アカウントを作成し、ファイルを録音またはアップロード
Transkriptorアカウントを作成し、無料の文字起こしアクセスを開始しましょう。音声/動画を録音またはアップロードして、すぐに文字起こしを始めましょう。
アップロードして音声やビデオをテキストに変換
MP3ファイルを文字起こしクリックしてアップロードし、無料で文字起こし
音声やビデオを録音して無料で文字起こし
以下の個人に信頼されています

最高評価の文字起こしChrome拡張機能で音声をテキストに変換。ブラウザから画面、カメラ、またはマイクを即座に録音し、正確な音声からテキストへの文字起こしを取得。
Transkriptorは、世界中の何千人ものユーザーに信頼されている最高の音声文字起こしソフトウェアソリューションの一つとして認識されています。なぜ人々が私たちを最高の音声文字起こしツールとして選ぶのかをご覧ください。
Transkriptorを数ヶ月使用していますが、精度は常に98-99%で、技術用語にも対応しています。英語、スウェーデン語、ドイツ語を含む多言語をサポートしています。長い録音をテキストに変換するのが、今でははるかに速く効率的です。

Lena Kaur
デジタルマーケティングスペシャリスト
Transkriptorを使えば、音声をテキストに変換する方法は簡単です。会議、講義、インタビュー、ボイスノートなどの録音を正確で編集可能なテキストに数秒で変換するためのステップバイステップのプロセスに従ってください。
業界向けに音声をテキストに変換したいですか?Transkriptorは、法務チーム、医療従事者、心理学者、コンサルタント、ITマネージャー、メディア専門家向けに設計された業界特化の文字起こし機能を提供します。

医療専門家向けに設計された安全で正確な医療音声入力ソフトウェア。患者とのやり取りを整理された臨床トランスクリプトに瞬時に変換します。

コンサルタント向けの文字起こしでクライアント会議を整理された検索可能なビジネストランスクリプトに変換します。即時に転記されたインサイト、重要な発見、AIによる文字起こし分析を通じて、より良いクライアント成果を得ることができます。

Transkriptorがあなたのプロのセラピーセッションの文字起こし者として機能する間、クライアントに完全に集中できます。整理されたセッションノート、進捗追跡、安全な文書化を自動で取得します。

法務文字起こし技術でクライアント会議を検索可能なトランスクリプトに変換します。機密性を維持しながら、議論の即時記録にアクセスできます。

放送やコンテンツ制作のための迅速で正確なメディア文字起こし。複数の形式と言語に対応し、音声を瞬時にテキストに変換します。
AIによる文字起こし、要約、分析で、すべての会議を実用的なインサイトに変換します。
Transkriptorは、あらゆるレベルでセキュリティとプライバシーを優先しています。当社の企業レベルの文字起こしプラットフォームは、SOC 2、GDPR、ISO 27001、SSL基準に準拠し、音声および動画データを完全に保護し、安全に文字起こしします。





