
ChatGPT สามารถถอดความเสียงได้หรือไม่?
Transcribe, Translate & Summarize in Seconds
คำตอบแบบสรุป: ChatGPT สามารถถอดความเสียงได้ผ่านโมเดล Whisper ของ OpenAI แต่มีข้อจำกัดเรื่องขนาดไฟล์ไม่เกิน 25MB ไม่สามารถระบุตัวผู้พูดได้ และไม่สามารถเชื่อมต่อกับการประชุมได้ ในขณะที่ Transkriptor ให้ความแม่นยำสูงกว่า 99% รองรับ 100+ ภาษา และใช้งานได้ทันทีโดยไม่ต้องตั้งค่า
การบันทึกการประชุม สัมภาษณ์ หรือการบรรยาย แล้วต้องการเปลี่ยนเป็นข้อความที่ถูกต้องอย่างรวดเร็วเป็นปัญหาใหญ่ของคนทำงานในปัจจุบัน หลายคนจึงหันไปพึ่ง ChatGPT เพราะหวังว่าจะช่วยแก้ปัญหานี้ได้แบบไร้รอยต่อ จนเกิดคำถามสำคัญว่า: ChatGPT ถอดความเสียงได้จริงหรือ? ซึ่งคำตอบที่แท้จริงนั้นมีรายละเอียดมากกว่าแค่ ‘ได้’ หรือ ‘ไม่ได้’
ChatGPT ถอดความไฟล์เสียงได้โดยใช้โมเดล Whisper แต่ด้วยข้อจำกัดที่เข้มงวด เช่น ขนาดไฟล์ห้ามเกิน 25MB การไม่ระบุชื่อผู้พูด การอัปโหลดที่อาจล้มเหลว และการไม่สามารถเชื่อมต่อกับแพลตฟอร์มประชุมออนไลน์ได้ ทำให้การใช้งานจริงยังมีขีดจำกัด ChatGPT อาจใช้ได้ดีกับคลิปสั้นๆ ที่มีคนพูดคนเดียวและเสียงชัดเจน แต่สำหรับการบันทึกระดับมืออาชีพ การประชุมที่มีผู้พูดหลายคน หรือไฟล์เสียงยาวๆ ข้อจำกัดเหล่านี้จะกลายเป็นปัญหาใหญ่ การรู้เท่าทันข้อจำกัดเหล่านี้จะช่วยให้คุณประหยัดเวลาได้มากขึ้น
ChatGPT มีกระบวนการถอดความเสียงอย่างไร?
หากคุณกำลังสงสัยว่า ChatGPT สามารถเปลี่ยนเสียงเป็นข้อความได้ไหม คำตอบคือได้แน่นอน โดยมีตัวเลือกถึง 3 วิธีที่ตอบโจทย์การใช้งานต่างกันไป ไม่ว่าจะเป็นการบันทึกเสียงแบบสั้นๆ หรือการทำงานที่ซับซ้อนมากขึ้น การเลือกวิธีที่ถูกต้องจะช่วยให้คุณได้ผลลัพธ์ที่แม่นยำและราบรื่นที่สุด
