Анализ тональности на базе ИИ
Анализ тональности Transkriptor на базе ИИ превращает ваши аудиозаписи в детальные эмоциональные инсайты. Точно определяйте время выступления, тон, эмоции и намерения говорящих в клиентских звонках, онлайн-встречах и интервью, автоматически преобразуя речь в текст и извлекая данные о тональности голоса с помощью продвинутой транскрипции и анализа тональности на базе ИИ.
Транскрибируйте и анализируйте тональность на 100+ языках
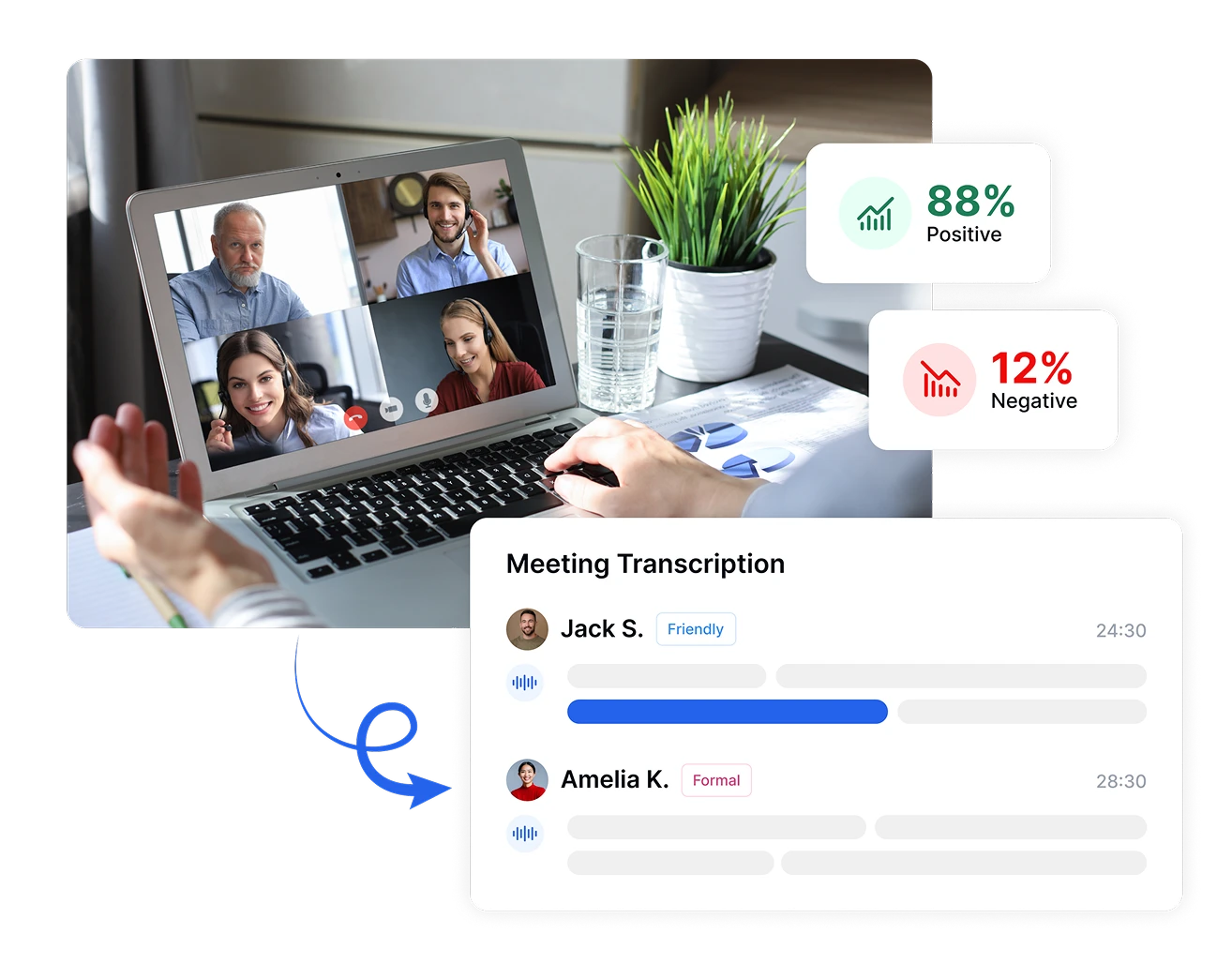
Принимайте решения на основе данных с анализом тональности
Преобразуйте субъективные эмоциональные реакции в объективные метрики с Transkriptor. Измеряйте интенсивность тональности, отслеживайте эмоциональные сдвиги во время разговоров и сравнивайте тональность в разные периоды времени или между сегментами клиентов. Эти точные измерения превращают абстрактные чувства в конкретные данные, позволяя принимать обоснованные решения, которые улучшают удовлетворенность клиентов и бизнес-результаты.