文字起こしとは、音声やビデオ録音から話された言葉を文字に変換するプロセスです。会議、インタビュー、講義、ポッドキャスト、メディアコンテンツなどで広く使用されています。文字起こしは、人間の文字起こし者が手動で行うか、AI文字起こしソフトウェアで自動的に行うことができます。
文字起こしは、音声やビデオから話された言葉を文字に変換することで機能します。Transkriptorのようなツールにファイルをアップロードすると、AIが音声を検出し、話者を識別し、タイムスタンプ付きのトランスクリプトを生成します。その後、テキストをレビューおよび編集し、TXT、DOCX、または字幕(SRT/VTT)形式でエクスポートできます。
文字起こしの利点には、アクセシビリティの向上、コンテンツの検索性の向上、生産性の向上があります。話されたコンテンツを読みやすく再利用しやすい文字に変換します。文字起こしは、インデックス化可能なコンテンツを作成することでSEOもサポートします。TranskriptorのようなAI文字起こしツールはプロセスを自動化し、時間とリソースを節約します。
文字起こしの精度には、音質、バックグラウンドノイズ、話者の明瞭さ、重なり合う会話、アクセント、話者の数など、いくつかの要因が影響します。録音の質が悪い音声や強いアクセントはAI文字起こしツールの効果を低下させる可能性があります。高品質のマイク、明瞭なスピーチ、最小限の中断が結果を改善します。
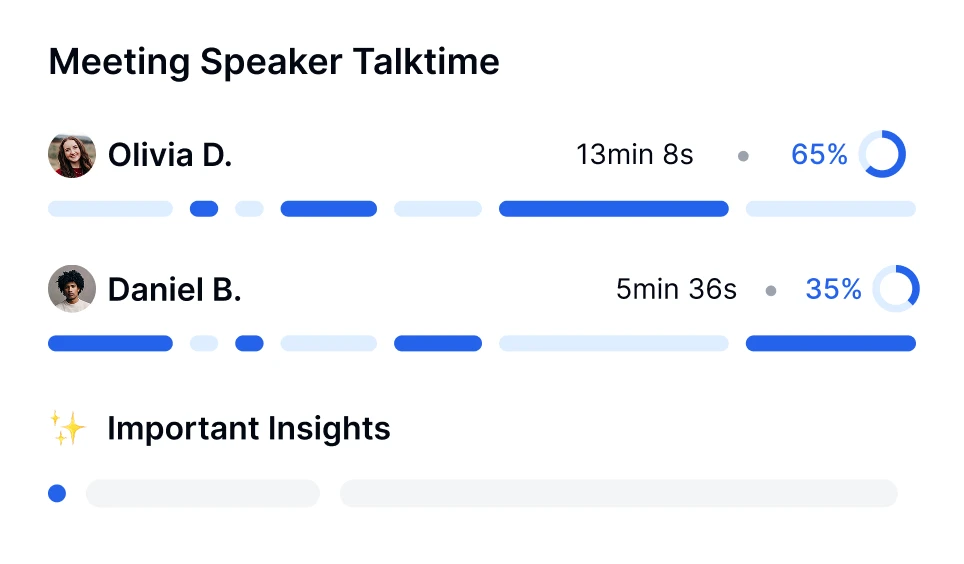
はい、Transkriptorのような最新の文字起こしツールは、話者ダイアリゼーション技術を使用して複数の話者を処理できます。この機能は、トランスクリプト内で各話者を識別し、ラベル付けするため、会議、インタビュー、グループディスカッションでの会話を追いやすくします。
最高の文字起こしソフトウェアはTranskriptorです。最大99%の精度を誇る高度なAI駆動の文字起こしを提供します。Transkriptorは100以上の言語をサポートし、さまざまな形式の音声またはビデオファイルをアップロードでき、話者識別、字幕生成、内蔵のトランスクリプトエディタなどの機能を備えています。他の人気のある文字起こしツールにはOtter.aiやFireflies.aiもあり、AIベースの文字起こしサービスを提供しています。しかし、Transkriptorは、幅広い言語対応、手頃な価格、カジュアルユーザーとプロフェッショナルの両方をサポートする洗練された編集機能で好まれています。
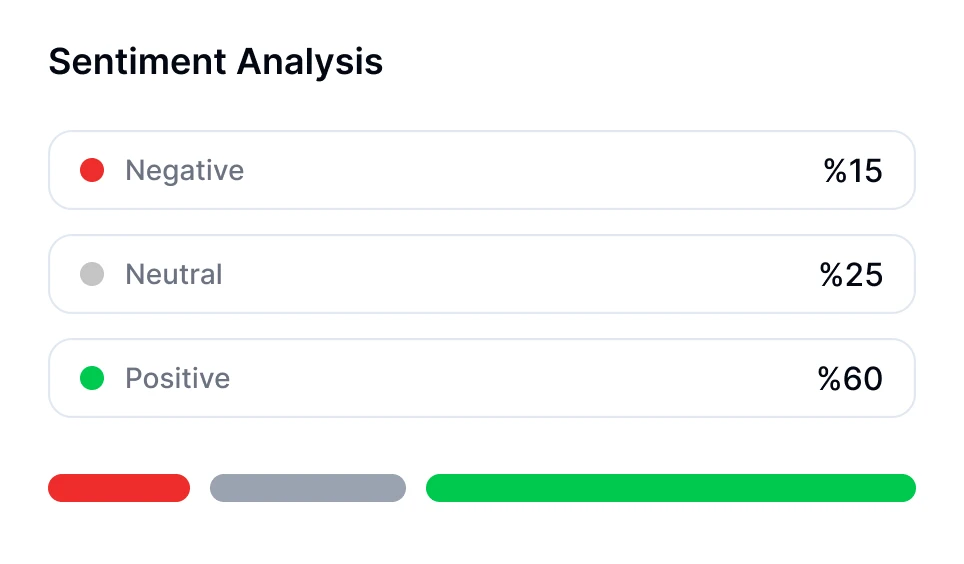
AI駆動のツールであるTranskriptorを使用して会話の感情分析を行うことができます。Transkriptorのミーティングボットはオンライン会議に直接参加するか、アップロードされた録音を分析します。文字起こし後に、会話の感情トーンを自動的に評価し、セグメントをポジティブ、中立、またはネガティブとして分類します。
最高の音声からテキストへの変換ツールはTranskriptorです。高度なAIを使用して、話された音声を数秒で正確にテキストに変換します。TranskriptorはMP3、WAV、M4Aなどの一般的な音声フォーマットに対応し、100以上の言語で動作します。
最高の無料文字起こしツールはTranskriptorです。無料プランでも非常に正確でAI駆動の音声からテキストへのサービスを提供します。Transkriptorの無料文字起こしオプションでは、1日最大30分の音声を文字起こしできます。
ビデオをテキストに変換するとは、AIを活用した音声認識技術を使って、ビデオ内の話された言葉を自動的に書き起こすプロセスです。
Transkriptorは、ビデオをテキストに書き起こすための最適なツールの一つで、迅速な処理、高い精度、複数の言語とフォーマットのサポートを提供します。
はい、TranskriptorのようなAIベースの書き起こしツールを使用して、手動入力の必要なくビデオを自動的にテキストに変換できます。
はい、ビデオをテキストに変換することで、ビデオコンテンツを検索可能、インデックス可能、検索エンジンにアクセス可能にすることでSEOを向上させます。
ビデオをテキストに変換するツールは、コンテンツ制作者、教育者、ジャーナリスト、マーケター、学生、迅速な書き起こしが必要な企業に最適です。
はい、ビデオをテキストに変換することで、聴覚障害のあるユーザーや幅広いオーディエンスに対して読みやすいトランスクリプトを提供し、アクセシビリティを向上させます。
AIは音声パターン、音声信号、言語の文脈を分析して、ビデオから話された言葉を正確にテキストに変換します。
Transkriptorは、高性能なAIと使いやすいツールを使用して、高速で正確、かつ安全で手頃な価格のビデオからテキストへの文字起こしを提供します。