วิธีที่ 1: การอัปโหลดไฟล์โดยตรง (GPT-5.4)
GPT-5.4 รองรับการอัปโหลดไฟล์เสียงลงในหน้าแชทของ ChatGPT ได้โดยตรง ผู้ใช้งานแผน Plus, Team และ Enterprise สามารถแนบไฟล์ MP3, WAV, M4A หรือ WebM แล้วสั่งให้ ChatGPT ถอดบทความจากไฟล์เสียงนั้นได้ทันที
จากการทดสอบในสถานการณ์จริง พบว่าการอัปโหลดไฟล์ทำได้สำเร็จ แต่การถอดค่าเสียงกลับล้มเหลว หลังจากอัปโหลดไฟล์เสียงแล้ว ChatGPT ค้างอยู่ในโหมด "กำลังคิด" นานถึง 5 นาที 6 วินาทีก่อนจะเริ่มดำเนินการ จากนั้นใช้เวลาอีก 29 วินาทีพยายามประมวลผลไฟล์ โดยสลับไปมาระหว่าง Whisper, SpeechBrain, การเช็กหาโมเดล ASR และเชื่อมต่อกับ FFmpeg แต่สุดท้ายก็ไม่มีข้อความใดถูกสร้างขึ้นมาและการถอดบทความก็ล้มเหลวในที่สุด
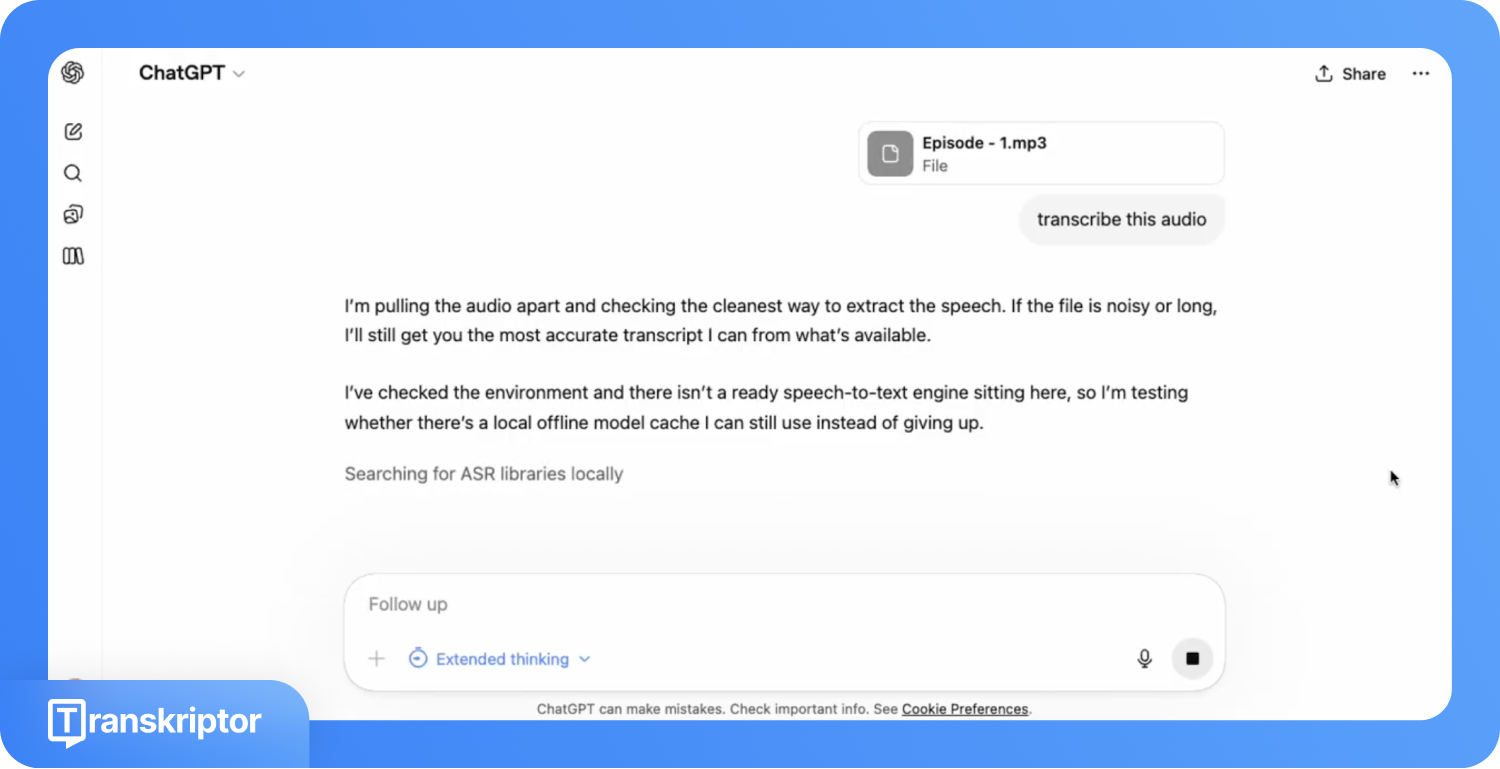
นอกจากความไม่เสถียรแล้ว ยังมีข้อจำกัดทางเทคนิคที่สำคัญคือขนาดไฟล์ที่อัปโหลดได้ไม่เกิน 25MB ซึ่งหมายความว่าไฟล์ MP3 คุณภาพมาตรฐานที่ยาวเกิน 25 นาทีก็น่าจะเกินขีดจำกัดก่อนที่ ChatGPT จะเริ่มทำงานเสียอีก
วิธีที่ 2: โหมดการบันทึกเสียง (Record Mode)
โหมดการบันทึกเสียงช่วยให้ผู้ใช้พูดใส่ ChatGPT ได้โดยตรงผ่านไอคอนไมโครโฟนทั้งในแอปบนมือถือและคอมพิวเตอร์ โดย ChatGPT จะฟังเสียงพูดและประมวลผลหลังจากผู้ใช้หยุดพูด จากนั้นจึงแสดงผลลัพธ์ออกมาเป็นข้อความ
