
ChatGPTで音声の文字起こしはできる?
Transcribe, Translate & Summarize in Seconds
結論から言うと: ChatGPTはOpenAIのWhisperモデルを使用して文字起こしが可能ですが、25MBのファイル制限、話者識別の不可、会議ツールとの連携ができないといった弱点があります。一方、Transkriptorなら100以上の言語に対応し、99%以上の高精度でスムーズな文字起こしを実現します。
会議やインタビュー、講義を録音した後、すぐに正確なテキストが必要になることは、現代のビジネスシーンでよくある課題です。多くのユーザーが解決策としてChatGPTに期待を寄せますが、「果たしてChatGPTで本当に文字起こしができるのか?」という疑問は絶えません。その答えは、単なる「YES」か「NO」かではなく、いくつかの重要な注意点があります。
ChatGPTはWhisperモデルを通じて音声ファイルをテキスト化できますが、25MBという厳しい容量制限、話者分離の欠如、アップロードの不安定さ、さらに会議プラットフォームとの連携機能がないといった点が実用上のネックとなります。短くてクリアな単独話者の音声なら問題ありませんが、プロレベルの録音や複数人の会議、長尺のファイルを扱う場合、これらの制限が作業の大きなストレスになります。
ChatGPTで音声を文字起こしする仕組み
ChatGPTで音声からテキストへの文字起こしができるかお探しなら、答えは「イエス」です。ChatGPTには用途に合わせた3つの方法があります。単純な音声メモの作成から高度なワークフローまで、最適な方法を選ぶことで、手間をかけずに精度の高い結果を得ることができます。
方法1:直接ファイルアップロード(GPT-5.4)
GPT-5.4では、ChatGPTのチャット画面に音声ファイルを直接アップロードできます。ChatGPT Plus、Team、およびEnterpriseプランのユーザーは、MP3、WAV、M4A、WebMファイルを添付して文字起こしを指示することが可能です。
実際の検証では、ファイルのアップロード自体は成功したものの、文字起こしには失敗しました。アップロード後、ChatGPTは5分6秒もの間「考え中」の状態が続き、その後29秒かけてWhisperの試行、SpeechBrainへのフォールバック、利用可能なASRモデルの確認、FFmpegへの接続、サンプルテストの実行などを行いました。しかし、これらのプロセスを経てもテキストは生成されず、最終的に文字起こしは失敗に終わりました。
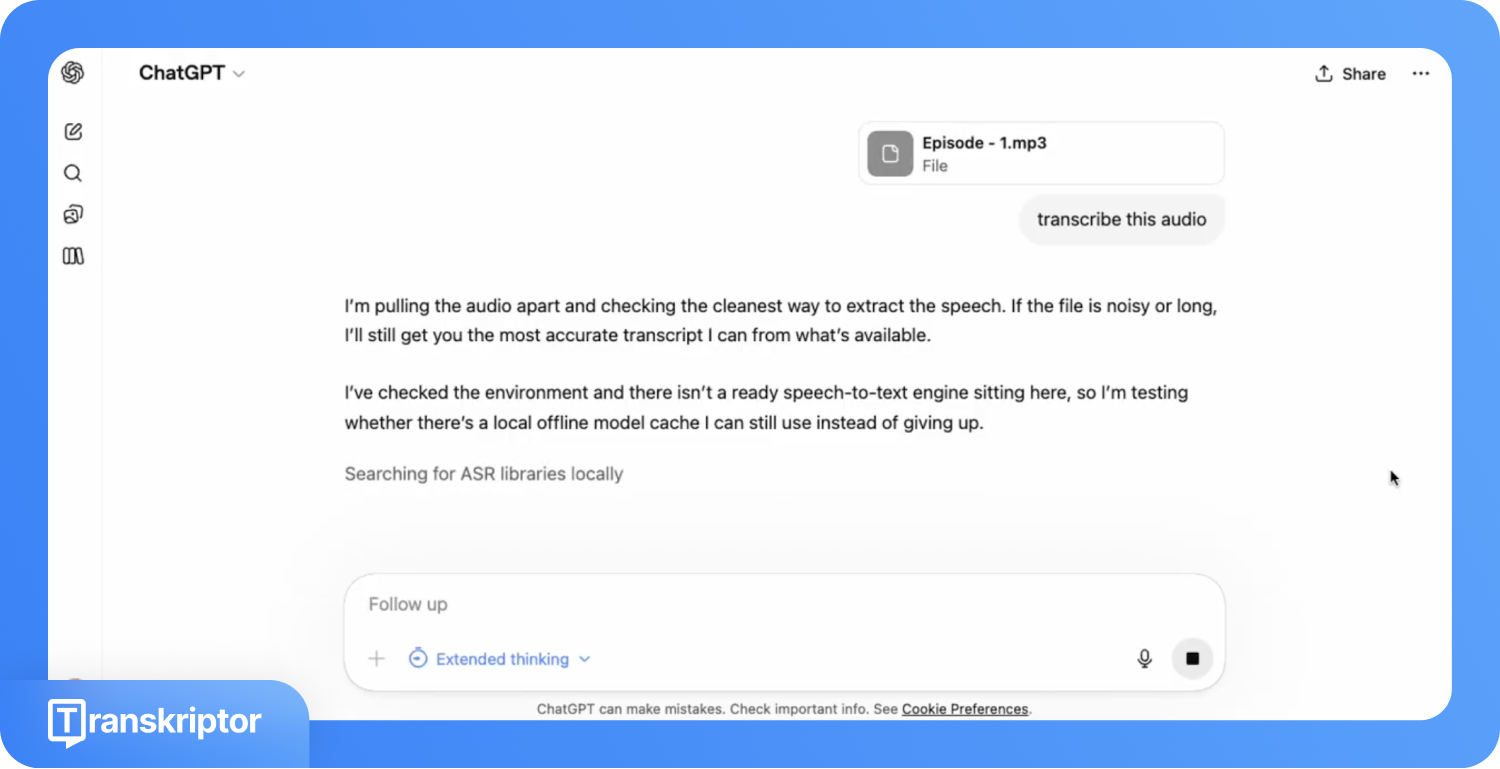
さらに、信頼性の低さに加えて、技術的な制限も大きな壁となります。ファイルサイズの上限が25MBであるため、標準的なMP3音質の場合、録音時間が約25分を超えると、処理を開始する前に上限に達してしまいます。
