1
Vytvořte si účet a nahrajte nebo zaznamenejte soubor
Vytvořte si zdarma účet na Transkriptoru. Poté zaznamenejte svou schůzku, hovor, přednášku nebo nahrajte svůj audio/video soubor, abyste mohli začít s přepisem.
Nahrajte a převeďte zvuk nebo video na text
Přepis souboru MP3Klikněte pro nahrání a přepis zdarma
Nahrajte zvuk nebo video a přepište zdarma
Důvěřují jednotlivci v

Převeďte zvuk na text s nejlépe hodnoceným transkripčním rozšířením pro Chrome. Okamžitě zaznamenejte svou obrazovku, kameru nebo mikrofon a získejte přesné přepisy řeči na text přímo z vašeho prohlížeče.
Transkriptor je uznáván jako jedno z nejlepších řešení pro přepis zvuku na text, důvěřují mu tisíce uživatelů po celém světě. Podívejte se, proč si nás lidé vybírají jako svůj nejlepší nástroj pro přepis zvuku.
Nejlepší aplikace pro přepis
Používám Transkriptor posledních pár dní a jsem velmi ohromen přesností přepisu. I s delšími zvukovými soubory nebo šumem aplikace téměř vše správně identifikuje. Rychlost zpracování je také silnou stránkou — soubor je připraven během několika minut. Rozhraní je jednoduché, nemusíte hledat funkce, a export do jiných formátů práci velmi usnadňuje. Celkově je to praktický, rychlý a spolehlivý nástroj, ideální pro každého, kdo potřebuje převést zvuk na text bez zbytečných komplikací.

