AI驱动的情感分析
Transkriptor的AI驱动情感分析将您的音频录音转化为详细的情感洞察。通过自动将语音转文字并提取语音情感数据,准确检测客户通话、在线会议和访谈中的说话人时间、语调、情感和意图,采用先进的AI转录和情感分析技术。
支持100+语言的转录与情感分析
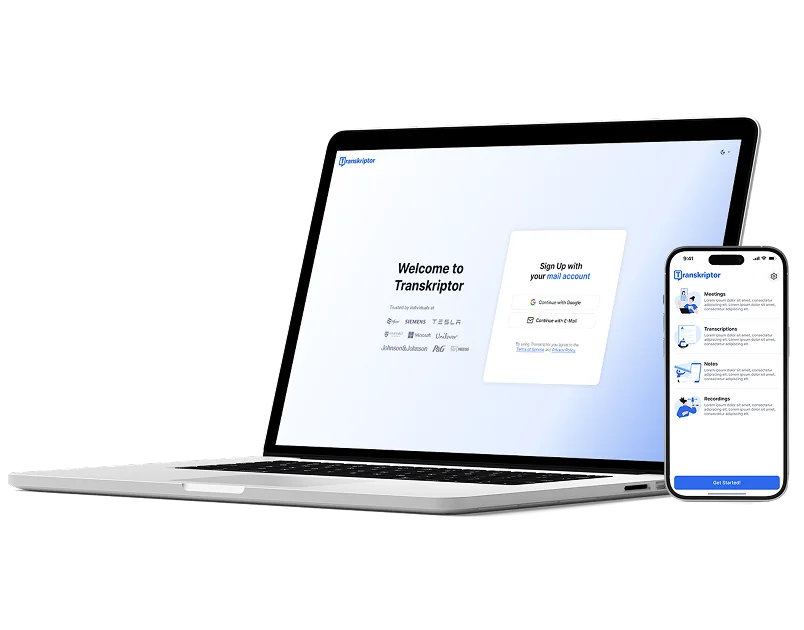
利用情感分析做出数据驱动的决策
通过Transkriptor将主观的情感反应转化为客观指标。衡量情感强度,追踪对话中的情感变化,并比较不同时间段或客户群体的情感。这些精准的测量将抽象的情感转化为具体的数据点,帮助做出基于证据的决策,提升客户满意度和业务成果。