Анализируйте тональность голоса на более чем 100 языках
Преодолевайте языковые барьеры с возможностями многоязычного анализа тональности Transkriptor. Определяйте эмоциональные нюансы на более чем 100 языках, позволяя глобальным командам понимать настроение клиентов независимо от региона или языка. Это всестороннее языковое покрытие обеспечивает последовательное отслеживание тональности на международных рынках с высокой точностью до 99%.
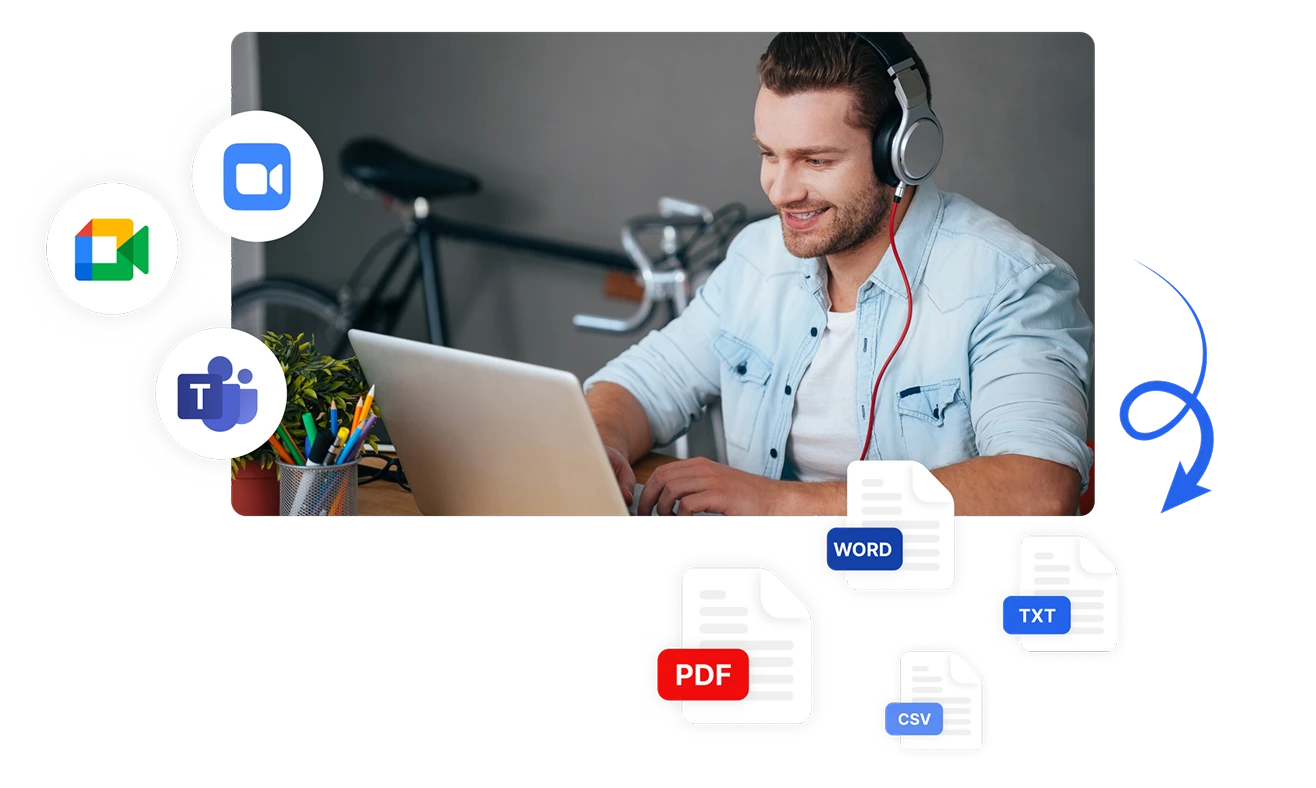
Фиксируйте и анализируйте тональность по всем каналам
Анализируйте тональность из нескольких каналов коммуникации с универсальными вариантами ввода Transkriptor. Автоматически транскрибируйте и анализируйте тональность из загруженных аудиофайлов, напрямую записанных встреч или интегрированных платформ, таких как Zoom, Microsoft Teams и Google Meet. Экспортируйте результаты анализа тональности в форматах PDF, Word, TXT, CSV или мгновенно делитесь ими с членами команды.