โหมดการบันทึกใช้ได้ดีและแม่นยำสำหรับการพูดคนเดียวสั้นๆ แต่วิธีนี้ไม่ใช่การถอดบทความแบบเรียลไทม์ และข้อความจะปรากฏขึ้นหลังจากพูดจบแล้วเท่านั้น จึงไม่เหมาะสำหรับการประชุมสด การสนทนาที่มีคนหลายคน หรือการบันทึกเสียงที่ยาวนาน แต่ถ้าเป็นการจดบันทึกเสียงส่วนตัวแบบสั้นๆ วิธีนี้ถือว่าตอบโจทย์ได้ดี
วิธีที่ 3: Whisper API (สำหรับนักพัฒนา)
Whisper API ถูกสร้างขึ้นสำหรับนักพัฒนาที่ต้องการเพิ่มระบบแปลงเสียงเป็นข้อความลงในแอป เว็บไซต์ หรือเครื่องมือภายในของตนเองโดยตรง ผู้ใช้งาน ChatGPT ทั่วไปไม่จำเป็นต้องใช้ส่วนนี้ แต่สำหรับนักพัฒนาที่ต้องการระบบถอดความอัตโนมัติในปริมาณมาก นี่คือเส้นทางที่ตรงที่สุดที่ OpenAI มอบให้
หลักการทำงานนั้นเข้าใจง่าย นักพัฒนาจะส่งไฟล์เสียงไปยังเซิร์ฟเวอร์ของ OpenAI และ OpenAI จะส่งข้อความที่ถอดความได้กลับมา โดยไม่มีหน้าต่างแชทมาเกี่ยวข้อง แต่เป็นการสั่งงานผ่านโค้ดทั้งหมด
OpenAI ให้บริการโมเดลการถอดความอย่างเป็นทางการ 3 รูปแบบผ่าน API: 'whisper-1' คือโมเดลดั้งเดิมที่มีความยืดหยุ่นสูงสุด รองรับรูปแบบไฟล์ย้อนกลับได้หลากหลายที่สุด ส่วน 'gpt-4o-transcribe' เป็นโมเดลที่ใหม่กว่าและแม่นยำกว่าโดยเฉพาะในการแปลภาษาต่างๆ และ 'gpt-4o-mini-transcribe' ที่ปรับปรุงประสิทธิภาพในลักษณะเดียวกันแต่มีราคาประหยัดกว่า เหมาะสำหรับการใช้งานในปริมาณมาก
อ้างอิงจาก เอกสารอย่างเป็นทางการของ OpenAI, ChatGPT รองรับรูปแบบไฟล์ดังต่อไปนี้: MP3, MP4, MPEG, M4A, WAV และ WebM โดยแต่ละไฟล์ต้องมีขนาดไม่เกิน 25MB หากไฟล์มีขนาดใหญ่กว่านั้น นักพัฒนาจะต้องแบ่งไฟล์ออกเป็นส่วนเล็กๆ ก่อนแล้วค่อยส่งแต่ละส่วนแยกกัน