Matheus Santos
Zeptejte se na cokoli ohledně vašeho přepisu a nechte AI asistenta pro přepis od Transkriptor poskytnout přesné odpovědi. Pro hlubší vhled do více přepsaných souborů vytvořte prohledávatelné znalostní báze pomocí vašich audio přepisů nebo jiných nahraných dokumentů.
Získejte přehledy z jednání přizpůsobené vám díky inteligenci AI přepisu. Transkriptor spolupracuje s Zoom, Google Meet a Microsoft Teams pro zachycení každé konverzace. Vyberte si ze specializovaných šablon pro prodej, marketing, vzdělávání a další, nebo vytvořte vlastní formáty pro vaše jedinečné potřeby. Přeměňte schůzky na strukturované, akční přehledy.
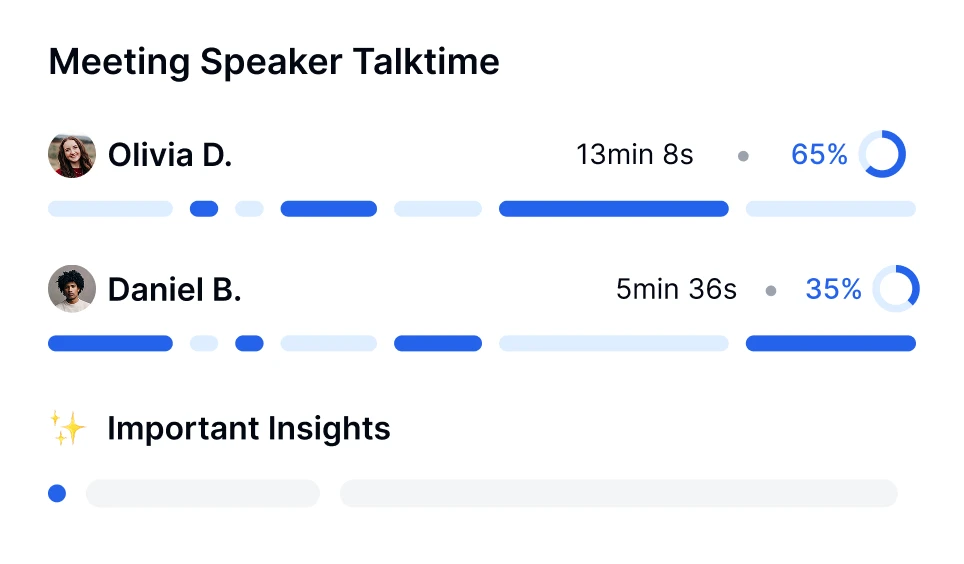
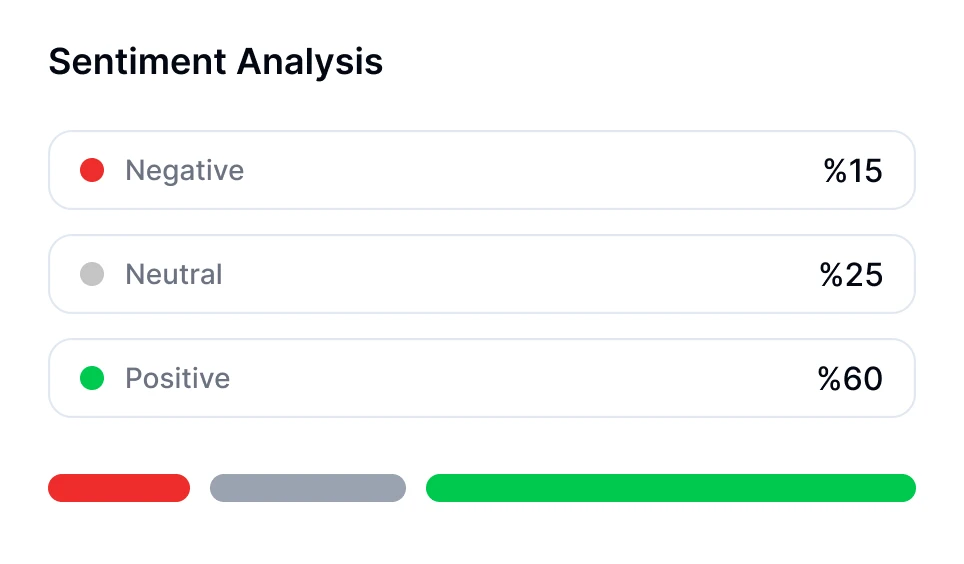
Ponořte se hlouběji do konverzací s technologií AI přepisu. Provádějte analýzu sentimentu, sledujte časy řečníků a odhalte datově řízené přehledy z vašich přepsaných schůzek.
Snadno převádějte video na text zdarma s naším výkonným přepisovacím enginem – není potřeba žádná konverze souborů. Podporujeme širokou škálu formátů, včetně MP3, MP4, WAV a dalších. Můžete rychle přepsat jakýkoliv obsah bez problémů s kompatibilitou.
Propojte Transkriptor s cloudovým úložištěm, CRM a dalšími aplikacemi přes Zapier pro automatický přepis mediálních souborů a směrování vašich přesných přepisů na preferované platformy, čímž ušetříte čas a udržíte váš přepsaný obsah dokonale organizovaný.
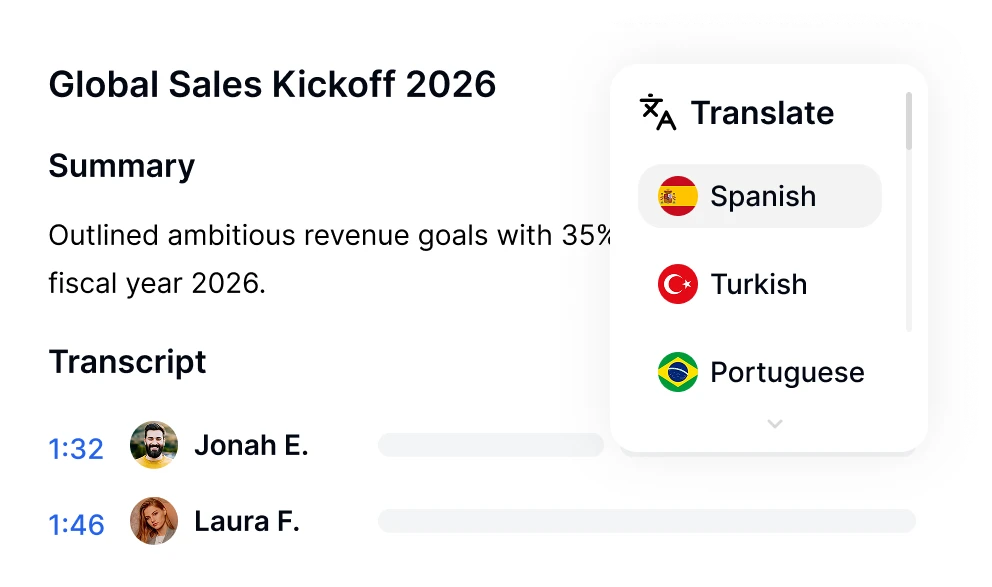
Ask Transkriptor okamžitě prohledává každý přepis schůzky ve vaší knihovně, aby našel rozhodnutí, úkoly, citace a odpovědi s uvedením zdrojů, ve více než 100 jazycích.
Postřehy ze schůzek plynou přímo do vašich CRM, produktivity a úložných nástrojů. Žádný export, žádné kopírování a vkládání.




















