KI-gestützte Stimmungsanalyse
Transkriptors KI-gesteuerte Stimmungsanalyse verwandelt Ihre Audioaufnahmen in detaillierte emotionale Erkenntnisse. Erkennen Sie präzise Sprechzeit, Tonfall, Emotion und Absicht in Kundengesprächen, Online-Meetings und Interviews, indem Sie Sprache automatisch in Text umwandeln und Stimmungsdaten mit fortschrittlicher KI-gestützter Transkription und Stimmungsanalyse extrahieren.
Transkribieren und analysieren Sie Stimmungen in über 100 Sprachen
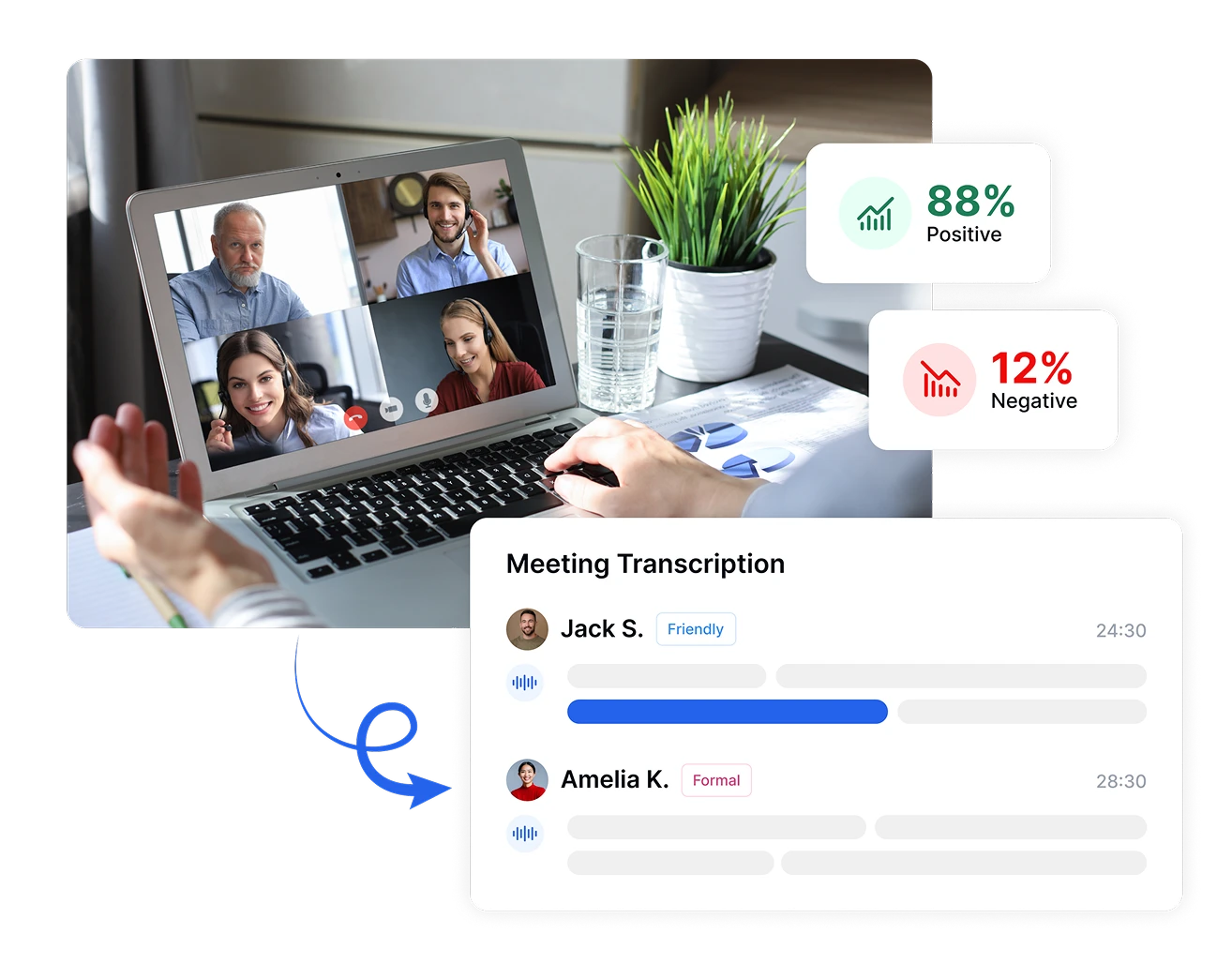
Treffen Sie datengestützte Entscheidungen mit Stimmungsanalyse
Wandeln Sie subjektive emotionale Reaktionen in objektive Metriken mit Transkriptor um. Messen Sie die Intensität der Stimmung, verfolgen Sie emotionale Veränderungen während Gesprächen und vergleichen Sie die Stimmung über verschiedene Zeiträume oder Kundensegmente hinweg. Diese präzisen Messungen verwandeln abstrakte Gefühle in konkrete Datenpunkte und ermöglichen evidenzbasierte Entscheidungen, die die Kundenzufriedenheit und Geschäftsergebnisse verbessern.