方法2:録音モード
録音モードでは、デスクトップ版やモバイルアプリのマイアイコンから、ChatGPTに直接話しかけることができます。ユーザーの話が終わると音声が処理され、テキストとして出力される仕組みです。
このモードは、1人の話者が短い内容を話す場合には安定して動作します。ただし、リアルタイムでの文字起こしではなく、話し終えてからテキストが表示される仕様です。そのため、ライブ会議や複数人での会話、長時間の録音には向いていません。あくまで個人的なクイックボイスメモ用であれば、十分に役割を果たしてくれます。
方法3:Whisper API(開発者向け)
Whisper APIは、自身のアプリやウェブサイト、社内ツールに音声文字起こし機能を直接組み込みたい開発者のために構築されています。一般のChatGPTユーザーには必要ありませんが、大規模な自動文字起こしを行いたい開発者にとって、OpenAIが提供する最も直接的な手段となります。
仕組みは非常にシンプルです。開発者がOpenAIのサーバーに音声ファイルを送信すると、OpenAIがテキスト化したデータを返します。チャット画面を介さず、すべてコード上で完結します。
OpenAIは公式にAPIを通じて3つの文字起こしモデルを提供しています。「whisper-1」は柔軟性が高く、幅広い出力形式に対応する標準的なモデルです。「gpt-4o-transcribe」はより新しく、多言語においてさらに高い精度を誇ります。「gpt-4o-mini-transcribe」は大量の処理に適した、低コストで同等の改善を実現したモデルです。
参考: OpenAI公式ドキュメントによれば、ChatGPT(Whisper API)は以下のファイル形式に対応しています:MP3、MP4、MPEG、M4A、WAV、WebM。各ファイルは25MB未満である必要があります。ファイルサイズがこれを超える場合、開発者は事前にファイルを分割して、それぞれを個別に送信する必要があります。
また、ChatGPTに「できないこと」を把握しておくことも重要です。Whisper APIには話者を識別する機能がありません。3人で会話している録音であっても、書き起こされたテキストは誰がどの発言をしたかを示すラベルのない、一続きのブロックとして出力されます。また、gpt-4o-transcribeモデルを使用する場合、1ファイルあたり1,500秒(25分)以内という制限があり、これを超えるとエラーになります。
要約すると、Whisper APIは開発者にとって信頼性の高い、コードベースの文字起こしツールです。一方で、開発スキルのない方や、話者分離機能、大容量ファイルのサポートが必要な方は、そうした技術的な壁をすべて解消した専用のソリューションを利用するのが最適です。
音声処理におけるChatGPTの制限事項とは?