支持100+语言的语音情感分析
借助Transkriptor的多语言情感分析功能打破语言障碍。在超过100种语言中检测情感细微差别,让全球团队理解客户情绪,无论地区或语言。这一全面的语言覆盖确保在国际市场中实现一致的情感追踪,准确率高达99%。
捕捉并分析所有渠道的情感
利用Transkriptor多样的输入选项分析多渠道的情感。从上传的音频文件、直接录制的会议或集成平台如Zoom、Microsoft Teams和Google Meet自动转录并分析情感。导出PDF、Word、TXT、CSV格式的分析结果,或即时与团队成员分享。
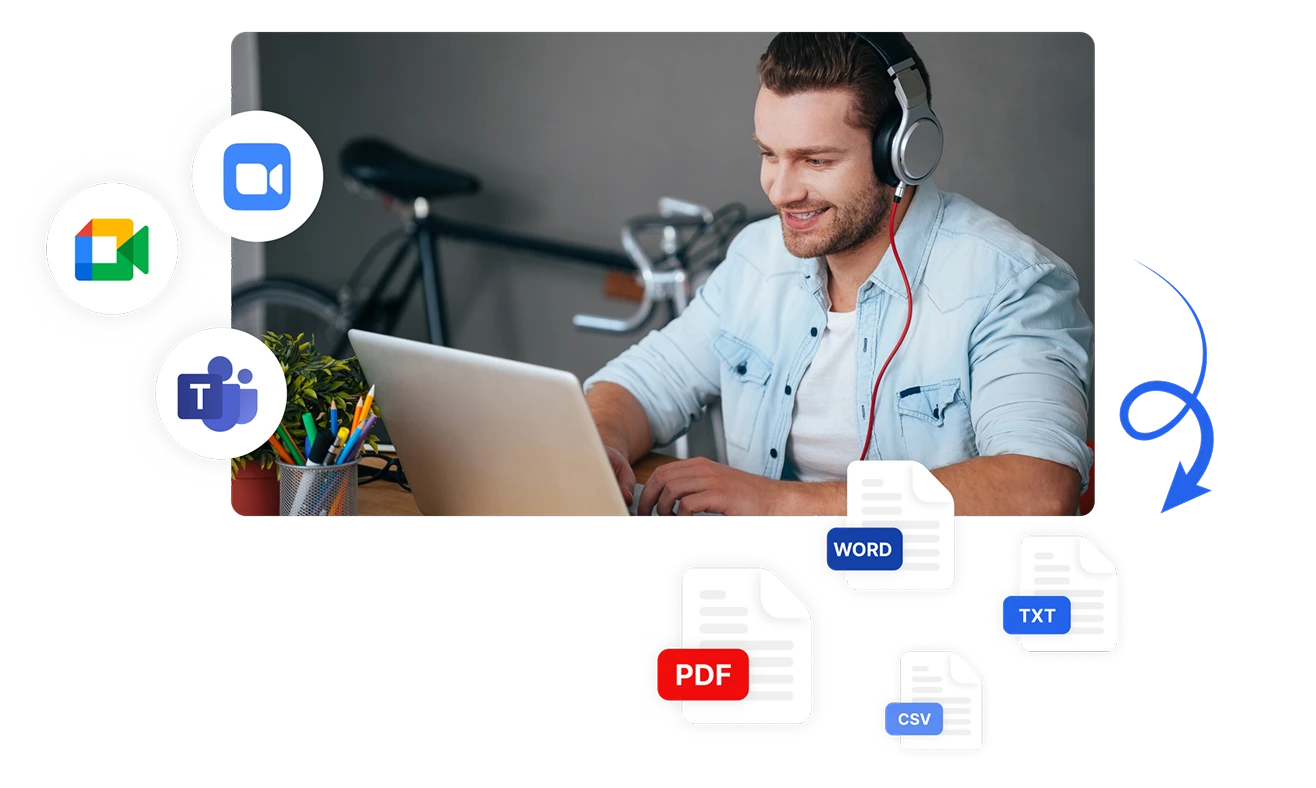

只需4个简单步骤分析语音情感
- 1步骤 1
上传您的音频或连接您的会议
- 2步骤 2
Transkriptor转录并分析
- 3步骤 3
查看情感分析
- 4步骤 4
导出或分享情感洞察
谁能从Transkriptor的情感分析中获益最多