Analysieren Sie Stimmungen in über 100 Sprachen
Überwinden Sie Sprachbarrieren mit Transkriptors mehrsprachigen Stimmungsanalyse-Fähigkeiten. Erkennen Sie emotionale Nuancen in über 100 Sprachen und ermöglichen Sie globalen Teams, die Kundenstimmung unabhängig von Region oder Sprache zu verstehen. Diese umfassende Sprachabdeckung gewährleistet eine konsistente Stimmungsverfolgung über internationale Märkte hinweg mit hohen Genauigkeitsraten von bis zu 99%.
Erfassen und analysieren Sie Stimmungen über alle Kanäle hinweg
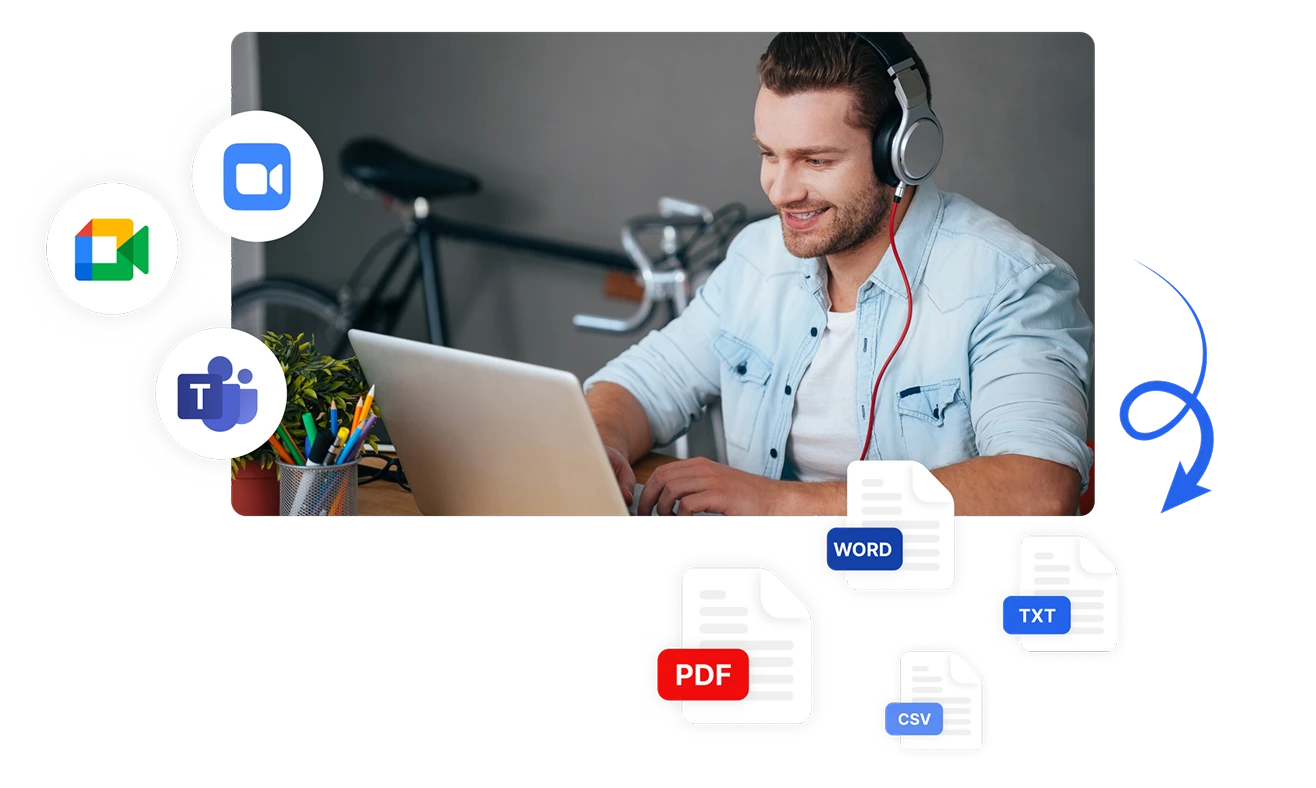
Analysieren Sie Stimmungen aus verschiedenen Kommunikationskanälen mit Transkriptors vielseitigen Eingabeoptionen. Transkribieren und analysieren Sie automatisch Stimmungen aus hochgeladenen Audiodateien, direkt aufgezeichneten Meetings oder integrierten Plattformen wie Zoom, Microsoft Teams und Google Meet. Exportieren Sie Ihre Stimmungsanalyse-Ergebnisse in PDF-, Word-, TXT-, CSV-Formaten oder teilen Sie sie sofort mit Teammitgliedern.