สิ่งที่ ChatGPT ทำไม่ได้นั้นก็สำคัญไม่แพ้กัน Whisper API ไม่สามารถแยกแยะผู้พูดได้ หากมีคนสามคนคุยกันในเทปบันทึกเสียง ข้อความที่ถอดออกมาจะปรากฏเป็นย่อหน้าเดียวต่อเนื่องกันโดยไม่มีป้ายระบุว่าใครเป็นคนพูด นอกจากนี้โมเดล gpt-4o-transcribe ยังมีข้อจำกัดเพิ่มเติมคือไฟล์เสียงต้องยาวไม่เกิน 1,500 วินาที (25 นาที) ไม่เช่นนั้นการส่งคำขอจะล้มเหลวและเกิดข้อผิดพลาด
โดยสรุปแล้ว Whisper API มอบแนวทางที่เชื่อถือได้และใช้โค้ดเป็นหลักในการถอดความสำหรับนักพัฒนา แต่สำหรับใครที่ไม่มีพื้นฐานด้านการเขียนโปรแกรม หรือต้องการระบบที่แยกชื่อผู้พูดและรองรับไฟล์ขนาดใหญ่กว่านี้ การเลือกใช้โซลูชันสำเร็จรูปจะช่วยขจัดอุปสรรคทางเทคนิคเหล่านี้ได้ทั้งหมด
ข้อจำกัดของการใช้ ChatGPT เพื่อถอดความจากเสียงมีอะไรบ้าง?
ChatGPT สามารถถอดความจากเสียงได้ภายใต้เงื่อนไขที่จำกัด แต่ยังมีข้อจำกัดหลัก 6 ประการที่ทำให้ไม่เหมาะกับการใช้งานระดับมืออาชีพ ซึ่งอุปสรรคเหล่านี้สร้างปัญหาให้กับทีมที่ต้องจัดการกับรายงานการประชุม ไฟล์บันทึกเสียงที่มีความยาว หรือการสนทนาที่มีผู้พูดหลายคน
จำกัดขนาดไฟล์เพียง 25MB: Audio API ของ OpenAI จำกัดขนาดไฟล์ที่อัปโหลดไว้ไม่เกิน 25MB ซึ่งปกติแล้วไฟล์บันทึกการประชุมความยาวหนึ่งชั่วโมงในรูปแบบ MP3 มักจะมีขนาดเกินขีดจำกัดนี้ ทำให้คุณต้องเสียเวลาแยกไฟล์ด้วยตนเองก่อนอัปโหลดทุกครั้ง
ไม่สามารถแยกเสียงผู้พูดได้: ChatGPT ไม่สามารถถอดความโดยระบุชื่อผู้พูดได้ คำพูดของทุกคนจะรวมกันเป็นข้อความก้อนเดียว ซึ่งทำให้บทถอดความการประชุมนั้นนำไปใช้งานต่อหรือทำเอกสารอ้างอิงได้ยากมาก