客户成功团队
通过AI驱动的情感分析,跟踪所有服务互动中的客户满意度趋势。

销售专业人员
利用AI驱动的潜在客户通话情感分析,优化销售对话。

法律专业人员
分析录制的证词、客户访谈和证人陈述中的情感模式。

人力资源专业人员
通过客观的情感分析,改进面试评估和员工反馈会议。
全方位情感分析解决方案
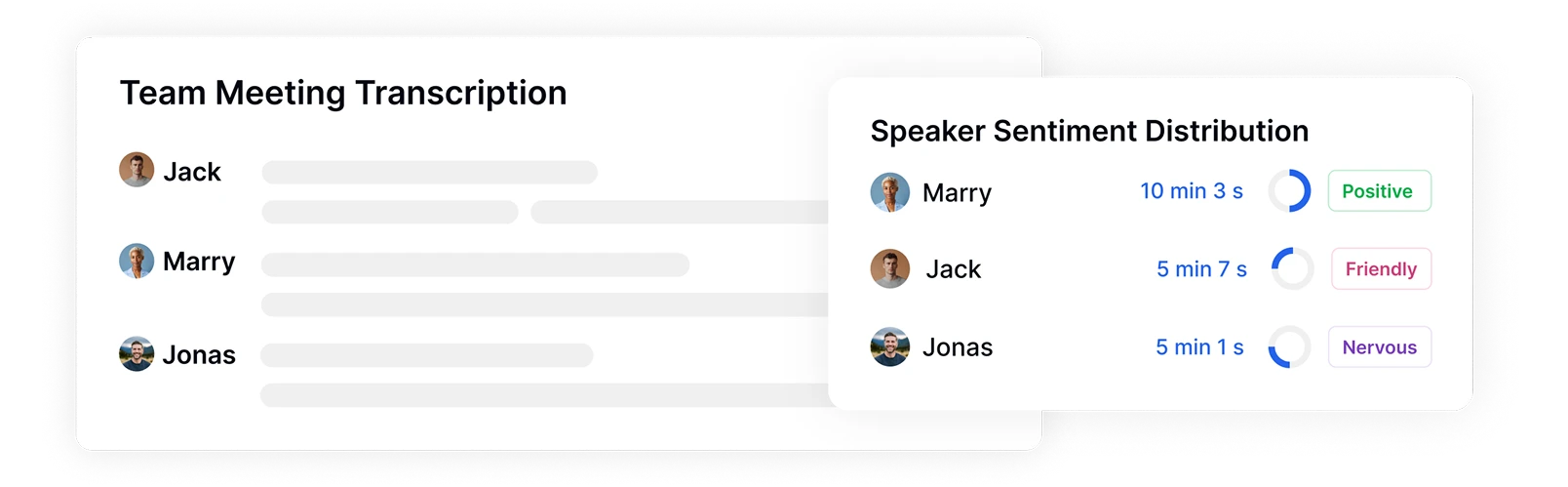
识别发言者并追踪情感分布
Transkriptor自动识别并标记录音中的不同发言者,同时测量他们的发言时间和情感模式。准确查看谁在何时发言、发言多长时间以及带有什么情感,为分析会议、访谈或客户互动中参与者之间的情感动态提供关键背景。
识别发言者并追踪情感分布
Transkriptor自动识别并标记录音中的不同发言者,同时测量他们的发言时间和情感模式。准确查看谁在何时发言、发言多长时间以及带有什么情感,为分析会议、访谈或客户互动中参与者之间的情感动态提供关键背景。

生成AI驱动的情感摘要
通过Transkriptor的AI技术,将冗长的对话转化为简洁的情感摘要。这些摘要识别关键情感转变,并量化整体情感基调,提供任何录制对话中情感旅程的快速概览。