Stimmungsanalyse in nur 4 einfachen Schritten
- 1SCHRITT 1
Laden Sie Ihre Audiodatei hoch oder verbinden Sie Ihr Meeting
- 2SCHRITT 2
Transkriptor transkribiert und analysiert
- 3SCHRITT 3
Überprüfen Sie die Stimmungsanalyse
- 4SCHRITT 4
Exportieren oder teilen Sie die Stimmungserkenntnisse
Wer profitiert am meisten von Transkriptors Stimmungsanalyse

Customer Success Team
Verfolgen Sie Kundenzufriedenheitstrends über alle Serviceinteraktionen hinweg mit KI-gesteuerter Stimmungsanalyse.

Vertriebsprofis
Optimieren Sie Verkaufsgespräche mithilfe KI-gestützter Stimmungsanalyse von Kundengesprächen.

Juristische Fachkräfte
Analysieren Sie Stimmungsmuster in aufgezeichneten Zeugenaussagen, Mandantengesprächen und Zeugenberichten.

HR-Fachleute
Verbessern Sie Bewerbungsgespräche und Mitarbeiterfeedback-Sitzungen mit objektiver Stimmungsanalyse.
All-in-One Stimmungsanalyse-Lösung
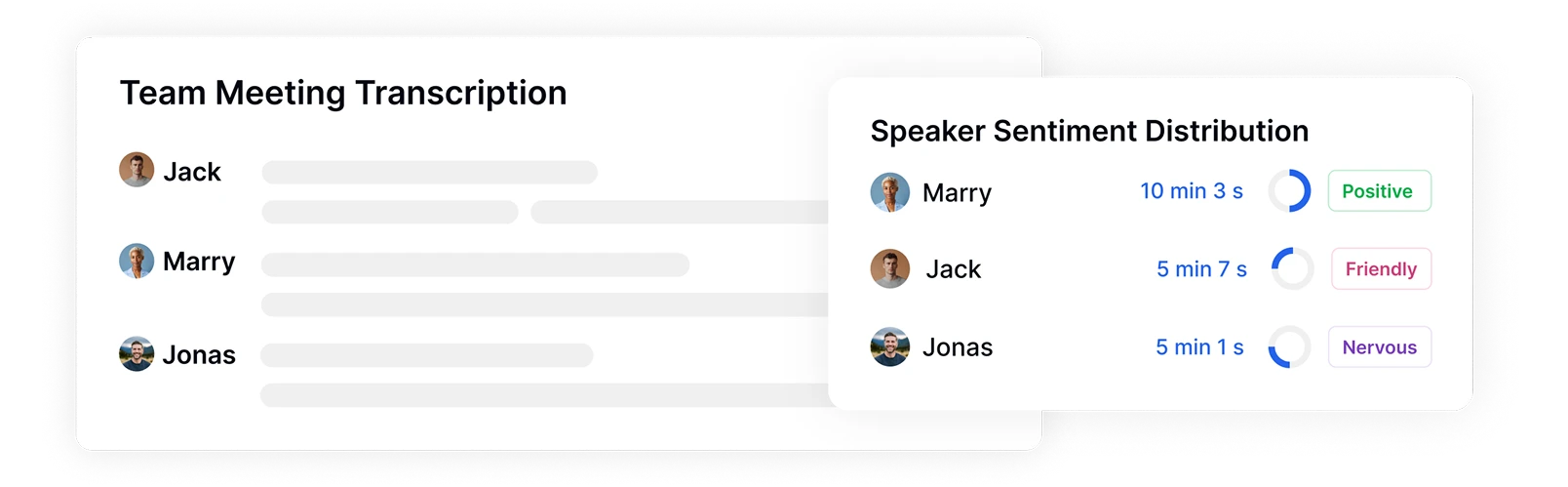
Sprecher identifizieren und Stimmungsverteilung verfolgen
Transkriptor identifiziert und markiert automatisch verschiedene Sprecher in Ihren Aufnahmen und misst dabei ihre Sprechzeit und emotionalen Muster. Sehen Sie genau, wer wann gesprochen hat, wie lange und mit welcher Stimmung, und erhalten Sie wichtigen Kontext für die Analyse der emotionalen Dynamik zwischen Teilnehmern während Meetings, Interviews oder Kundeninteraktionen.
Sprecher identifizieren und Stimmungsverteilung verfolgen
Transkriptor identifiziert und markiert automatisch verschiedene Sprecher in Ihren Aufnahmen und misst dabei ihre Sprechzeit und emotionalen Muster. Sehen Sie genau, wer wann gesprochen hat, wie lange und mit welcher Stimmung, und erhalten Sie wichtigen Kontext für die Analyse der emotionalen Dynamik zwischen Teilnehmern während Meetings, Interviews oder Kundeninteraktionen.

