
Креирајте свој профил и запишите или прикачете датотека
Создадете ваша Transkriptor сметка и започнете со бесплатен пристап за транскрибирање. Снимете или прикачете ваш аудио/видео за да започнете со инстантно транскрибирање.
Инстантно транскрибирајте состаноци, интервјуа, повици и предавања во прецизни транскрипти—започнете со бесплатно транскрибирање аудио во текст со вештачка интелигенција и откривајте вредни увиди од вашите разговори.
Претворете аудио во текст на повеќе од 100 јазици
Работи со
Конвертирајте локална видео или аудио датотека во текст
Прикачете аудио или видео датотека од вашиот локален уред и транскрибирајте бесплатно.
Кликнете за да прикачите и транскрибирате бесплатно
Снимање на аудио и претворање во текст
Снимете го вашиот аудио директно и конвертирајте аудио во текст бесплатно.
Доверба од страна на поединци на


Претворете аудио во текст со најдобро оценетото проширување за транскрипција за Chrome. Веднаш снимајте го вашиот екран, камера или микрофон и добијте прецизни транскрипции од говор во текст директно од вашиот прелистувач.
Лесно конвертирајте видео во текст бесплатно со нашиот моќен мотор за транскрибирање - не е потребна конверзија на датотеки. Поддржуваме широк спектар на формати, вклучувајќи MP3, MP4, WAV и многу повеќе. Можете да транскрибирате секаква содржина брзо и без проблеми со компатибилноста.
Поврзете го Transkriptor со складиште во облак, CRM и други апликации преку Zapier за автоматско транскрибирање на медиумски датотеки и насочување на вашите прецизни транскрипти до вашите претпочитани платформи, заштедувајќи време и одржувајќи ја вашата транскрибирана содржина совршено организирана.
Создадете ваша Transkriptor сметка и започнете со бесплатен пристап за транскрибирање. Снимете или прикачете ваш аудио/видео за да започнете со инстантно транскрибирање.
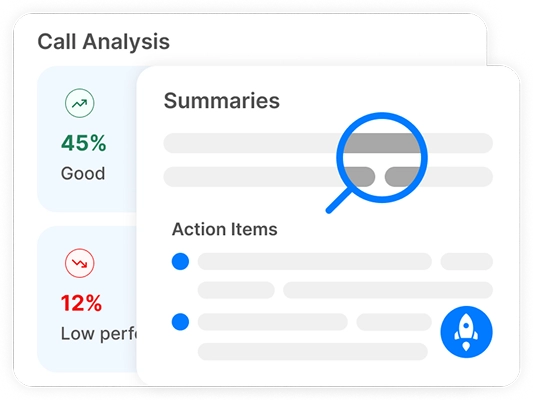
Transkriptor обезбедува целосно уредувачки транскрипти, AI-управувани анализи на чувствата на повици, AI резимеа и клучни теми.
Вашите белешки и аудио транскрипции се чуваат безбедно за лесен пристап. Организирајте ги белешките за состаноците и транскриптите кои можат да се пребаруваат во фолдери и работни простори.
Искористите ја нашата AI транскрипција технологија за да извлечете увид и бази на знаење од повеќе датотеки, и да поставувате прашања или да зборувате со вашиот глас во текст транскрипти.
Создадете ваша Transkriptor сметка и започнете со бесплатен пристап за транскрибирање. Снимете или прикачете ваш аудио/видео за да започнете со инстантно транскрибирање.

Безбедна, прецизна медицинска транскрипција дизајнирана за здравствени професионалци. Претворете ги интеракциите со пациентите во организирани клинички записи веднаш.

Трансформирање на состаноците со клиенти во организирани, пребарувачки бизнис транскрипти. Добијте инстант транскрибирани увиди, клучни наоди и AI-управувани транскрипциони анализи за подобри резултати на клиентите.

Фокусирајте се целосно на вашите клиенти додека Транскриптор делува како ваш професионален транскрибер за терапевтски сесии. Добијте организирани белешки од сесиите, следење на напредокот и безбедна документација автоматски.

Трансформирање на клиентски состаноци во пребарувачки транскрипти со технологија за правна транскрипција. Пристап до инстант евиденција на дискусии со зачувување на доверливост.