Анализ тональности голоса всего за 4 простых шага
- 1ШАГ 1
Загрузите аудио или подключите встречу
- 2ШАГ 2
Transkriptor транскрибирует и анализирует
- 3ШАГ 3
Просмотр анализа тональности
- 4ШАГ 4
Экспорт или обмен аналитикой тональности
Кому больше всего полезен анализ тональности от Transkriptor

Команда по работе с клиентами
Отслеживайте тенденции удовлетворенности клиентов во всех взаимодействиях с помощью анализа настроений на базе ИИ.

Специалисты по продажам
Оптимизируйте продажи с помощью анализа настроений потенциальных клиентов на основе ИИ.

Юристы
Анализируйте модели настроений в записанных показаниях, интервью с клиентами и свидетельских показаниях.

HR-специалисты
Улучшайте оценку собеседований и сессии обратной связи с сотрудниками с помощью объективного анализа настроений.
Комплексное решение для анализа тональности
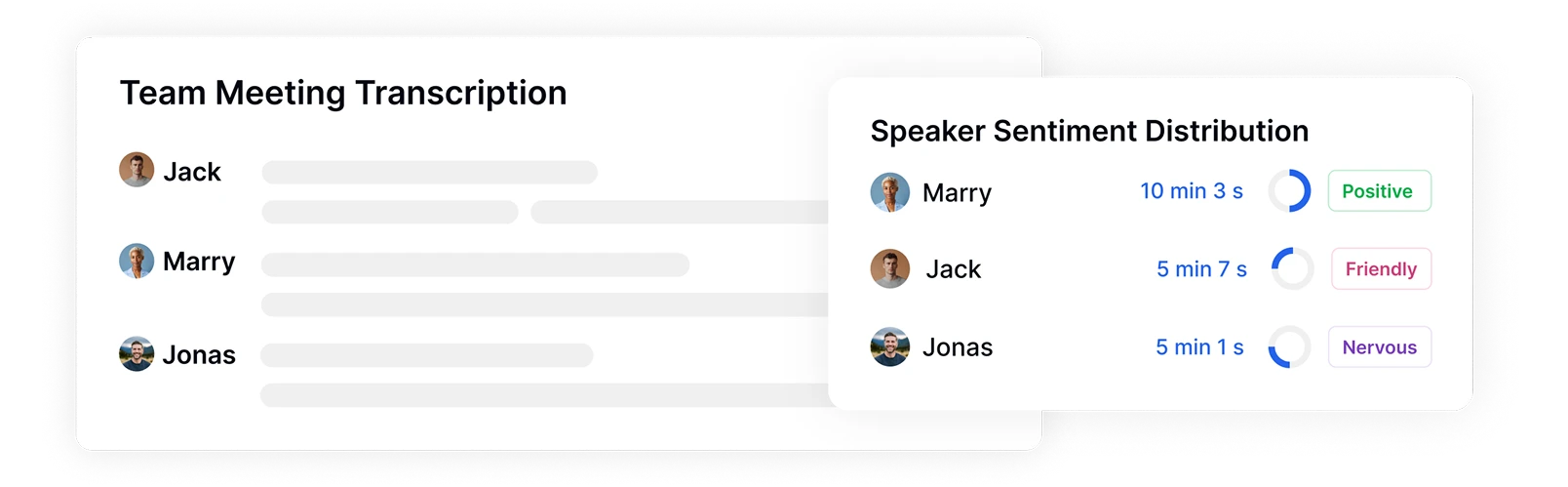
Идентификация говорящих и отслеживание распределения тональности
Transkriptor автоматически идентифицирует и отмечает разных говорящих в ваших записях, измеряя их время разговора и эмоциональные паттерны. Видите точно, кто говорил, когда, как долго и с какой тональностью, предоставляя критически важный контекст для анализа эмоциональной динамики между участниками во время встреч, интервью или взаимодействия с клиентами.
Идентификация говорящих и отслеживание распределения тональности
Transkriptor автоматически идентифицирует и отмечает разных говорящих в ваших записях, измеряя их время разговора и эмоциональные паттерны. Видите точно, кто говорил, когда, как долго и с какой тональностью, предоставляя критически важный контекст для анализа эмоциональной динамики между участниками во время встреч, интервью или взаимодействия с клиентами.

