
Skapa ditt konto och spela in eller ladda upp en fil
Skapa ditt Transkriptor-konto och kom igång med gratis transkribering. Spela in eller ladda upp ditt ljud/video för att börja transkribera ljud till text direkt.
Transkribera ljud till text direkt från möten, intervjuer, samtal och föreläsningar till precisa transkript—börja med gratis AI-transkribering och lås upp värdefulla insikter från dina konversationer.
Konvertera ljud till text på över 100 språk
Fungerar med
Konvertera lokal video eller ljudfil till text
Ladda upp en ljud- eller videofil från din lokala enhet och transkribera gratis.
Klicka för att ladda upp och transkribera gratis
Spela in ljud och konvertera till text
Spela in ditt ljud direkt och konvertera ljud till text gratis.
Betrodd av individer på


Konvertera ljud till text med det högst rankade transkriptions-tillägget för Chrome. Spela direkt in din skärm, kamera eller mikrofon och få exakta tal-till-text-transkriptioner direkt från din webbläsare.
Konvertera enkelt video till text gratis med vår kraftfulla transkriberingsmotor - ingen filkonvertering behövs. Vi stödjer ett brett utbud av format, inklusive MP3, MP4, WAV och mer. Du kan transkribera vilket innehåll som helst snabbt och utan kompatibilitetsproblem.
Anslut Transkriptor till molnlagring, CRM och andra appar via Zapier för att automatiskt transkribera mediafiler och skicka dina korrekta transkriptioner till dina föredragna plattformar, vilket sparar tid och håller ditt transkriberade innehåll perfekt organiserat.
Skapa ditt Transkriptor-konto och kom igång med gratis transkribering. Spela in eller ladda upp ditt ljud/video för att börja transkribera ljud till text direkt.
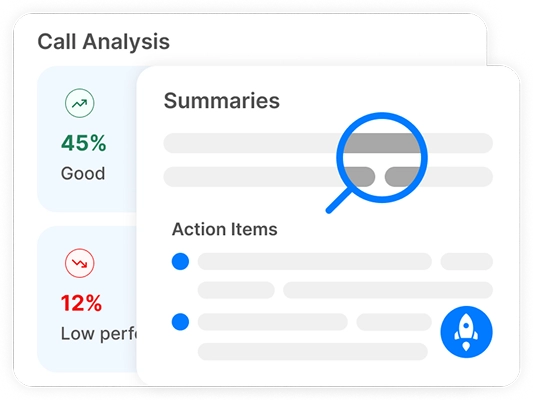
Transkriptor erbjuder fullt redigerbara transkriptioner, AI-driven analys av samtalssentiment, AI-sammanfattningar och uppdelning av viktiga ämnen.
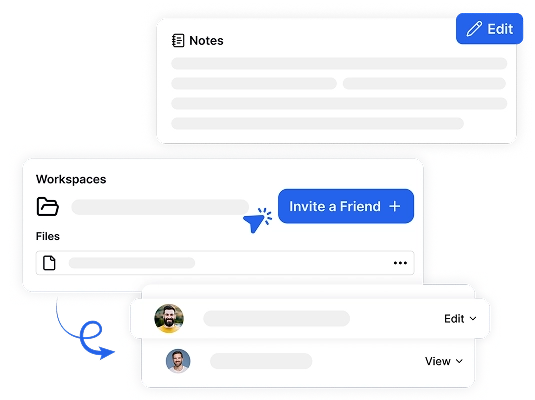
Dina anteckningar och ljudtranskriptioner lagras säkert för enkel åtkomst. Organisera dina mötesanteckningar och sökbara utskrifter i mappar och arbetsytor.
Utnyttja vår AI-transkriptionsteknik för att extrahera insikter och kunskapsbaser från flera filer och ställa frågor eller tala med dina röst-till-text-transkriptioner.
Skapa ditt Transkriptor-konto och kom igång med gratis transkribering. Spela in eller ladda upp ditt ljud/video för att börja transkribera ljud till text direkt.

Säker, exakt medicinsk transkribering utformad för vårdpersonal. Omvandla patientinteraktioner till organiserade kliniska utskrifter direkt.

Förvandla kundmöten till organiserade, sökbara affärsutskrifter. Få omedelbara transkriberade insikter, viktiga resultat och AI-driven transkriptionsanalys för bättre kundresultat.

Fokusera helt på dina klienter medan Transkriptor fungerar som din professionella transkriberare för terapisessioner. Få organiserade sessionsanteckningar, framstegsspårning och säker dokumentation automatiskt.

Förvandla kundmöten till sökbara transkriptioner med juridisk transkriptionsteknik. Få tillgång till omedelbara inspelningar av diskussioner samtidigt som du behåller konfidentialiteten.