KI-gestützte Stimmungszusammenfassungen generieren
Verwandeln Sie lange Gespräche in prägnante Stimmungszusammenfassungen mit Transkriptors KI-Technologie. Diese Zusammenfassungen identifizieren wichtige Stimmungswechsel und quantifizieren den allgemeinen emotionalen Ton, um einen schnellen Überblick über die emotionale Reise während eines aufgezeichneten Gesprächs zu geben.

Wissensdatenbanken mit Stimmungsanalyse aufbauen
Organisieren Sie wesentliche emotionale Erkenntnisse, indem Sie benutzerdefinierte Wissensdatenbanken mit stimmungsanalysierten Transkripten erstellen. Speichern, kategorisieren und durchsuchen Sie Stimmungsdaten, um emotionale Benchmarks zu etablieren, wiederkehrende Muster zu identifizieren und ein umfassendes Repository emotionaler Intelligenz aufzubauen.
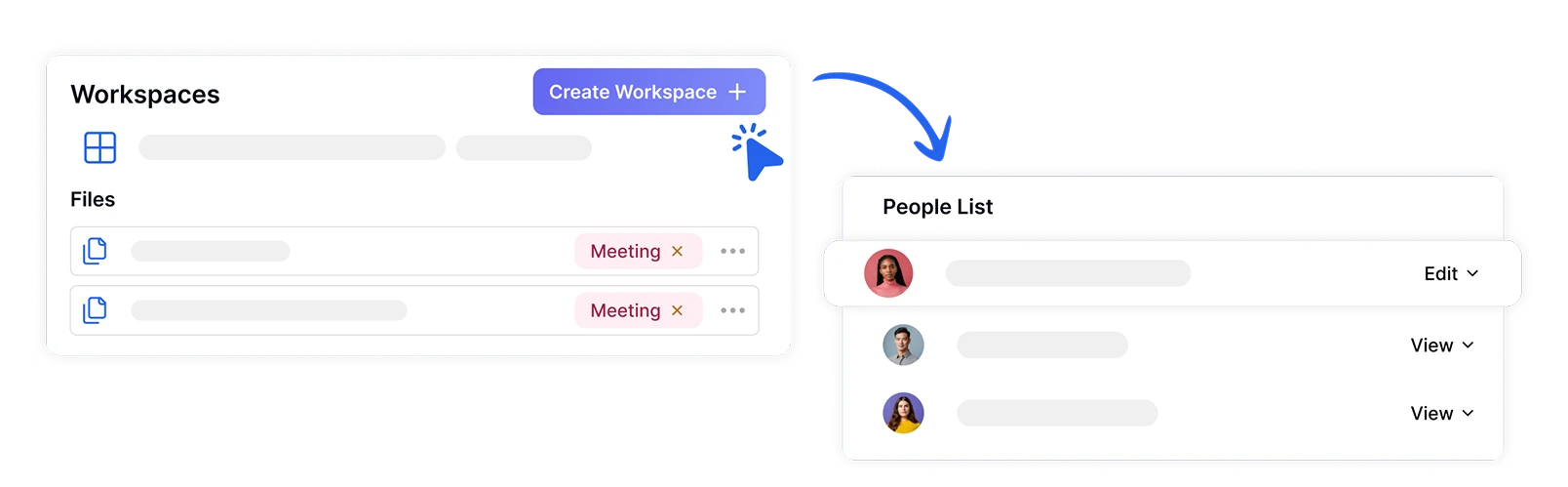
Dateien in sicheren Arbeitsbereichen organisieren und teilen
Verwalten Sie Team-Stimmungsanalyseprojekte sicher, indem Sie dedizierte Arbeitsbereiche mit zugewiesenen Rollen und Berechtigungen erstellen. Stellen Sie sicher, dass sensible emotionale Daten nur für autorisierte Teammitglieder zugänglich sind, während Sie die Zusammenarbeit bei Stimmungserkenntnissen über Abteilungen hinweg erleichtern.
Sicherheit auf Unternehmensebene
Sicherheit und Kundendatenschutz haben bei jedem Schritt Priorität. Wir entsprechen den SOC 2- und DSGVO-Standards und stellen sicher, dass Ihre Informationen jederzeit geschützt sind.





