Analyse de Sentiment Alimentée par l'IA
L'analyse de sentiment basée sur l'IA de Transkriptor transforme vos enregistrements audio en insights émotionnels détaillés. Détectez avec précision le temps de parole, le ton, l'émotion et l'intention dans les appels clients, les réunions en ligne et les entretiens en convertissant automatiquement la parole en texte et en extrayant les données de sentiment vocal grâce à la transcription avancée et l'analyse de sentiment alimentées par l'IA.
Transcrivez et analysez les sentiments dans plus de 100 langues
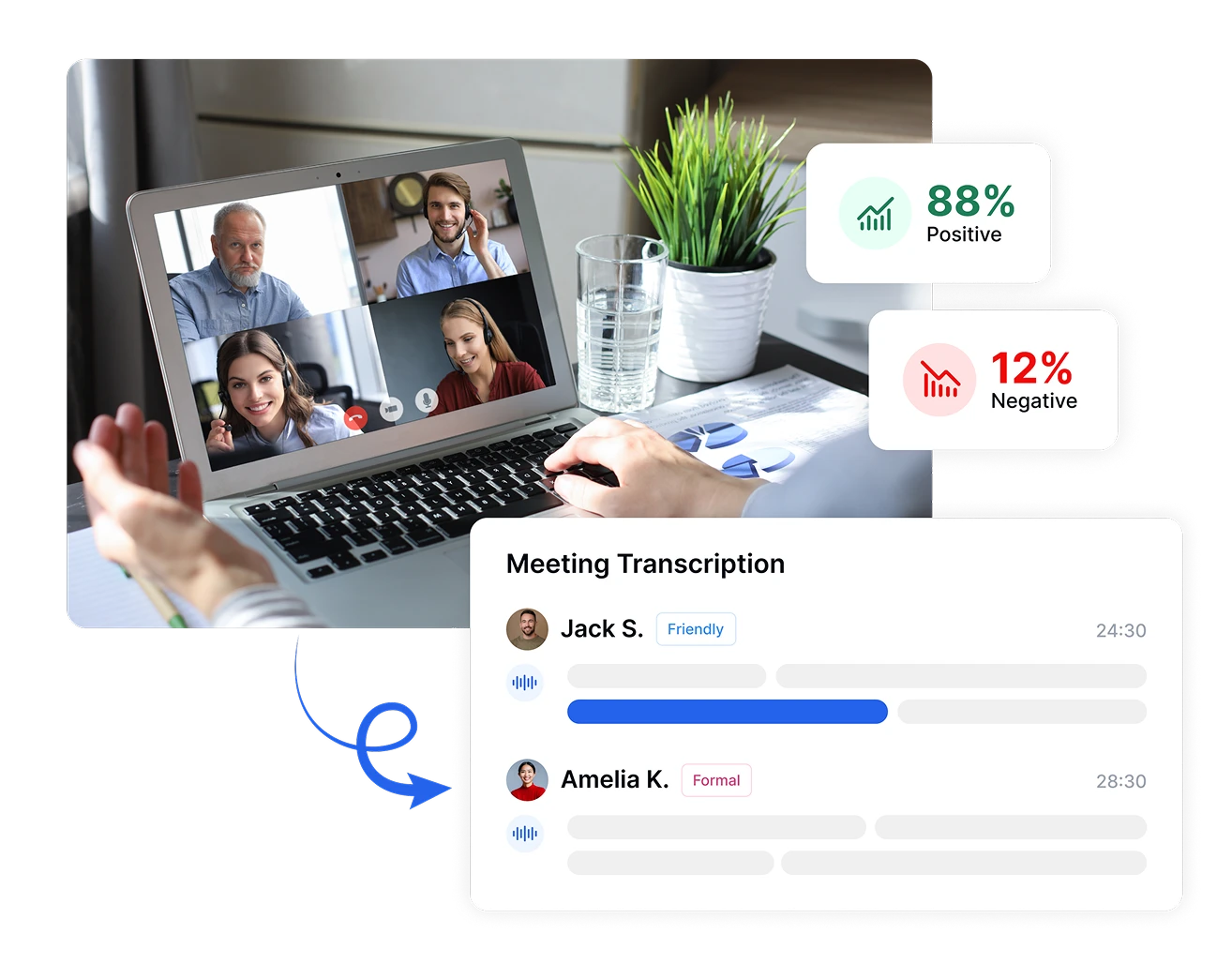
Prenez des Décisions Basées sur les Données avec l'Analyse de Sentiment
Convertissez les réponses émotionnelles subjectives en métriques objectives avec Transkriptor. Mesurez l'intensité du sentiment, suivez les changements émotionnels pendant les conversations et comparez les sentiments à travers différentes périodes ou segments de clientèle. Ces mesures précises transforment des sentiments abstraits en points de données concrets, permettant des décisions fondées sur des preuves qui améliorent la satisfaction client et les résultats commerciaux.