ChatGPTは限定的な条件下でオーディオの文字起こしが可能ですが、プロフェッショナルな用途で利用するには6つの決定的な弱点があります。これらは会議、長時間の録音、複数人が話す音声データを扱うチームにとって、実用上の大きな障壁となります。
25MBのファイルサイズ上限: OpenAIのAudio APIでは、アップロードできるファイルサイズが最大25MBに制限されています。標準的な1時間の会議をMP3形式で録音すると、この制限をすぐに超えてしまうため、アップロードのたびに手作業でファイルを分割する必要があります。
話者識別(話者分離)ができない: ChatGPTは、誰が何を話したかという話者ラベル付きで書き起こすことができません。全参加者の発言がひと塊のテキストとして出力されるため、議事録の作成や後日の振り返り用としては極めて使いにくいのが現状です。
Web会議プラットフォームとの連携なし: ChatGPTはZoom、Google Meet、Microsoft Teamsと連携していません。会議を文字起こしするには、毎回手動で録画をエクスポートし、圧縮し、アップロードするという手間が発生します。
直接アップロードの不安定さ: GPT-4oへの直接ファイルアップロードは、途中で失敗することが頻繁にあります。Whisper、SpeechBrain、FFmpegといった複数のバックエンドツールを介して処理を試みますが、数分間待たされた挙げ句、完了しないケースも珍しくありません。
リアルタイム文字起こしに非対応: 録音モードは話者が話し終えた後にのみテキストを返します。ChatGPTの全インターフェースにおいて、会議やインタビュー中のリアルタイムな逐次文字起こしには対応していません。
API経由での出力形式の制限: gpt-4o-transcribeはJSONまたはプレーンテキストのみを出力します。SRTやVTTといった字幕形式が必要な場合はwhisper-1に切り替える必要があり、動画関連のワークフローにおいてモデル管理の負担が増加します。
ChatGPT vs Transkriptor:徹底比較
ChatGPTで動画の音声を文字起こしできるか調べていくと、すぐに限界に気づき、より信頼できる選択肢を探し始めることになります。そこで役立つのが、文字起こしツールの直接比較です。ChatGPTとTranskriptorの主な機能の違いは以下の通りです。
機能 | ChatGPT (Whisperおよび5.4モデル) | Transkriptor |
ファイルサイズ制限 | 25MB | 無制限 |
対応言語 | 57以上 | 100以上 |
話者識別 | 非対応 | はい(自動対応) |
リアルタイム文字起こし | 非対応 | 非対応 |
会議ツール連携 | なし | Zoom, Teams, Google Meet, Webex |
出力形式 | JSON, テキスト, SRT (whisper-1), VTT | TXT, DOCX, SRT, PDF |
AI要約機能 | 手動プロンプト入力が必要 | 自動生成 |
直接アップロードの安定性 | 不安定(失敗の可能性あり) | 安定 |
精度 | 変動あり | 99%以上 |
フリープラン | ChatGPT無料・標準プラン | 90分 |
セットアップが必要 | アカウントまたはAPIキー | アカウント登録のみ |
GDPR/SOC 2準拠 | 一般消費者向け製品のため未記載 | 対応 |
ChatGPTで音声文字起こしを行うべきケースとは?