Vytvořte si zdarma účet na Transkriptoru. Poté zaznamenejte svou schůzku, hovor, přednášku nebo nahrajte svůj audio/video soubor, abyste mohli začít s přepisem.

Transkriptor poskytuje plně editovatelné přepisy, analýzu sentimentu hovoru a rozdělení klíčových témat.

Dělejte si poznámky snadno v Transkriptoru pro snadný přístup. Organizujte poznámky a přepisy do složek a pracovních prostorů.

Automatizujte přepisy pomocí integrací, vytvářejte znalostní báze z více souborů a ptejte se nebo komunikujte s přepisy.
Chcete přepsat zvuk na text pro vaše odvětví? Transkriptor nabízí specifické funkce přepisu navržené pro právní týmy, poskytovatele zdravotní péče, psychology, konzultanty, IT manažery a mediální profesionály.

Transformujte klientská jednání na organizované, prohledávatelné obchodní přepisy s přepisem pro konzultanty. Získejte okamžité přepsané poznatky, klíčové závěry a analýzu přepisu řízenou AI pro lepší výsledky pro klienty.

Plně se soustřeďte na své klienty, zatímco Transkriptor funguje jako váš profesionální přepisovatel pro terapeutická sezení. Získejte organizované poznámky ze sezení, sledování pokroku a zabezpečenou dokumentaci automaticky.

Přeměňte klientské schůzky na prohledávatelné přepisy s naší technologií právního přepisu. Získejte okamžitý přístup k záznamům diskusí s důrazem na důvěrnost.
Proměňte každou schůzku v akční poznatky pomocí přepisu, shrnutí a analýz s podporou umělé inteligence.
Transkriptor klade důraz na bezpečnost a soukromí na každé úrovni. Naše platforma pro podnikový přepis splňuje standardy SOC 2, GDPR, ISO 27001 a SSL, aby bylo zajištěno, že vaše audio a video data jsou plně chráněna a bezpečně přepsána.