Erfolgsgeschichten unserer Kunden
Kundenverlust durch Nutzung von Stimmungsdaten reduziert
Transkriptor hat revolutioniert, wie unser 14-köpfiges Team Kundenbeziehungen verwaltet. Durch die Analyse der Stimmung in Onboarding- und Check-in-Gesprächen identifizieren wir gefährdete Konten, bevor herkömmliche Kennzahlen Probleme aufzeigen. Die Mehrsprachenunterstützung bewältigt unsere globale Kundenbasis, und die benutzerdefinierten Vorlagen helfen, unseren Ansatz im gesamten Team zu standardisieren.

Kira Johnson
Customer Success Lead
30% weniger Fehleinstellungen
Transkriptor hat unseren Interviewprozess in 7 Monaten Nutzung transformiert. Die Stimmungsanalyse hilft, emotionale Inkonsistenzen in Kandidatenantworten zu identifizieren, die wir übersehen könnten. Die Verfolgung der Stimmung bei verschiedenen Interviewthemen gibt tiefere Einblicke in die kulturelle Passung und verbessert unsere Einstellungserfolgsrate erheblich.

Amira Khan
HR-Direktorin
Häufig gestellte Fragen
Das beste Tool für Stimmungsanalyse ist Transkriptor. Mit fortschrittlicher KI ausgestattet, transkribiert Transkriptor automatisch gesprochene Inhalte und analysiert den emotionalen Ton mit hoher Genauigkeit. Es kennzeichnet Gespräche als positiv, negativ oder neutral und unterstützt über 100 Sprachen.
Stimmungsanalyse funktioniert durch den Einsatz von künstlicher Intelligenz und natürlicher Sprachverarbeitung (NLP), um den emotionalen Ton von Text oder Sprache zu bewerten. Sie identifiziert wichtige Indikatoren für Emotionen wie Wortwahl, Satzstruktur und kontextbezogene Hinweise, um Inhalte als positiv, negativ oder neutral zu klassifizieren. Fortschrittlichere Systeme können auch Absichten, emotionale Veränderungen und sprecherspezifische Stimmungen im Zeitverlauf erkennen.
Transkriptor ermöglicht es Ihnen, benutzerdefinierte Arbeitsbereiche mit rollenbasierten Berechtigungen zur Organisation von Stimmungsanalyseprojekten zu erstellen. Sie können auch Wissensdatenbanken mit stimmungsmarkierten Inhalten aufbauen, wodurch es einfach wird, emotionale Daten zu speichern, zu kategorisieren und zu durchsuchen, während Sicherheit und Zugänglichkeit gewährleistet bleiben.
Stimmungsanalyse hilft Kundenservice-Teams, emotionale Auslöser in Gesprächen zu identifizieren, die Wirksamkeit von Deeskalationstechniken zu messen und die Kundenstimmung während des gesamten Supportprozesses zu verfolgen. Diese Erkenntnisse ermöglichen es den Teams, ihren Ansatz zu verfeinern, was zu verbesserter Kundenzufriedenheit und weniger wiederholten Anrufen führt.
Ja, Transkriptor unterstützt Stimmungsanalyse in über 100 Sprachen mit hoher Genauigkeit. Das System ist darauf ausgelegt, kulturelle und sprachliche Nuancen zu erkennen, die für jede Sprache spezifisch sind, und gewährleistet so eine konsistente Stimmungserkennung unabhängig von der Muttersprache des Sprechers.
Greifen Sie überall auf Transkriptor zu
Nehmen Sie live auf oder laden Sie Audio- und Videodateien hoch, um sie zu transkribieren. Bearbeiten Sie Ihre Transkriptionen mit Leichtigkeit und nutzen Sie den KI-Assistenten, um mit Transkriptionen zu chatten oder diese zusammenzufassen.