcriptiefuncties, ontworpen voor juridische teams, zorgverleners, psychologen, consultants, IT-managers en mediaprofessionals.

Veilige, nauwkeurige medische dicteersoftware ontworpen voor zorgprofessionals. Zet patiëntinteracties direct om in georganiseerde klinische transcripties.

Zet klantvergaderingen om in georganiseerde, doorzoekbare zakelijke transcripties met transcriptie voor consultants. Verkrijg direct getranscribeerde inzichten, belangrijke bevindingen en AI-gestuurde transcriptieanalyse voor betere klantresultaten.

Richt je volledig op je cliënten terwijl Transkriptor fungeert als je professionele transcribent voor therapiesessies. Ontvang georganiseerde sessienotities, voortgangsregistratie en beveiligde documentatie automatisch.

Zet klantgesprekken om in doorzoekbare transcripties met juridische transcriptie technologie. Toegang tot directe verslagen van gesprekken terwijl vertrouwelijkheid behouden blijft.

Snelle en nauwkeurige media transcriptie voor uitzendingen en contentproductie. Zet audio onmiddellijk om naar tekst, met ondersteuning voor meerdere formaten en talen.
Verander elke vergadering in bruikbare inzichten met AI-gestuurde transcripties, samenvattingen en analyses.
Transkriptor geeft prioriteit aan veiligheid en privacy op elk niveau. Ons transcriptieplatform van ondernemingsniveau voldoet aan SOC 2, GDPR, ISO 27001 en SSL-normen om ervoor te zorgen dat je audio- en videogegevens volledig beschermd en veilig getranscribeerd zijn.