ไม่เชื่อมต่อกับแพลตฟอร์มการประชุม: ChatGPT ไม่มีการเชื่อมต่อกับ Zoom, Google Meet หรือ Microsoft Teams ดังนั้นการถอดความการประชุมแต่ละครั้ง คุณต้องเสียเวลาส่งออกไฟล์ บีบอัด และอัปโหลดเองทีละไฟล์
ระบบอัปโหลดไฟล์โดยตรงที่ขาดความเสถียร: การอัปโหลดไฟล์โดยตรงบน GPT-4o มักล้มเหลวบ่อยครั้ง โดย ChatGPT จะพยายามเรียกใช้เครื่องมือเบื้องหลังหลายตัว เช่น Whisper, SpeechBrain และ FFmpeg สลับไปมา แต่สุดท้ายก็มักจะประมวลผลไม่สำเร็จแม้จะใช้เวลานานหลายนาทีก็ตาม
ไม่มีระบบถอดความแบบเรียลไทม์: โหมดบันทึกเสียงจะแสดงข้อความหลังจากที่ผู้พูดหยุดพูดแล้วเท่านั้น การถอดเสียงแบบสดๆ คำต่อคำระหว่างการประชุมหรือการสัมภาษณ์นั้นยังไม่สามารถทำได้ในทุกอินเทอร์เฟซของ ChatGPT
ข้อจำกัดของรูปแบบผลลัพธ์ผ่าน API: gpt-4o-transcribe ให้เอาต์พุตเป็น JSON หรือข้อความธรรมดาเท่านั้น หากต้องการรูปแบบคำบรรยายอย่าง SRT และ VTT จำเป็นต้องสลับไปใช้ whisper-1 ซึ่งจะเพิ่มภาระในการจัดการโมเดลในทุกขั้นตอนการทำวิดีโอ
เปรียบเทียบกันชัดๆ: ChatGPT vs. Transkriptor
เมื่อคุณสงสัยว่า ChatGPT สามารถถอดเสียงจากวิดีโอได้ไหม คุณมักจะได้คำตอบอย่างรวดเร็ว แต่แล้วก็จะเริ่มมองหาตัวเลือกที่น่าเชื่อถือมากกว่า นี่คือเหตุผลว่าทำไมการเปรียบเทียบเครื่องมือถอดเสียงแบบตัวต่อตัวจึงมีประโยชน์ และนี่คือความแตกต่างระหว่าง ChatGPT และ Transkriptor ในฟีเจอร์หลักต่างๆ:
ฟีเจอร์ | ChatGPT (โมเดล Whisper และ 5.4) | Transkriptor |
ขีดจำกัดขนาดไฟล์ | 25MB | ไม่จำกัดโควตา |
ภาษาที่รองรับ | 57+ | 100+ |
การระบุตัวผู้พูด | ไม่ใช่ | ใช่ เป็นระบบอัตโนมัติ |