Analysez le Sentiment Vocal dans Plus de 100 Langues
Brisez les barrières linguistiques avec les capacités d'analyse de sentiment multilingue de Transkriptor. Détectez les nuances émotionnelles dans plus de 100 langues, permettant aux équipes mondiales de comprendre le sentiment des clients indépendamment de la région ou de la langue. Cette couverture linguistique complète assure un suivi cohérent des sentiments sur les marchés internationaux avec des taux de précision élevés jusqu'à 99%.
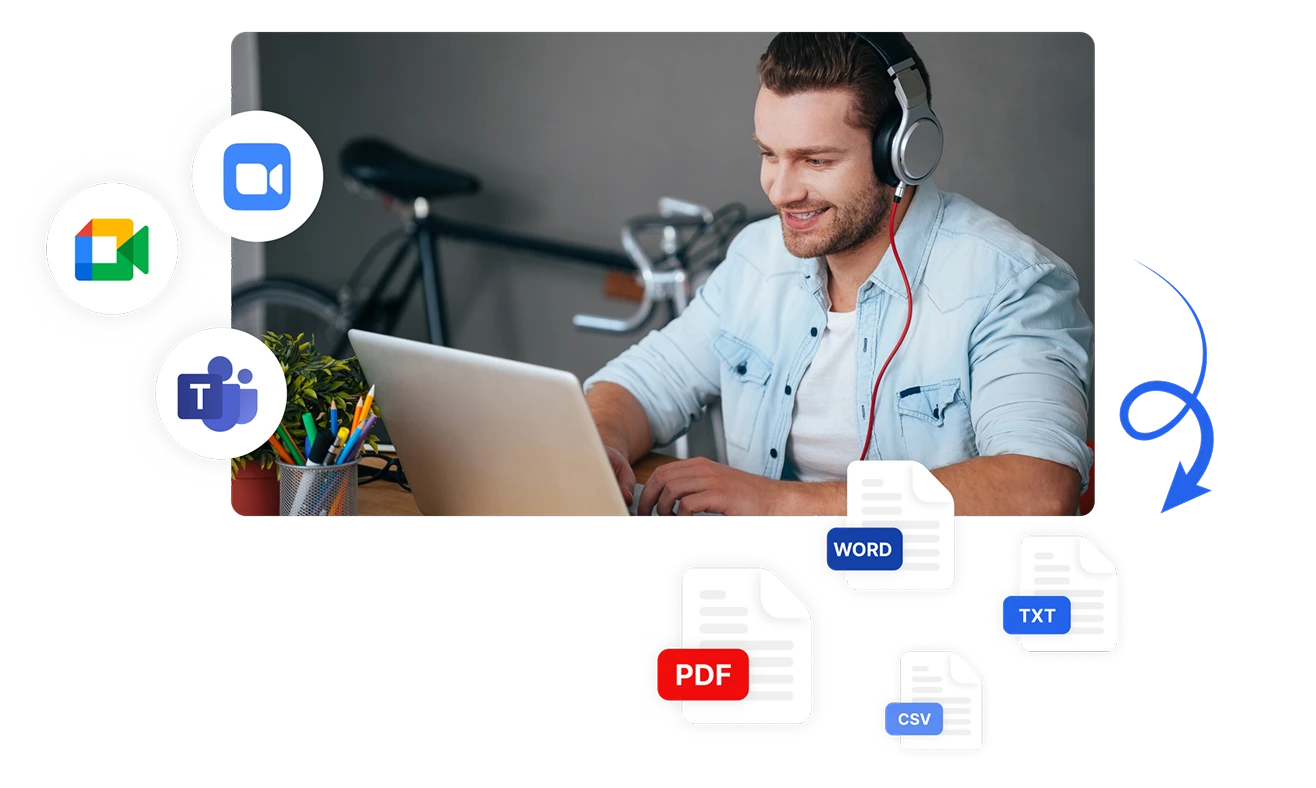
Capturez et Analysez le Sentiment sur Tous les Canaux
Analysez le sentiment à partir de multiples canaux de communication grâce aux options d'entrée polyvalentes de Transkriptor. Transcrivez et analysez automatiquement le sentiment à partir de fichiers audio téléchargés, de réunions enregistrées directement ou de plateformes intégrées comme Zoom, Microsoft Teams et Google Meet. Exportez vos résultats d'analyse de sentiment aux formats PDF, Word, TXT, CSV ou partagez-les instantanément avec les membres de votre équipe.