ChatGPTは、特定の限定的な状況や、正確性がそれほど厳しく求められない場合に力を発揮します。以下のようなシーンに最適です:
25MB未満の短くクリアな音声ファイルを、今使っているChatGPTでサッと文字起こししたい場合。
1つのプロンプトで、文字起こしから要約・翻訳・分析まで一気に完結させたい場合。
OpenAIのエコシステム内で、Whisper APIを活用した音声認識機能のプロトタイプを開発している場合。
背景ノイズがほとんどなく、1人の人間がはっきりと話している録音データのみを扱う場合。
音声の文字起こしに Transkriptor を活用すべきタイミングとは?
ChatGPTで文字起こしを行うか、専用ツールに切り替えるべきか迷っているなら、実際の使用感の違いは一目瞭然です。あるテストでは、5.4MBの音声ファイルをChatGPTにアップロードしたところ、Whisper、SpeechBrain、FFmpegなど複数のバックエンド処理が試行されたものの、5分以上経過しても文字起こしは作成されませんでした。一方、Transkriptorは同じファイルをわずか数分で処理し、話者識別付きの完全な文字起こしをアップロードするだけで提供しました。この信頼性の差こそが、ツール選びにおいて最も重要なポイントです。
Transkriptorなら、専門知識がなくてもわずか4ステップで音声を正確で編集可能なテキストに変換できます。Transkriptorが必要となる主なシーンをご紹介します。
複数人が参加する会議の録音を文字起こしし、自動で話者を特定・ラベル付けしたい場合。
音声または動画ファイルのサイズが25MBを超える場合。
文字起こしと同時に、AIによる自動要約、ネクストアクションの特定、感情分析などを行いたい場合。