การถอดเสียงแบบเรียลไทม์ | ไม่ใช่ | ไม่ใช่ |
การเชื่อมต่อกับแอปประชุม | ไม่มี | Zoom, Teams, Google Meet, Webex |
รูปแบบไฟล์เอาต์พุต | JSON, text, SRT (whisper-1), VTT | TXT, DOCX, SRT, PDF |
สรุปเนื้อหาด้วย AI | ต้องใส่คำสั่งด้วยตนเอง | อัตโนมัติ |
ความเสถียรในการอัปโหลดโดยตรง | ไม่เสถียรและอาจล้มเหลว | มีความเสถียรสูง |
ความแม่นยำ | ไม่แน่นอน | มากกว่า 99% |
แผนใช้งานฟรี (Free Plan) | ChatGPT แพ็กเกจเริ่มต้น | 90 นาที |
ต้องมีการตั้งค่า | ต้องใช้บัญชีผู้ใช้หรือ API key | ลงทะเบียนบัญชีเท่านั้น |
GDPR/SOC 2 | สำหรับผลิตภัณฑ์สำหรับผู้บริโภคไม่มีระบุไว้ | ใช่ |
ควรใช้ ChatGPT ถอดความเสียงเมื่อไหร่ดี?
ChatGPT ทำงานได้ดีสำหรับการถอดความเสียงในสถานการณ์ที่มีความเสี่ยงต่ำและมีขอบเขตจำกัด โดย ChatGPT จะเหมาะสมที่สุดเมื่อ:
คุณต้องการถอดความจากคลิปเสียงสั้นๆ ที่มีเสียงชัดเจน ขนาดไม่เกิน 25 MB และคุณใช้งาน ChatGPT อยู่แล้ว
คุณต้องการรวมการถอดความเข้ากับการสรุปเนื้อหา การแปลภาษา หรือการวิเคราะห์ทันทีในคำสั่ง (Prompt) เดียว
คุณเป็นนักพัฒนาที่กำลังสร้างตัวต้นแบบฟีเจอร์แปลงเสียงเป็นข้อความภายในระบบนิเวศของ OpenAI โดยใช้ Whisper API
กรณีการใช้งานของคุณมีเพียงแค่การบันทึกเสียงผู้พูดคนเดียวที่มีเสียงชัดเจนและมีเสียงรบกวนน้อยที่สุด
เมื่อไหร่ที่คุณควรใช้ Transkriptor ในการเปลี่ยนเสียงเป็นข้อความ