Přepis je proces převodu mluveného jazyka z audio nebo video nahrávek do psaného textu. Je široce využíván pro schůzky, rozhovory, přednášky, podcasty a mediální obsah. Přepis může být prováděn ručně lidskými přepisovateli nebo automaticky pomocí softwaru pro přepis využívajícího umělou inteligenci.
Přepis funguje převodem mluvených slov z audia nebo videa na psaný text. Nahrajete soubor do nástroje jako je Transkriptor, který pomocí umělé inteligence detekuje řeč, identifikuje mluvčí a generuje časově označený přepis. Poté můžete text zkontrolovat a upravit a exportovat jej ve formátech jako TXT, DOCX nebo titulky (SRT/VTT).
Výhody přepisu zahrnují zlepšenou přístupnost, lepší vyhledatelnost obsahu a zvýšenou produktivitu. Přeměňuje mluvený obsah na psaný text, který je snadno čitelný a lze jej znovu použít. Přepis také podporuje SEO vytvářením indexovatelného obsahu. Nástroje pro přepis s umělou inteligencí, jako je Transkriptor, automatizují proces, čímž šetří čas a zdroje.
Přesnost přepisu je ovlivněna několika faktory, včetně kvality zvuku, šumu na pozadí, srozumitelnosti řečníka, překrývajícího se dialogu, přízvuků a počtu řečníků. Špatně nahrané audio nebo silné přízvuky mohou snížit efektivitu nástrojů pro přepis s umělou inteligencí. Vysoce kvalitní mikrofony, jasná řeč a minimální přerušení zlepšují výsledky.
Ano, moderní nástroje pro přepis, jako je Transkriptor, zvládnou více mluvčích pomocí technologie diarizace mluvčích. Tato funkce identifikuje a označuje každého mluvčího v přepisu, což usnadňuje sledování konverzací na schůzkách, rozhovorech nebo skupinových diskusích.
Nejlepší software pro přepis je Transkriptor. Nabízí vysoce přesný přepis poháněný umělou inteligencí s přesností až 99 %. Transkriptor podporuje více než 100 jazyků, umožňuje uživatelům nahrávat audio nebo video soubory v různých formátech a zahrnuje funkce jako identifikace mluvčích, generování titulků a vestavěný editor přepisů. Další populární nástroje pro přepis zahrnují Otter.ai a Fireflies.ai, které také nabízejí služby přepisu s umělou inteligencí. Nicméně, Transkriptor je preferován pro širší jazykové pokrytí, dostupné ceny a zjednodušené editační funkce, které podporují jak běžné uživatele, tak profesionály.
Analýzu sentimentu pro konverzace můžete provést pomocí nástrojů s umělou inteligencí, jako je Transkriptor. Transkriptorův bot pro schůzky se může přímo připojit k vašim online schůzkám nebo analyzovat nahrané záznamy. Po přepisu automaticky vyhodnotí emocionální tón konverzace — klasifikující segmenty jako pozitivní, neutrální nebo negativní.
Nejlepším převodníkem z audia na text je Transkriptor. Používá pokročilou AI k přesnému převodu mluveného audia do psaného textu během několika sekund. Transkriptor podporuje populární audio formáty jako MP3, WAV a M4A a funguje ve více než 100 jazycích.
Nejlepším bezplatným nástrojem pro přepis je Transkriptor. Poskytuje vysoce přesné služby převodu řeči na text řízené AI, i ve svém bezplatném plánu. S bezplatnou možností přepisu od Transkriptoru můžete přepsat až 30 minut audia denně.
Převod videa na text je proces automatického přeměny mluvených slov ve videu na psaný text pomocí technologie rozpoznávání řeči poháněné umělou inteligencí.
Transkriptor je jedním z nejlepších nástrojů pro přepis videa na text, nabízející rychlé zpracování, vysokou přesnost a podporu více jazyků a formátů.
Ano, můžete automaticky převést video na text pomocí nástrojů pro přepis založených na AI, jako je Transkriptor, což eliminuje potřebu ručního psaní.
Ano, převod videa na text zlepšuje SEO tím, že činí video obsah vyhledatelným, indexovatelným a přístupným pro vyhledávače.
Nástroje pro převod videa na text jsou ideální pro tvůrce obsahu, pedagogy, novináře, marketéry, studenty a firmy, které potřebují rychlý přepis.
Ano, převod videa na text zlepšuje přístupnost tím, že poskytuje čitelné přepisy pro uživatele se sluchovým postižením a širší publikum.
AI analyzuje vzory řeči, zvukové signály a jazykový kontext, aby přesně převedla mluvená slova z videa na text.
Transkriptor nabízí rychlý, přesný, bezpečný a cenově dostupný přepis videa na text s výkonnou AI a uživatelsky přívětivými nástroji.