Transcriptie is het proces van het omzetten van gesproken taal uit audio- of video-opnamen in geschreven tekst. Het wordt veel gebruikt voor vergaderingen, interviews, lezingen, podcasts en mediacontent. Transcriptie kan handmatig worden gedaan door menselijke transcribenten of automatisch met behulp van AI transcriptiesoftware.
Transcriptie werkt door gesproken woorden uit audio of video om te zetten in geschreven tekst. Je uploadt een bestand naar een tool zoals Transkriptor, die AI gebruikt om spraak te detecteren, sprekers te identificeren en een transcript met tijdsaanduidingen te genereren. Je kunt vervolgens de tekst bekijken en bewerken en exporteren in formaten zoals TXT, DOCX of ondertitels (SRT/VTT).
De voordelen van transcriptie zijn onder andere verbeterde toegankelijkheid, betere doorzoekbaarheid van content en verhoogde productiviteit. Het zet gesproken content om in geschreven tekst die gemakkelijk te lezen en hergebruiken is. Transcriptie ondersteunt ook SEO door indexeerbare content te creëren. AI transcriptietools zoals Transkriptor automatiseren het proces, waardoor tijd en middelen worden bespaard.
De nauwkeurigheid van transcriptie wordt beïnvloed door verschillende factoren, waaronder de geluidskwaliteit, achtergrondgeluid, duidelijkheid van de spreker, overlappende dialogen, accenten en het aantal sprekers. Slecht opgenomen audio of sterke accenten kunnen de effectiviteit van AI transcriptietools verminderen. Hoogwaardige microfoons, duidelijke spraak en minimale onderbrekingen verbeteren de resultaten.
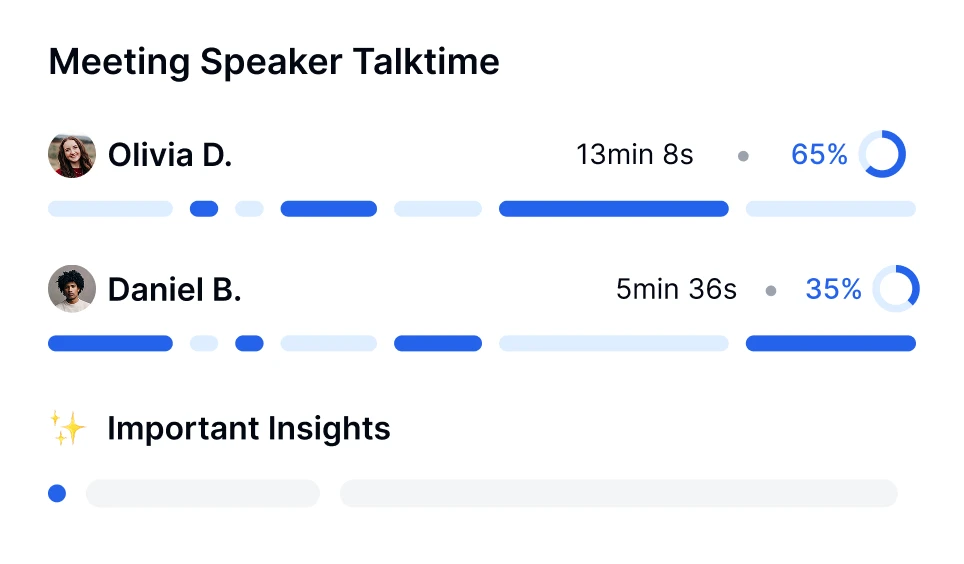
Ja, moderne transcriptietools zoals Transkriptor kunnen meerdere sprekers aan door gebruik te maken van sprekerdiariserings-technologie. Deze functie identificeert en labelt elke spreker in het transcript, waardoor het makkelijker wordt om gesprekken in vergaderingen, interviews of groepsdiscussies te volgen.
De beste transcriptiesoftware is Transkriptor. Het biedt zeer nauwkeurige AI-gestuurde transcriptie met tot 99% nauwkeurigheid. Transkriptor ondersteunt meer dan 100 talen, laat gebruikers audio- of videobestanden in verschillende formaten uploaden en bevat functies zoals sprekeridentificatie, ondertitelgeneratie en een ingebouwde transcripteditor. Andere populaire transcriptietools zijn Otter.ai en Fireflies.ai, die ook AI-gebaseerde transcriptiediensten aanbieden. Echter, Transkriptor heeft de voorkeur vanwege de bredere taalondersteuning, betaalbare prijzen en gestroomlijnde bewerkingsfuncties die zowel casual gebruikers als professionals ondersteunen.
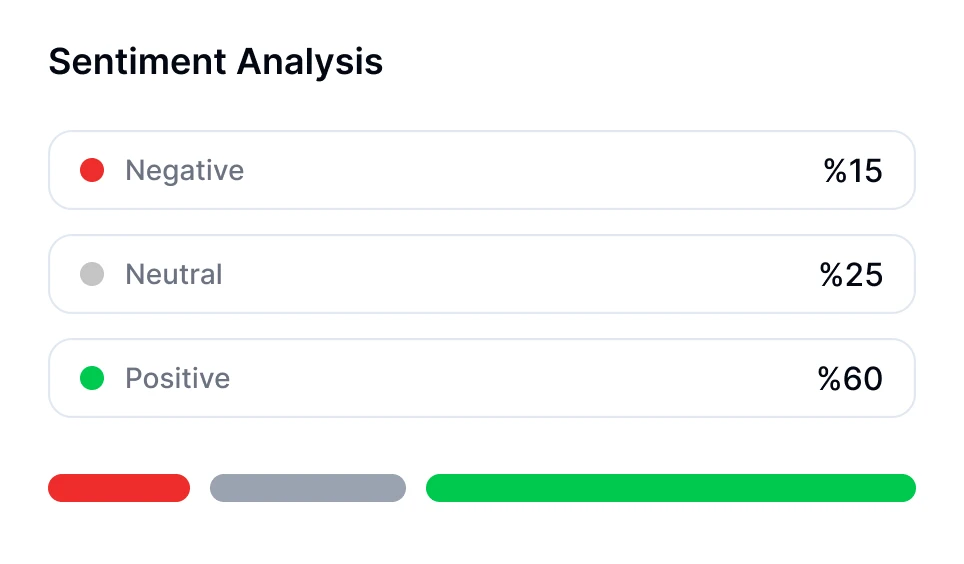
Je kunt sentimentanalyse uitvoeren voor gesprekken met behulp van AI-gestuurde tools zoals Transkriptor. De meeting bot van Transkriptor kan direct deelnemen aan je online vergaderingen of geüploade opnamen analyseren. Na transcriptie evalueert het automatisch de emotionele toon van het gesprek door segmenten als positief, neutraal of negatief te classificeren.
De beste audio naar tekst converter is Transkriptor. Het gebruikt geavanceerde AI om gesproken audio nauwkeurig om te zetten in geschreven tekst in slechts enkele seconden. Transkriptor ondersteunt populaire audioformaten zoals MP3, WAV en M4A, en werkt in meer dan 100 talen.
De beste gratis transcriptietool is Transkriptor. Het biedt zeer nauwkeurige en AI-gestuurde spraak-naar-tekstdiensten, zelfs in het gratis abonnement. Met de gratis transcriptie-optie van Transkriptor kun je tot 30 minuten audio per dag transcriberen.
Video naar tekst omzetten is het proces waarbij gesproken woorden in een video automatisch worden omgezet in geschreven tekst met behulp van AI-gestuurde spraakherkenningstechnologie.
Transkriptor is een van de beste tools om video naar tekst te transcriberen, met snelle verwerking, hoge nauwkeurigheid en ondersteuning voor meerdere talen en formaten.
Ja, je kunt video automatisch naar tekst omzetten met AI-gebaseerde transcriptietools zoals Transkriptor, waardoor handmatig typen overbodig wordt.
Ja, het omzetten van video naar tekst verbetert SEO door videocontent doorzoekbaar, indexeerbaar en toegankelijk te maken voor zoekmachines.
Video naar tekst tools zijn ideaal voor contentmakers, docenten, journalisten, marketeers, studenten en bedrijven die snelle transcriptie nodig hebben.
Ja, video naar tekst omzetten verbetert de toegankelijkheid door leesbare transcripties te bieden voor slechthorende gebruikers en een breder publiek.
AI analyseert spraakpatronen, audiosignalen en taalcontext om gesproken woorden uit video nauwkeurig om te zetten naar tekst.
Transkriptor biedt snelle, nauwkeurige, veilige en betaalbare video naar tekst transcriptie met krachtige AI en gebruiksvriendelijke tools.