หากคุณกำลังตัดสินใจว่าจะใช้ ChatGPT ในการถอดความหรือจะเปลี่ยนมาใช้เครื่องมือเฉพาะทาง ความแตกต่างจะเห็นได้ชัดเจนเมื่อใช้งานจริง ในการทดสอบหนึ่ง การอัปโหลดไฟล์เสียงไปยัง ChatGPT 5.4 ใช้เวลากว่าห้านาทีและล้มเหลวหลายครั้งผ่านระบบหลังบ้าน ทั้ง Whisper, SpeechBrain, FFmpeg และการทดสอบตัวอย่าง แต่ก็ยังไม่สามารถสร้างบทถอดความออกมาได้ ในทางกลับกัน Transkriptor จัดการไฟล์เดียวกันได้ภายในไม่กี่นาที พร้อมส่งมอบบทถอดความที่ระบุตัวตนผู้พูดครบถ้วน โดยไม่ต้องทำอะไรมากกว่าการอัปโหลดไฟล์ ช่องว่างด้านความน่าเชื่อถือนี้เองคือเหตุผลว่าทำไมการเปรียบเทียบนี้จึงสำคัญ
Transkriptor เปลี่ยนเสียงเป็นข้อความที่ถูกต้องและแก้ไขได้ภายใน 4 ขั้นตอน โดยไม่ต้องมีความรู้ด้านเทคนิค นี่คือเหตุผลทั่วไปที่คุณควรเลือกใช้ Transkriptor:
คุณต้องการถอดความจากการประชุมที่มีผู้พูดหลายคนและต้องการระบบระบุตัวตนผู้พูดอัตโนมัติ
ไฟล์เสียงหรือวิดีโอของคุณมีขนาดใหญ่เกิน 25MB
คุณต้องการสรุปเนื้อหาด้วย AI, หัวข้อสิ่งที่ต้องทำ (Action Items) หรือการวิเคราะห์ความรู้สึก (Sentiment Analysis) ควบคู่ไปกับบทถอดความ
คุณทำงานหลายภาษาและต้องการผลลัพธ์ที่แม่นยำและเสถียรในภาษาต่างๆ กว่า 100 ภาษา
คุณต้องการส่งออกไฟล์คำบรรยายใต้ภาพ (SRT) หรือเอกสาร DOCX โดยไม่ต้องผ่านขั้นตอนการแปลงไฟล์เพิ่มเติม
คุณต้องการการเชื่อมต่อโดยตรงกับ Zoom, Google Meet หรือ Teams เพื่อลดขั้นตอนการส่งออกไฟล์บันทึกด้วยตนเอง
วิธีใช้ Transkriptor เพื่อแปลงไฟล์เสียงเป็นข้อความ
Transkriptor ช่วยเปลี่ยนเสียงเป็นข้อความที่แม่นยำและแก้ไขได้ผ่าน 4 ขั้นตอนง่ายๆ โดยไม่จำเป็นต้องมีความรู้ด้านเทคนิค เพียงทำตามขั้นตอนดังนี้:
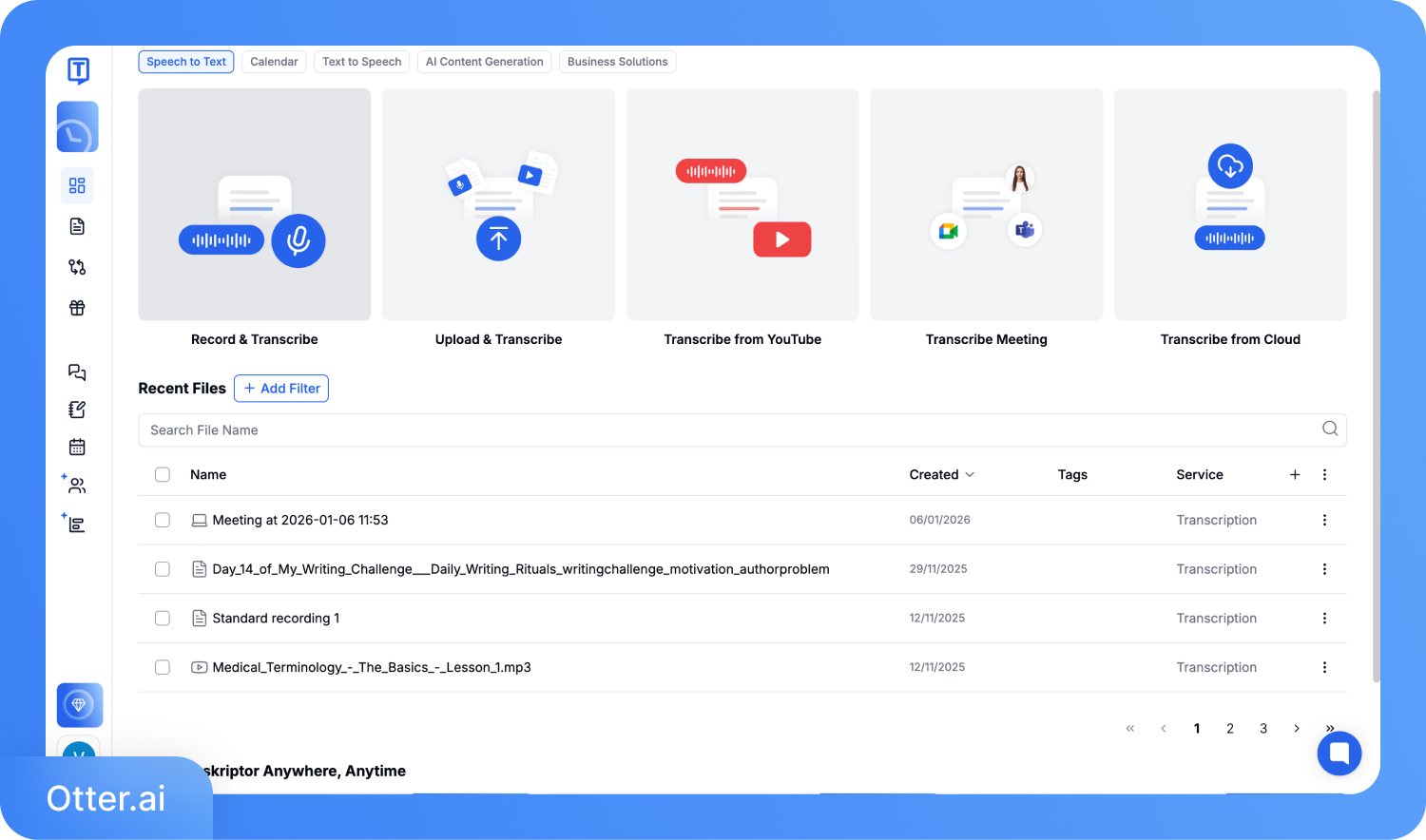