100以上の多言語に対応しており、一貫性のある信頼性の高い翻訳・文字起こし結果が必要な場合。
ファイル変換の手間をかけずに、SRT字幕ファイルやDOCX形式のドキュメントとして書き出したい場合。
Zoom、Google Meet、Microsoft Teamsと連携し、録画データの書き出し作業を自動化したい場合。
Transkriptorで音声ファイルを文字起こしする方法
Transkriptorを使えば、専門知識がなくてもわずか4つのステップで音声を正確な編集可能テキストに変換できます。以下の手順に従ってください。
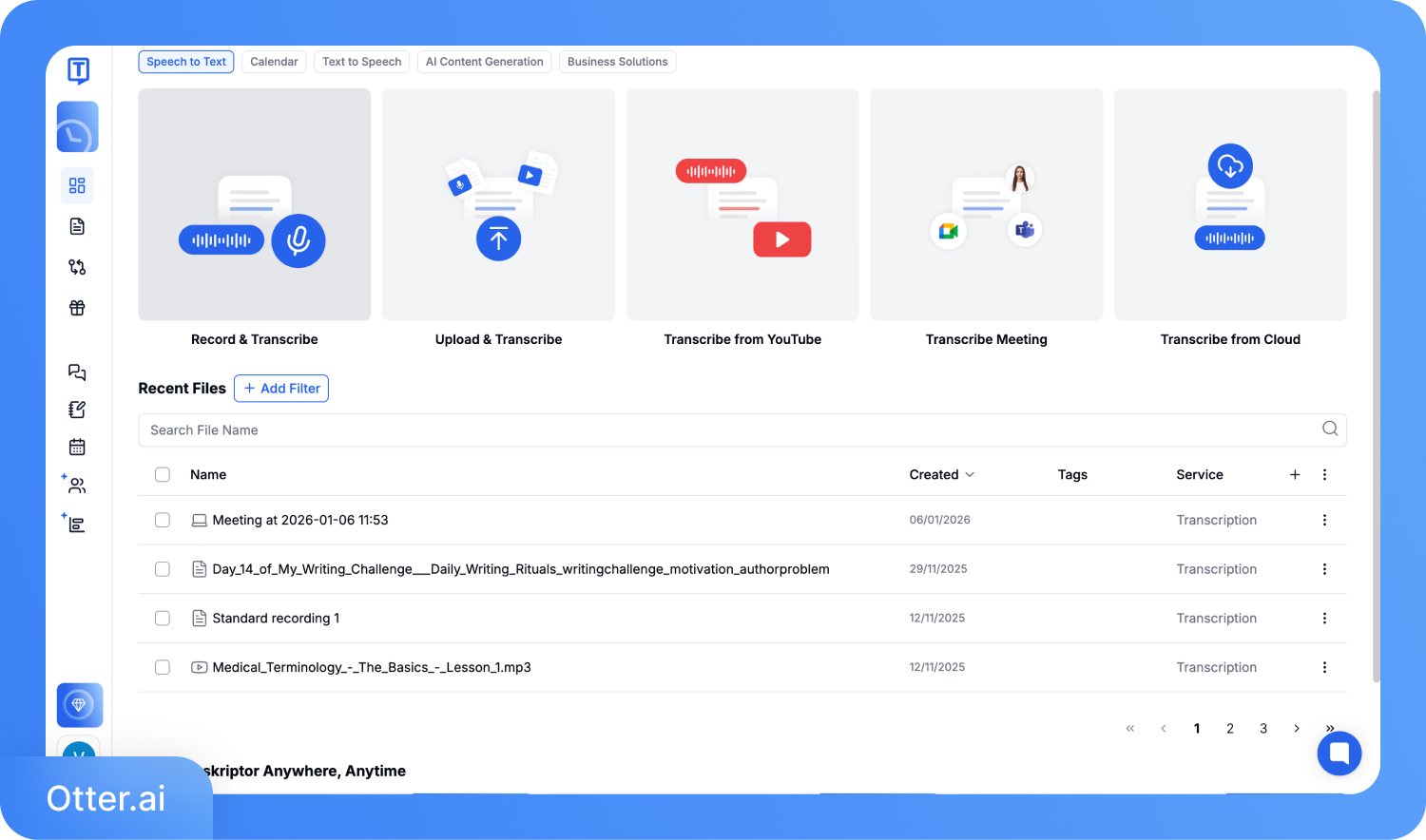
ステップ 1: アカウントを作成してダッシュボードにアクセスします。録音済みのファイルがある場合は「アップロードして文字起こし」を、その場で録音する場合は「録音して文字起こし」を選択します。