Analysez le sentiment vocal en 4 étapes simples
- 1ÉTAPE 1
Téléchargez votre audio ou connectez votre réunion
- 2ÉTAPE 2
Transkriptor transcrit et analyse
- 3ÉTAPE 3
Examinez l'analyse des sentiments
- 4ÉTAPE 4
Exportez ou partagez les insights des sentiments
Qui bénéficie le plus de l'analyse des sentiments de Transkriptor

Équipe de réussite client
Suivez les tendances de satisfaction client à travers toutes les interactions de service grâce à l'analyse de sentiment basée sur l'IA.

Professionnels de la vente
Optimisez les conversations de vente grâce à l'analyse de sentiment des appels avec les prospects, alimentée par l'IA.

Professionnels du droit
Analysez les modèles de sentiment dans les dépositions enregistrées, les entretiens avec les clients et les déclarations des témoins.

Professionnels des RH
Améliorez l'évaluation des entretiens et les sessions de feedback des employés avec une analyse de sentiment objective.
Solution complète d'analyse de sentiment
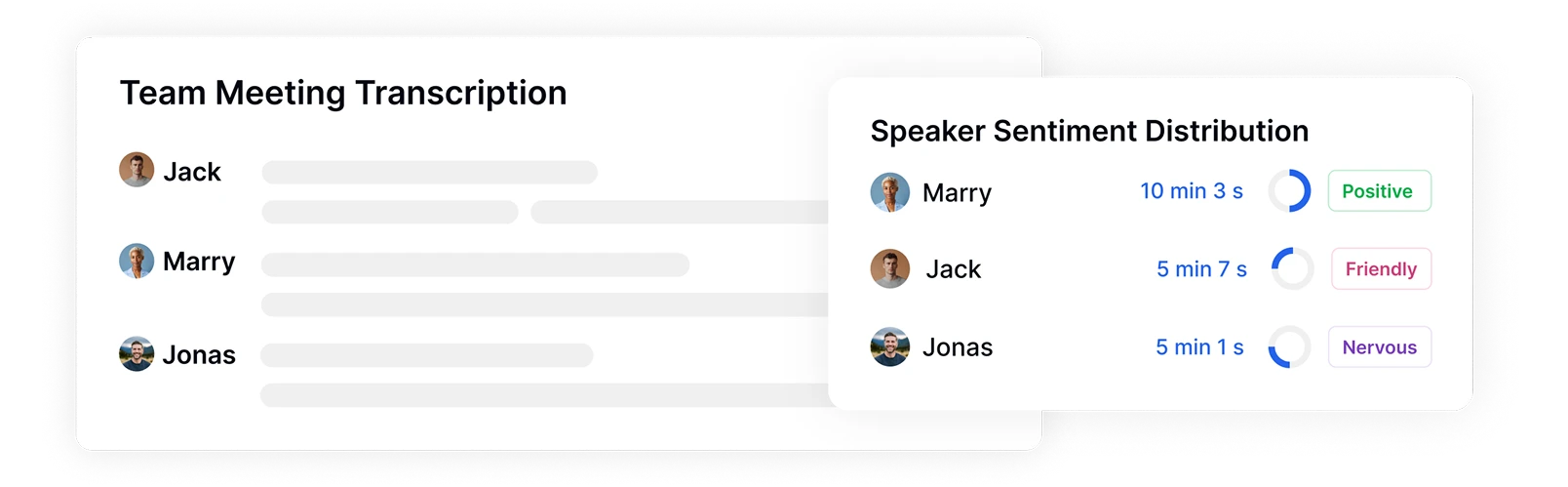
Identifier les interlocuteurs et suivre la distribution des sentiments
Transkriptor identifie et étiquette automatiquement les différents interlocuteurs dans vos enregistrements tout en mesurant leur temps de parole et leurs schémas émotionnels. Voyez exactement qui a parlé, quand, pendant combien de temps et avec quel sentiment, fournissant un contexte essentiel pour analyser les dynamiques émotionnelles entre les participants lors de réunions, d'entretiens ou d'interactions avec les clients.
Identifier les interlocuteurs et suivre la distribution des sentiments
Transkriptor identifie et étiquette automatiquement les différents interlocuteurs dans vos enregistrements tout en mesurant leur temps de parole et leurs schémas émotionnels. Voyez exactement qui a parlé, quand, pendant combien de temps et avec quel sentiment, fournissant un contexte essentiel pour analyser les dynamiques émotionnelles entre les participants lors de réunions, d'entretiens ou d'interactions avec les clients.