Брзо и прецизно транскрибирање на медиумски содржини за емитувања и продукција на содржини. Конвертирајте аудио во текст моментално, со поддршка за повеќе формати и јазици.
Претворете ги вашите видеа во достапна содржина со брзи услуги за транскрипција и автоматско титлување на повеќе од 100 јазици.
Поставувајте прашања, добивајте резимеа и извлекувајте увиди од вашата транскрибирана содржина веднаш.
Управувајте со пристапот, споделувајте датотеки и соработувајте непречено во наменски работни простори.
Додадете прилагодени тагови на која било од вашите датотеки. Брзо пронајдете важни моменти и организирајте ја содржината на ваш начин.
Анализирајте го тонот и сентиментот на транскрибираните состаноци. Совршено за корисничка поддршка и тимска комуникација.
Следете ја распределбата на времето за зборување и нивото на учество во разговорите.
Отклучете ја моќта на напредното транскрибирање аудио во текст со вештачка интелигенција за секој аспект од вашата работа. Пробајте бесплатно - подигнете ја продуктивноста, поедноставете го работниот тек!
Претворете говор во точни транскрипции за секунди. Професионална транскрипциона технологија за аудио и видео содржини, така што можете да се фокусирате на увид, а не на белешки.
Фатете го секој момент со јасност. Снимајте и транскрибирајте го екранот лесно за туторијали, презентации и многу други - прегледајте и пребарувајте транскрибирана содржина кога и да ви е потребна.
Никогаш повеќе не пропуштајте ниту еден детаљ. Автоматска транскрипција, AI состаноци и акциони елементи од вашите состаноци, трансформирање на разговорите во транскрипти кои можат да се пребаруваат, а истовремено ја зголемуваат продуктивноста.
Оживете текст со природни гласови. Конвертирање на пишан текст во реалистични изговорени зборови, подобрување на пристапноста и ангажманот.
Содржина без напор, совршено напишана. Транскрибирајте ги вашите идеи во висококвалитетна, привлечна содржина прилагодена на вашата публика со минимален влез.
Транскрибираното знаење на вашиот тим е само на еден клик оддалеченост. Централизирана AI база на знаење која ги организира, превзема и рационализира транскрибираните разговори беспрекорно.
Transkriptor дава приоритет на безбедноста и приватноста на секое ниво. Нашата платформа за транскрипција е во согласност со SOC 2, GDPR, ISO 27001 и SSL стандардите за да се осигура дека вашите аудио и видео податоци се целосно заштитени и безбедно транскрибирани.




Моќниот AI запишувач на Транскриптор генерира онлајн транскрипции за неколку секунди, додека повеќето услуги одземаат повеќе од 10 минути.
Добијте до 99% точност при транскрибирање на вашите аудио датотеки со Транскриптор. Лесно транскрибирајте или преведувајте аудио содржина на повеќе од 100 јазици.
Добијте вредност за вашите пари со целосниот пакет на продуктивни функции и интуитивни решенија на Транскриптор по пристапна цена.
Транскрипцијата е процес на претворање на говорен јазик од аудио или видео снимки во пишан текст. Таа широко се користи за состаноци, интервјуа, предавања, подкасти и медиумски содржини. Транскрипцијата може да се направи рачно од страна на човечки транскриптори или автоматски со користење на софтвер за транскрипција со вештачка интелигенција.
Транскрипцијата работи со претворање на изговорени зборови од аудио или видео во пишан текст. Прикачувате датотека на алатка како Transkriptor, која користи AI за откривање на говор, идентификување на говорниците и генерирање на временски ознаки. Потоа можете да го прегледате и уредувате текстот, и да го изнесете во формати како TXT, DOCX или преводи (SRT/VTT).
Придобивките од транскрипцијата вклучуваат подобрена пристапност, подобра пребарливост на содржината и зголемена продуктивност. Таа ги претвора говорните содржини во пишан текст кој е лесен за читање и преработка. Транскрипцијата исто така ја поддржува оптимизацијата за пребарувачи (SEO) со создавање на содржина која може да се индексира. Алатките за вештачка интелигенција за транскрипција како Транскриптор го автоматизираат процесот, заштедувајќи време и ресурси.
Прецизноста на транскрипцијата е под влијание на неколку фактори, вклучувајќи го квалитетот на звукот, позадинската бучава, јасноста на звучникот, дијалогот кој се преклопува, акцентите и бројот на звучници. Лошо снимен звук или силни акценти може да ја намалат ефикасноста на алатките за транскрипција на AI. Висококвалитетните микрофони, јасниот говор и минималните прекини ги подобруваат резултатите.
Да, модерните алатки за транскрипција како Transkriptor можат да се справат со повеќе звучници со користење на технологијата за дијаризација на звучниците. Оваа функција го идентификува и означува секој говорник во транскриптот, олеснувајќи го следењето на разговорите на состаноци, интервјуа или групни дискусии.
Најдобриот софтвер за транскрибирање е Transkriptor. Тој нуди високо прецизно транскрибирање со вештачка интелигенција со точност до 99%. Transkriptor поддржува над 100 јазици, им овозможува на корисниците да прикачуваат аудио или видео датотеки во различни формати и вклучува функции како идентификација на говорник, генерирање на титлови и вграден уредувач на транскрипти. Други популарни алатки за транскрибирање вклучуваат Otter.ai и Fireflies.ai, кои исто така нудат услуги за транскрибирање базирани на вештачка интелигенција. Сепак, Transkriptor е преферираниот избор поради неговата поширока јазична покриеност, достапни цени и рационализирани функции за уредување кои ги поддржуваат и обичните корисници и професионалците.
Можете да спроведете анализа на чувствата за разговори со користење на алатки со AI како Transkriptor. Ботот за состаноци на Transkriptor може директно да се приклучи на вашите онлајн состаноци или да ги анализира прикачените снимки. По транскрипцијата, автоматски го оценува емоционалниот тон на разговорот, класифицирајќи ги сегментите како позитивни, неутрални или негативни.
Најдобриот конвертор на аудио во текст е Transkriptor. Тој користи напредна вештачка интелигенција за прецизно претворање на говорно аудио во пишан текст за само неколку секунди. Transkriptor поддржува популарни аудио формати како MP3, WAV и M4A, и работи на повеќе од 100 јазици.
Најдобриот бесплатен алат за транскрипција е Transkriptor. Тој обезбедува високо прецизни и АИ-поддржани услуги за претворање на говор во текст, дури и со бесплатниот план. Со бесплатната опција за транскрипција на Transkriptor, можете да транскрибирате до 30 минути аудио дневно.