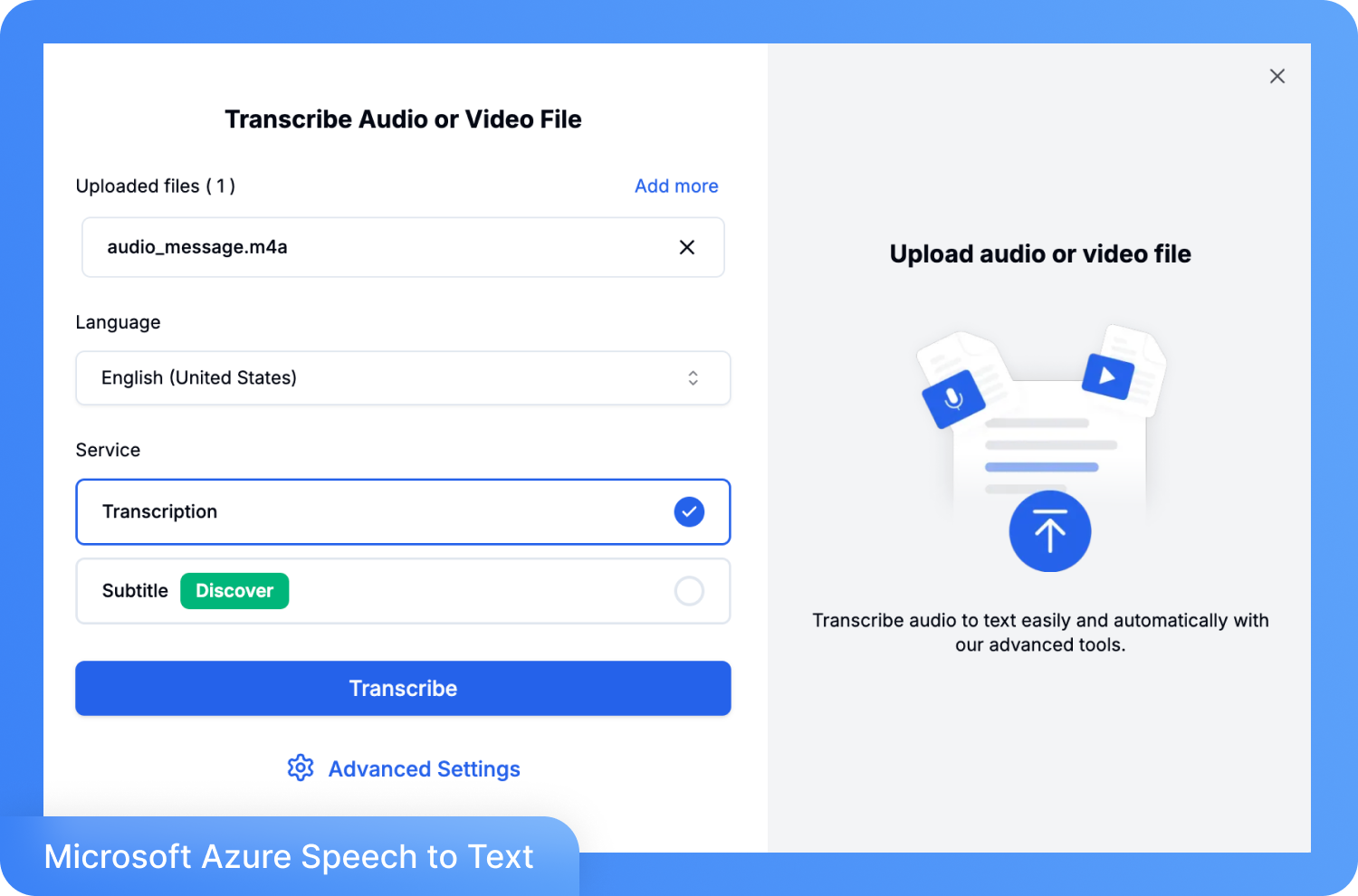
ステップ 2: ファイルをアップロードし、言語を選択して「文字起こし」をクリックします。
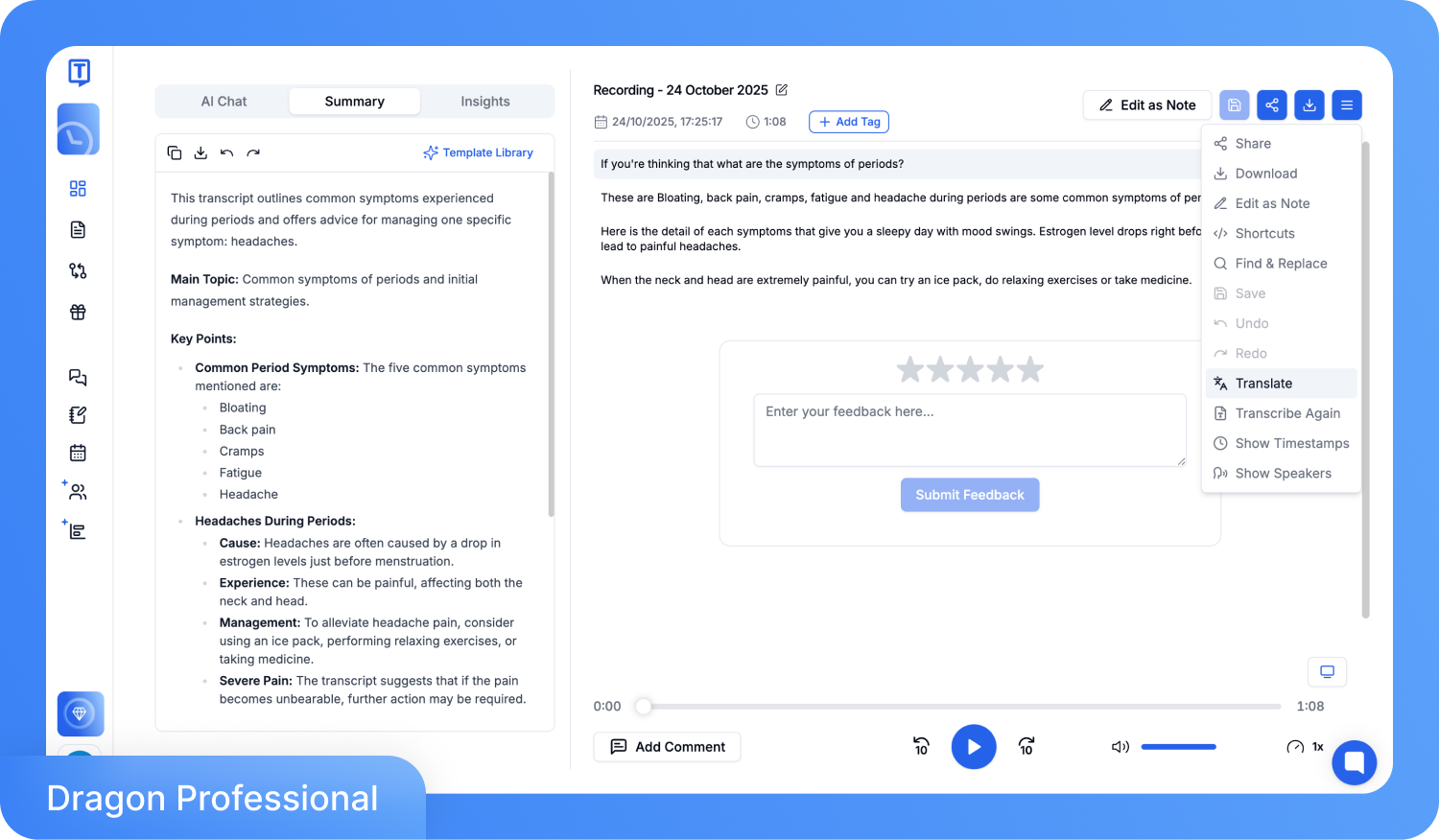
ステップ 3: 数分で文字起こしが完了します。専用のエディターを開き、誤字の修正、話者の名前変更、タイムスタンプの調整を行います。多言語での文字起こしが必要な場合は「翻訳」オプションをクリックしてください。
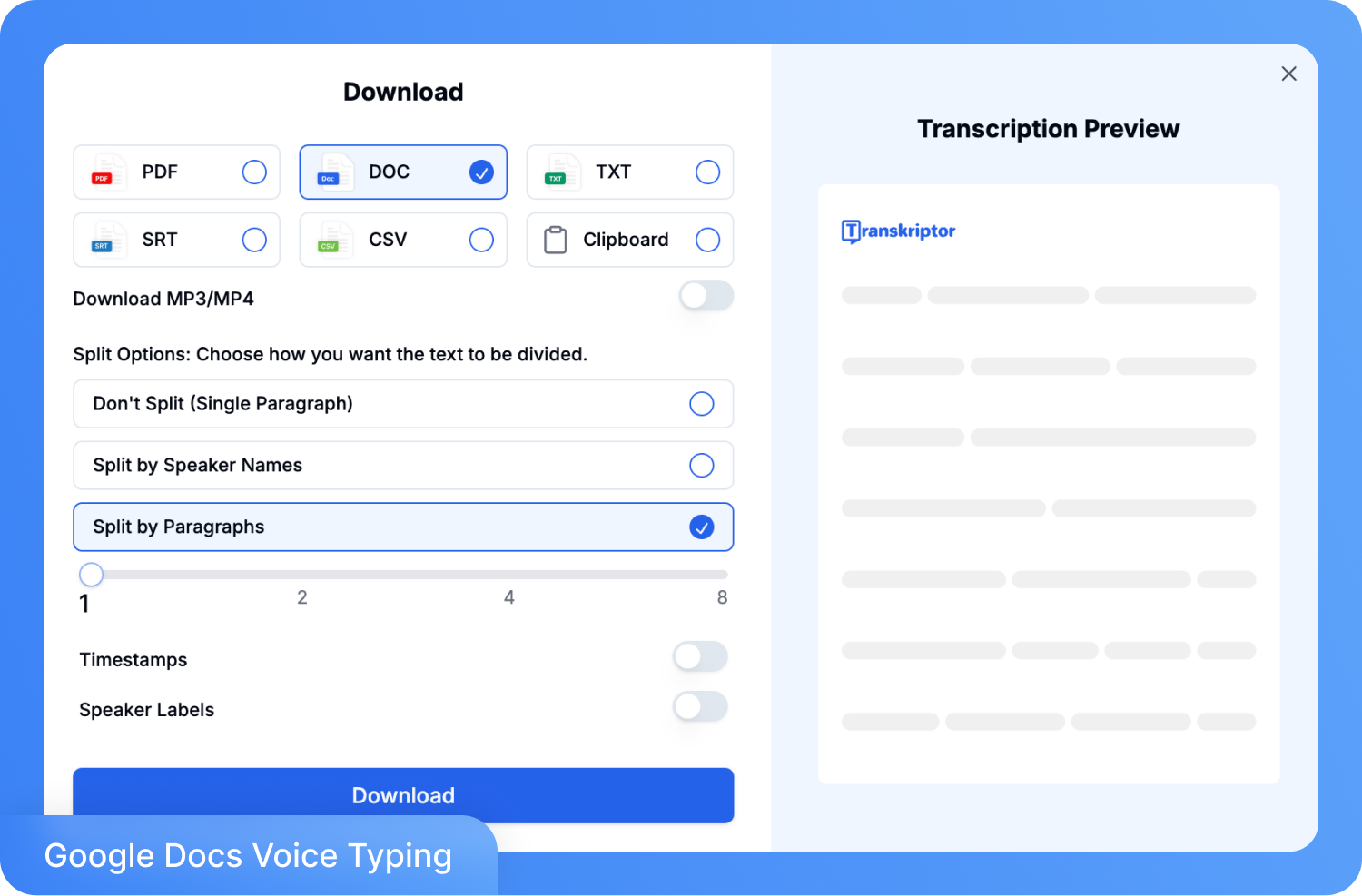
ステップ 4: 最終的な文字起こし結果は、TXT、DOCX、SRT、またはPDF形式でエクスポートできます。チームと直接共有したり、レポート、字幕作成、ドキュメント作成のワークフロー用にダウンロードしたりすることが可能です。
まとめ
ChatGPTで音声の文字起こしができるかという問いの答えは、条件付きで「イエス」です。短い録音や、25MB未満で話者が一人のクリアな音声であれば、基本的なニーズには対応できます。しかし、その狭い範囲を超えると、話者の識別ができない、会議アプリとの連携不可、アップロードの不安定さ、そして長い録音を拒絶するファイルサイズの壁といった限界がすぐに露呈します。Transkriptorは、それらすべての課題を解決します。100以上の言語で99%以上の精度を誇り、話者を自動で識別、さらにZoom、Google Meet、Microsoft Teamsと直接連携します。まずは無料プランをこちらからお試しください: Transkriptor.com 。わずか数分で、精度の高い文字起こしデータが手に入ります。