利用情感分析构建知识库
通过使用经情感分析的转录内容创建自定义知识库,组织重要的情感洞察。存储、分类并搜索情感数据,建立情感基准,识别重复出现的模式,并构建全面的情感智能库。
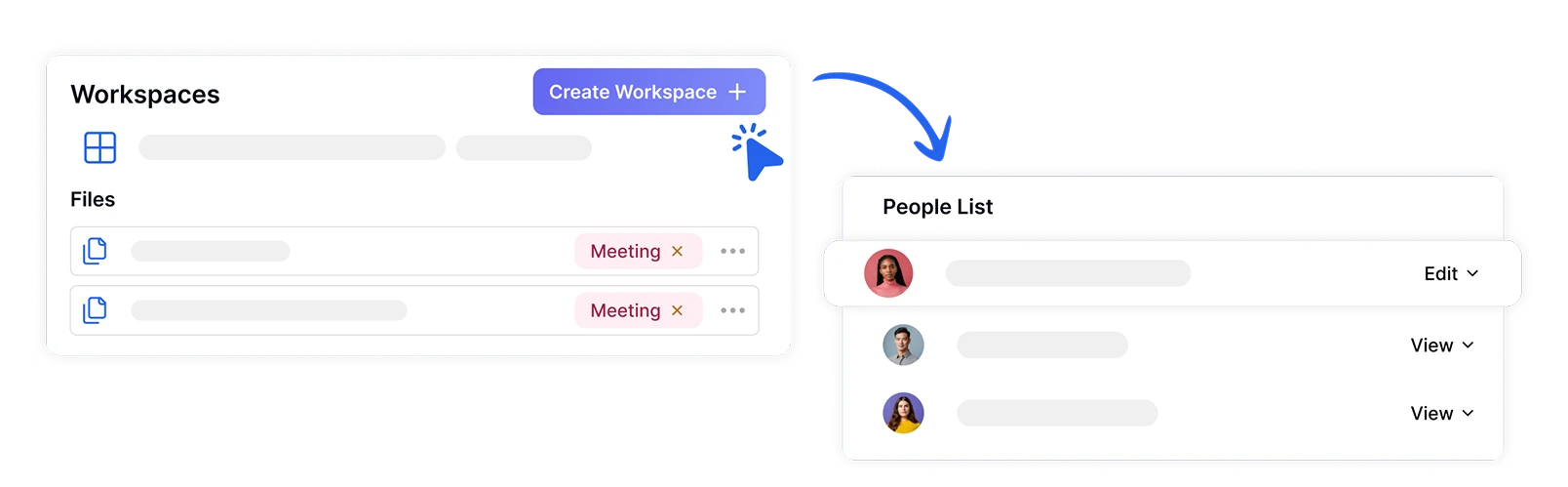
在安全工作区中组织和共享文件
通过创建具有指定角色和权限的专用工作区,安全地管理团队情感分析项目。确保敏感的情感数据仅对授权团队成员可访问,同时促进跨部门对情感洞察的协作。
企业级安全
安全和客户隐私是我们每一步的优先考虑。我们遵守SOC 2和GDPR标准,确保您的信息始终受到保护。





客户成功案例
利用情感数据减少客户流失
Transkriptor彻底改变了我们14人团队管理客户关系的方式。通过分析入职和定期回访通话中的情感,我们能在传统指标显示问题之前识别出有风险的账户。多语言支持能够应对我们的全球客户群,而定制模板则帮助我们在团队中标准化工作方法。

Kira Johnson
客户成功主管
不良招聘减少30%
在使用7个月后,Transkriptor已经改变了我们的面试流程。情感分析帮助识别候选人回答中我们可能忽略的情感不一致性。跟踪不同面试话题的情感变化,为文化契合度提供更深入的见解,显著提高了我们的招聘成功率。

Amira Khan
人力资源总监
常见问题
最好的情感分析工具是Transkriptor。由先进的AI驱动,Transkriptor自动转录口语内容并以高精度分析情感基调。它将对话标记为积极、消极或中性,并支持超过100种语言。
情感分析通过使用人工智能和自然语言处理(NLP)来评估文本或语音的情感基调。它识别情感的关键指标,如词汇选择、句子结构和上下文线索,将内容分类为积极、消极或中性。更高级的系统还可以检测意图、情感变化以及随时间推移的特定说话者情感。
Transkriptor允许您创建具有基于角色权限的自定义工作空间,用于组织情感分析项目。您还可以使用带有情感标签的内容构建知识库,使存储、分类和搜索情感数据变得容易,同时保持安全性和可访问性。
情感分析帮助客户服务团队识别对话中的情感触发点,衡量缓和技巧的有效性,并跟踪整个支持过程中的客户情感。这些见解使团队能够改进他们的方法,从而提高客户满意度并减少重复来电。
是的,Transkriptor支持100多种语言的高精度情感分析。该系统设计为能够识别每种语言特有的文化和语言细微差别,确保无论说话者的母语如何,都能保持一致的情感检测。
随时随地访问Transkriptor
录制实时音频或上传音频和视频文件进行转录。轻松编辑您的转录内容,并使用AI助手与转录内容聊天或进行摘要。