Générer des résumés de sentiment alimentés par l'IA
Transformez de longues conversations en résumés de sentiment concis grâce à la technologie IA de Transkriptor. Ces résumés identifient les changements clés de sentiment et quantifient le ton émotionnel global, offrant un aperçu rapide du parcours émotionnel tout au long de n'importe quelle conversation enregistrée.

Créer des bases de connaissances avec l'analyse de sentiment
Organisez des informations émotionnelles essentielles en créant des bases de connaissances personnalisées à partir de transcriptions analysées par sentiment. Stockez, catégorisez et recherchez des données de sentiment pour établir des références émotionnelles, identifier des schémas récurrents et construire un référentiel complet d'intelligence émotionnelle.
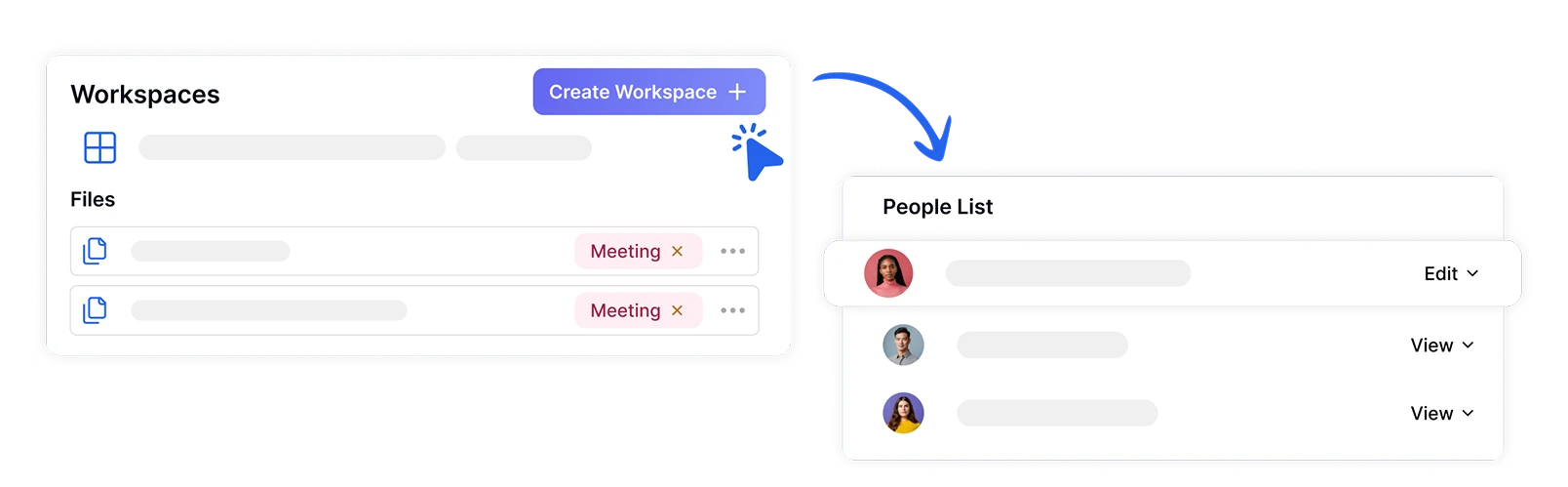
Organiser et partager des fichiers dans des espaces de travail sécurisés
Gérez les projets d'analyse de sentiment en équipe en toute sécurité en créant des espaces de travail dédiés avec des rôles et des permissions assignés. Assurez-vous que les données émotionnelles sensibles ne sont accessibles qu'aux membres autorisés de l'équipe tout en facilitant la collaboration sur les insights de sentiment entre les départements.
Sécurité de niveau entreprise
La sécurité et la confidentialité des clients sont notre priorité à chaque étape. Nous respectons les normes SOC 2 et RGPD, garantissant que vos informations sont protégées en permanence.