ขั้นตอนที่ 1: สร้างบัญชีและเข้าสู่หน้าแดชบอร์ด จากนั้นเลือก 'อัปโหลดและถอดเสียง' หากคุณมีไฟล์บันทึกอยู่แล้ว หรือเลือก 'บันทึกและถอดเสียง'
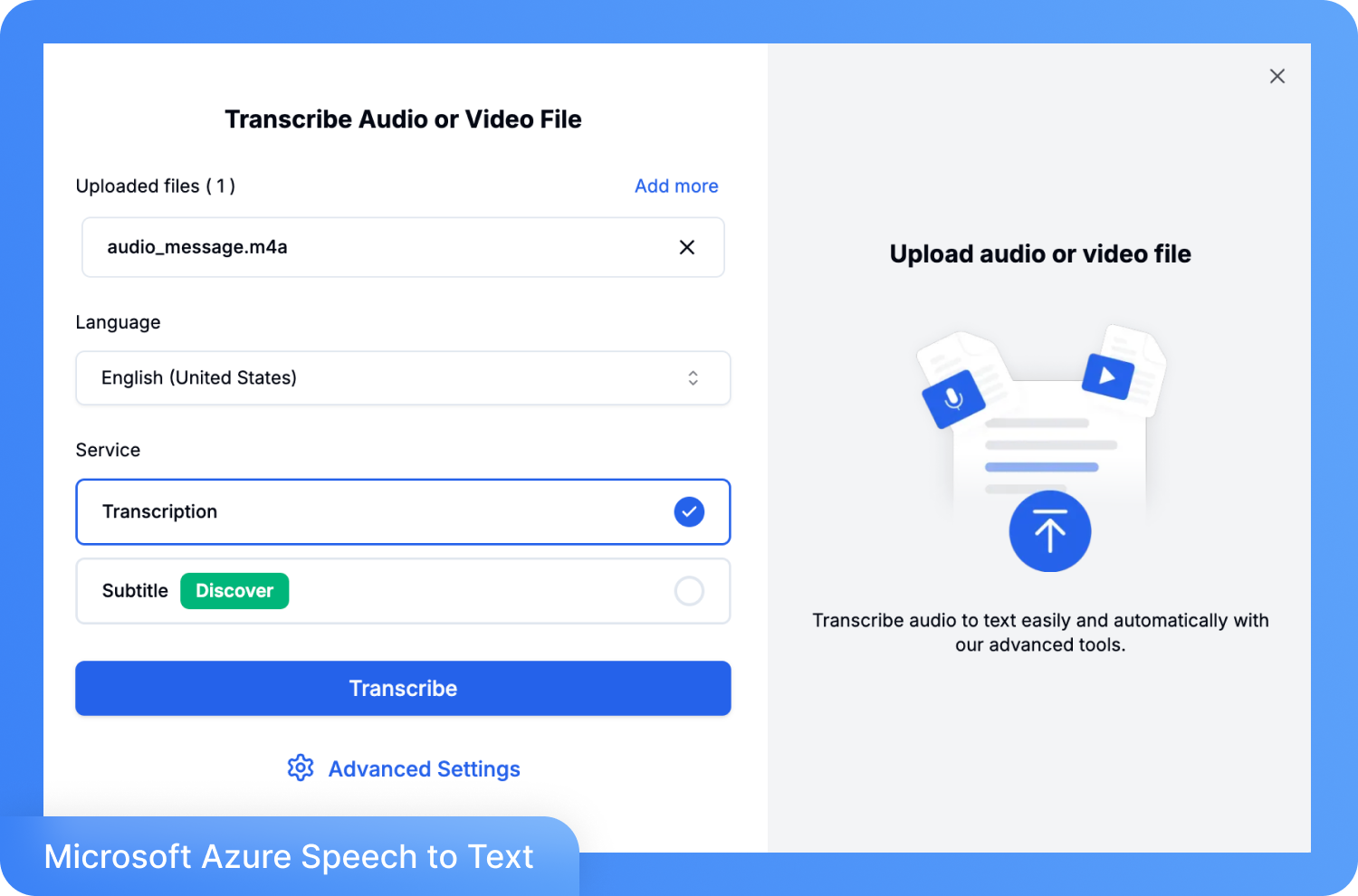
ขั้นตอนที่ 2: อัปโหลดไฟล์ เลือกภาษาปลายทาง แล้วคลิก 'ถอดเสียง'
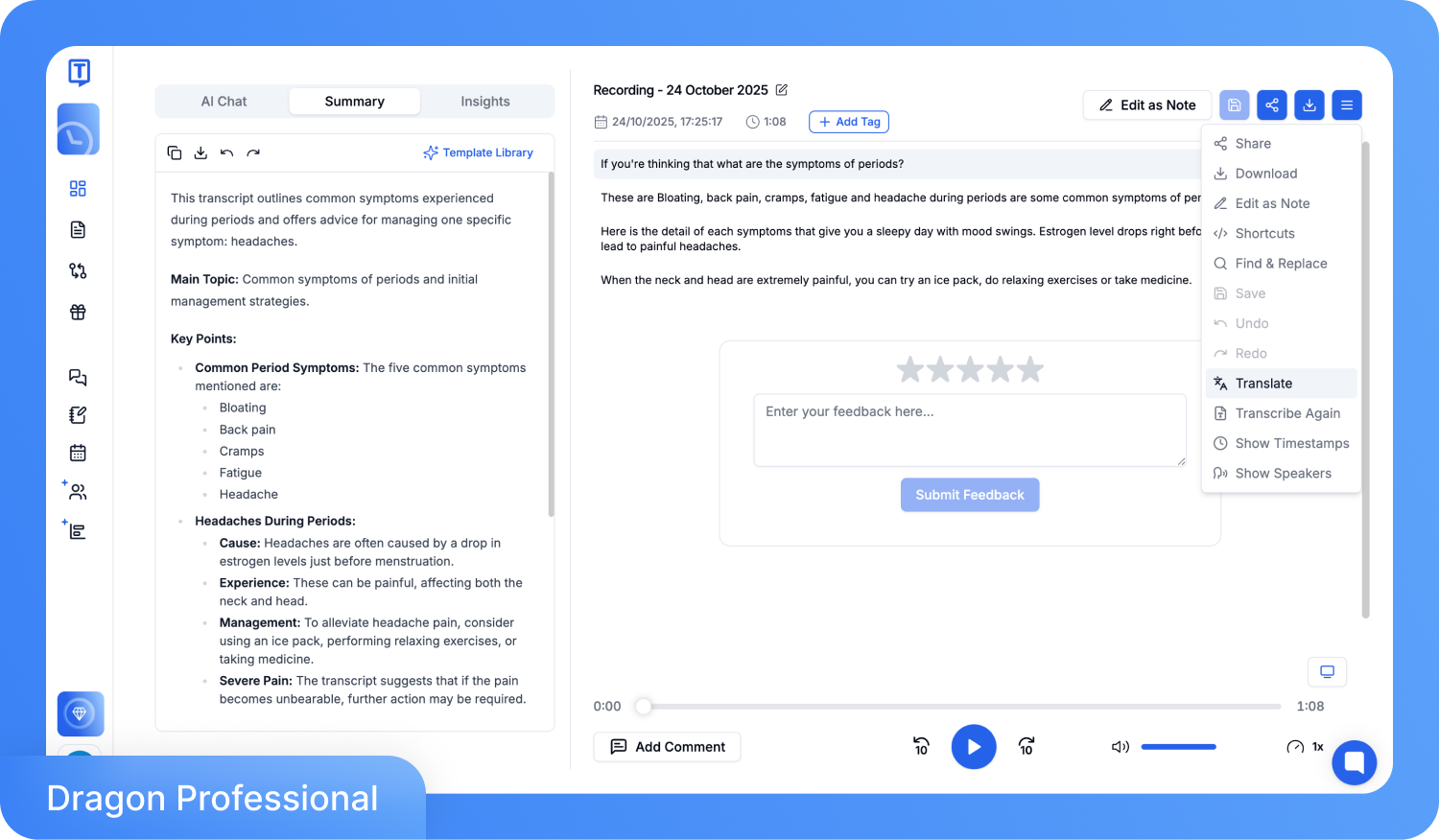
ขั้นตอนที่ 3: หลังจากผ่านไปไม่กี่นาที คุณจะได้รับเนื้อหาที่ถอดความเสร็จสมบูรณ์ คุณสามารถเปิดตัวแก้ไขในตัวเพื่อแก้ไขจุดที่ผิด เปลี่ยนชื่อผู้พูด และปรับการระบุเวลาได้ หากคุณต้องการเนื้อหาในภาษาอื่นๆ ให้คลิกตัวเลือก 'แปลภาษา'
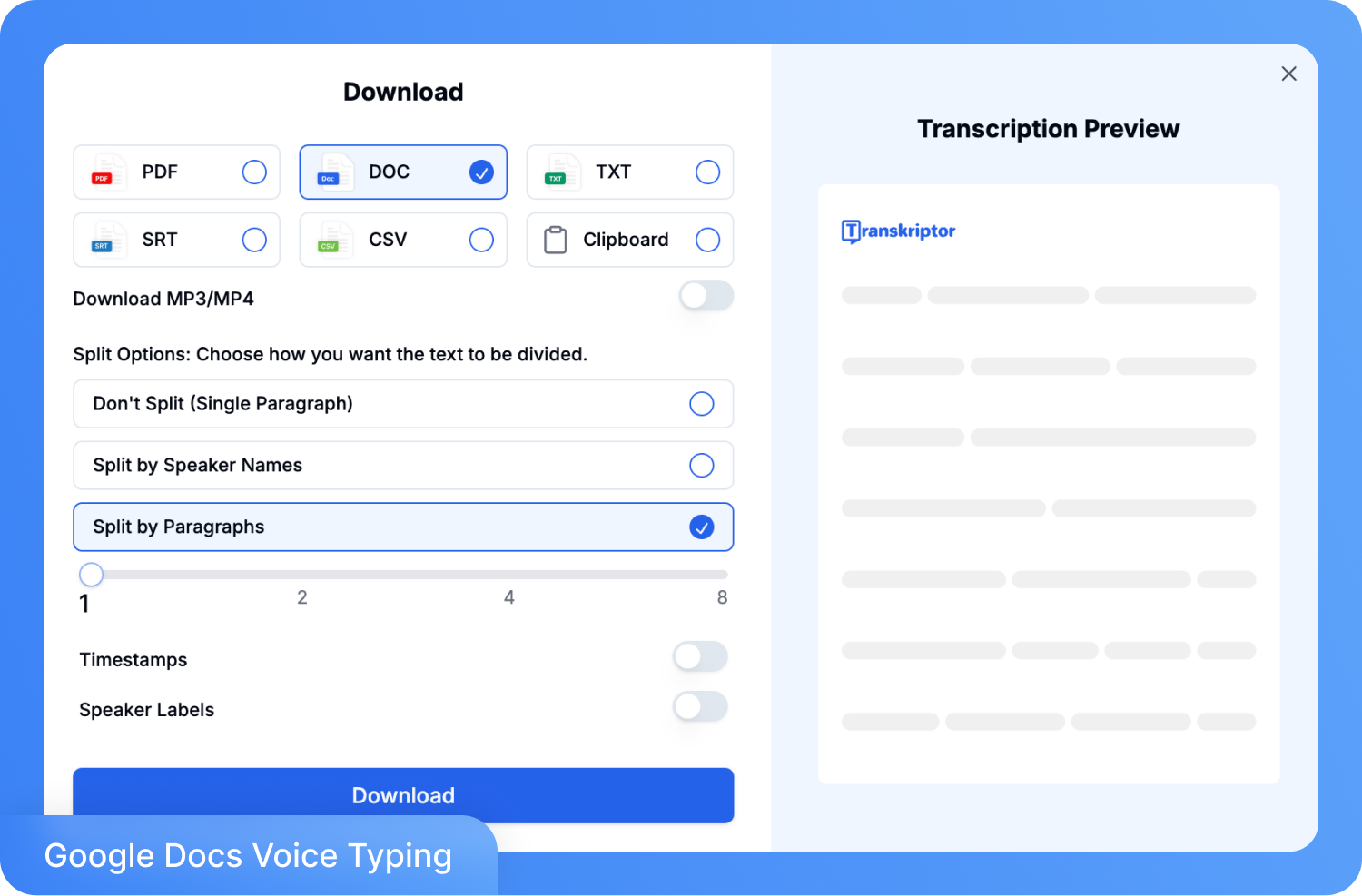
ขั้นตอนที่ 4: ส่งออกผลถอดความในรูปแบบ TXT, DOCX, SRT หรือ PDF พร้อมแชร์ให้ทีมของคุณโดยตรง หรือดาวน์โหลดเพื่อนำไปใช้ทำรายงาน คำบรรยายใต้ภาพ หรือขั้นตอนการทำเอกสารต่าง ๆ ได้ทันที
บทสรุป
ตอนนี้คุณคงได้คำตอบแล้วว่า ChatGPT สามารถถอดความเสียงได้หรือไม่ ถึงแม้ว่าจะใช้งานได้ดีสำหรับความต้องการพื้นฐาน โดยเฉพาะคลิปสั้น ๆ ชัดเจนที่มีผู้พูดคนเดียวและขนาดไฟล์ไม่เกิน 25 MB แต่หากนอกเหนือจากนั้น ข้อจำกัดจะปรากฏขึ้นทันที ทั้งไม่มีการแยกชื่อผู้พูด ไม่รองรับระบบการประชุม อัปโหลดไฟล์ไม่เสถียร และข้อจำกัดเรื่องขนาดไฟล์ที่ทำให้ไม่สามารถถอดความคลิปยาวได้ Transkriptor เข้ามาเติมเต็มทุกช่องว่างนี้ ด้วยความแม่นยำสูงถึง 99% รองรับกว่า 100 ภาษา แยกผู้พูดให้อัตโนมัติ และเชื่อมต่อกับ Zoom, Google Meet และ Microsoft Teams ได้โดยตรง เริ่มต้นใช้งานฟรีได้ที่ Transkriptor.com เพื่อรับผลถอดความที่แม่นยำภายในเวลาเพียงไม่กี่นาที