Snabb och exakt medietranskribering för sändningar och innehållsproduktion. Konvertera ljud till text direkt, med stöd för flera format och språk.
Omvandla dina videor till tillgängligt innehåll med snabba transkriptionstjänster och automatisk textning på över 100 språk.
Ställ frågor, få sammanfattningar och extrahera insikter från ditt transkriberade innehåll direkt.
Hantera åtkomst, dela filer och samarbeta sömlöst i dedikerade arbetsytor.
Lägg till anpassade taggar till dina filer. Hitta viktiga ögonblick snabbt och organisera innehåll på ditt sätt.
Analysera tonen och känslan i transkriberade möten. Perfekt för kundservice och teamkommunikation.
Spåra fördelningen av taltid och deltagarnivåer i konversationer.
Lås upp kraften i avancerad AI-transkribering för varje aspekt av ditt arbete. Prova det gratis - höj produktiviteten, förenkla arbetsflödet!
Förvandla tal till korrekta transkriptioner på några sekunder. Professionell transkriberingsteknik för ljud- och videoinnehåll, så att du kan fokusera på insikter och inte på att göra anteckningar.
Fånga varje ögonblick med skärpa. Spela in och transkribera din skärm enkelt för självstudier, presentationer med mera – granska och sök efter transkriberat innehåll när du behöver det.
Missa aldrig en detalj igen. Automatiserad transkription, AI mötessammanfattningar och åtgärdspunkter från dina möten, vilket förvandlar konversationer till sökbara transkriptioner samtidigt som produktiviteten förbättras.
Ge texten liv med naturliga röster. Konvertera skriven text till realistiska talade ord, vilket förbättrar tillgängligheten och engagemanget.
Enkelt innehåll, perfekt skrivet. Transkribera dina idéer till högkvalitativt, engagerande innehåll som är skräddarsytt för din publik med minimal input.
Ditt teams transkriberade kunskap är bara ett klick bort. Centraliserad AI kunskapsbas som organiserar, hämtar och effektiviserar transkriberade konversationer sömlöst.
Transkriptor prioriterar säkerhet och integritet på alla nivåer. Vår transkriptionsplattform i företagsklass uppfyller standarderna SOC 2, GDPR, ISO 27001 och SSL för att säkerställa att dina ljud- och videodata är helt skyddade och säkert transkriberade.




Transkriptors kraftfulla AI-antecknare genererar onlinetranskriptioner på sekunder medan de flesta tjänster tar mer än 10 minuter.
Få upp till 99% noggrannhet när du transkriberar dina ljudfiler med Transkriptor. Transkribera eller översätt ljudinnehåll på över 100 språk enkelt.
Få valuta för pengarna med Transkriptors kompletta utbud av produktivitetsfunktioner och intuitiva lösningar till ett överkomligt pris.
Transkribering är processen att omvandla talat språk från ljud- eller videoinspelningar till skriven text. Det används ofta för möten, intervjuer, föreläsningar, podcasts och medieinnehåll. Transkribering kan göras manuellt av mänskliga transkriberare eller automatiskt med hjälp av AI-transkriberingsprogram.
Transkribering fungerar genom att omvandla talade ord från ljud eller video till skriven text. Du laddar upp en fil till ett verktyg som Transkriptor, som använder AI för att upptäcka tal, identifiera talare och generera en tidsstämplad transkription. Du kan sedan granska och redigera texten och exportera den i format som TXT, DOCX eller undertexter (SRT/VTT).
Fördelarna med transkription inkluderar förbättrad tillgänglighet, bättre sökbarhet av innehåll och ökad produktivitet. Det omvandlar talat innehåll till skriven text som är lätt att läsa och återanvända. Transkription stödjer också SEO genom att skapa indexerbart innehåll. AI-transkriptionsverktyg som Transkriptor automatiserar processen, vilket sparar tid och resurser.
Transkriptionens noggrannhet påverkas av flera faktorer, bland annat ljudkvalitet, bakgrundsljud, talarens tydlighet, överlappande dialog, accenter och antalet talare. Dåligt inspelat ljud eller starka accenter kan minska effektiviteten hos AI-transkriptionsverktyg. Mikrofoner av hög kvalitet, tydligt tal och minimala avbrott förbättrar resultaten.
Ja, moderna transkriberingsverktyg som Transkriptor kan hantera flera talare med hjälp av teknik för talardiarisering. Den här funktionen identifierar och etiketterar varje talare i utskriften, vilket gör det lättare att följa konversationer i möten, intervjuer eller gruppdiskussioner.
Den bästa transkriberingsprogramvaran är Transkriptor. Den erbjuder mycket exakt AI-driven transkribering med upp till 99% noggrannhet. Transkriptor stöder över 100 språk, låter användare ladda upp ljud- eller videofiler i olika format och inkluderar funktioner som talaridentifiering, undertextgenerering och en inbyggd transkriptredigerare. Andra populära transkriberingsverktyg inkluderar Otter.ai och Fireflies.ai, som också erbjuder AI-baserade transkriberingstjänster. Transkriptor föredras dock för sin bredare språktäckning, prisvärda prissättning och effektiva redigeringsfunktioner som stöder både tillfälliga användare och proffs.
Du kan göra sentimentanalyser för konversationer med hjälp av AI-drivna verktyg som Transkriptor. Transkriptors mötesbot kan gå med i dina onlinemöten direkt eller analysera uppladdade inspelningar. Efter transkriptionen utvärderar den automatiskt den känslomässiga tonen i samtalet och klassificerar segment som positiva, neutrala eller negativa.
Den bästa konverteraren från ljud till text är Transkriptor. Den använder avancerad AI för att exakt konvertera talat ljud till skriven text på bara några sekunder. Transkriptor stödjer populära ljudformat som MP3, WAV och M4A, och fungerar på över 100 språk.
Det bästa kostnadsfria transkriptionsverktyget är Transkriptor. Det erbjuder mycket noggranna och AI-drivna tal-till-text-tjänster, även i gratisversionen. Med Transkriptors kostnadsfria transkriptionsalternativ kan du transkribera upp till 30 minuter ljud per dag.