Témoignages clients
Réduction du taux d'attrition grâce aux données de sentiment
Transkriptor a révolutionné la façon dont notre équipe de 14 personnes gère les relations clients. En analysant le sentiment dans les appels d'intégration et de suivi, nous identifions les comptes à risque avant que les indicateurs traditionnels ne révèlent des problèmes. La prise en charge multilingue gère notre clientèle mondiale, et les modèles personnalisés aident à standardiser notre approche dans toute l'équipe.

Kira Johnson
Responsable Succès Client
30% de réduction des mauvais recrutements
Transkriptor a transformé notre processus d'entretien après 7 mois d'utilisation. L'analyse de sentiment aide à identifier les incohérences émotionnelles dans les réponses des candidats que nous pourrions manquer. Le suivi du sentiment à travers différents sujets d'entretien donne des insights plus profonds sur l'adéquation culturelle, améliorant significativement notre taux de réussite en recrutement.

Amira Khan
Directrice RH
Questions Fréquemment Posées
Le meilleur outil d'analyse de sentiment est Transkriptor. Propulsé par une IA avancée, Transkriptor transcrit automatiquement le contenu parlé et analyse le ton émotionnel avec une grande précision. Il étiquette les conversations comme positives, négatives ou neutres, et prend en charge plus de 100 langues.
L'analyse de sentiment fonctionne en utilisant l'intelligence artificielle et le traitement du langage naturel (NLP) pour évaluer le ton émotionnel du texte ou de la parole. Elle identifie les indicateurs clés d'émotion tels que le choix des mots, la structure des phrases et les indices contextuels pour classer le contenu comme positif, négatif ou neutre. Les systèmes plus avancés peuvent également détecter l'intention, les changements émotionnels et le sentiment spécifique à l'orateur au fil du temps.
Transkriptor vous permet de créer des espaces de travail personnalisés avec des permissions basées sur les rôles pour organiser les projets d'analyse de sentiment. Vous pouvez également construire des bases de connaissances en utilisant du contenu étiqueté par sentiment, ce qui facilite le stockage, la catégorisation et la recherche de données émotionnelles tout en maintenant la sécurité et l'accessibilité.
L'analyse de sentiment aide les équipes de service client à identifier les déclencheurs émotionnels dans les conversations, à mesurer l'efficacité des techniques de désescalade et à suivre le sentiment des clients tout au long du processus de support. Ces informations permettent aux équipes d'affiner leur approche, conduisant à une amélioration de la satisfaction client et à une réduction des appels répétés.
Oui, Transkriptor prend en charge l'analyse de sentiment dans plus de 100 langues avec une grande précision. Le système est conçu pour reconnaître les nuances culturelles et linguistiques spécifiques à chaque langue, assurant une détection cohérente du sentiment quelle que soit la langue maternelle du locuteur.
Accédez à Transkriptor Partout
Enregistrez en direct ou téléchargez des fichiers audio et vidéo à transcrire. Modifiez vos transcriptions facilement, et utilisez l'assistant IA pour discuter avec ou résumer les transcriptions.