Создание сводок тональности с помощью ИИ
Превратите длительные разговоры в краткие сводки тональности с помощью ИИ-технологии Transkriptor. Эти сводки выявляют ключевые изменения настроения и количественно оценивают общий эмоциональный тон, предоставляя быстрый обзор эмоционального пути на протяжении любого записанного разговора.

Создание баз знаний с анализом тональности
Организуйте важные эмоциональные инсайты, создавая пользовательские базы знаний с использованием транскриптов с анализом тональности. Храните, категоризируйте и ищите данные о тональности, чтобы установить эмоциональные ориентиры, выявить повторяющиеся паттерны и создать комплексное хранилище эмоционального интеллекта.
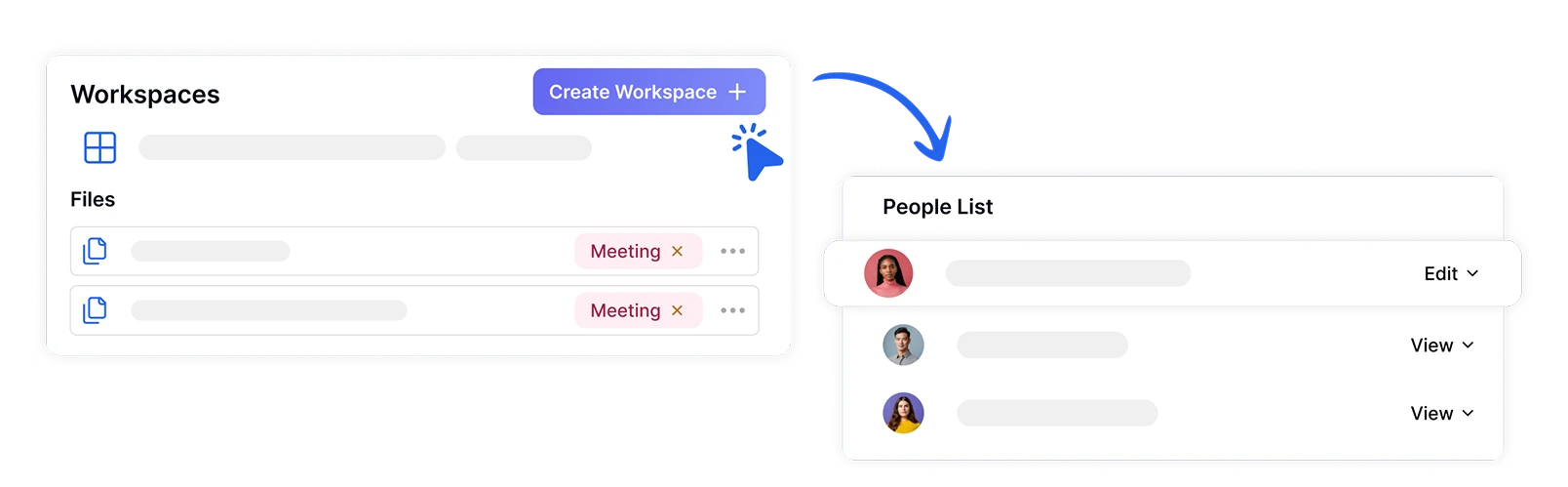
Организация и обмен файлами в защищенных рабочих пространствах
Управляйте проектами по анализу тональности команды безопасно, создавая выделенные рабочие пространства с назначенными ролями и разрешениями. Обеспечьте доступ к конфиденциальным эмоциональным данным только авторизованным членам команды, одновременно облегчая сотрудничество по инсайтам о тональности между отделами.
Безопасность корпоративного уровня
Безопасность и конфиденциальность клиентов — наш приоритет на каждом этапе. Мы соответствуем стандартам SOC 2 и GDPR, обеспечивая защиту вашей информации в любое время.





Истории успеха клиентов
Снижение оттока клиентов с помощью данных о тональности
Transkriptor революционизировал способ управления отношениями с клиентами для нашей команды из 14 человек. Анализируя настроения в звонках по адаптации и проверке, мы выявляем проблемные аккаунты до того, как это покажут традиционные метрики. Поддержка нескольких языков справляется с нашей глобальной клиентской базой, а настраиваемые шаблоны помогают стандартизировать наш подход во всей команде.

Kira Johnson
Руководитель службы поддержки клиентов
Сокращение неудачных наймов на 30%
Transkriptor преобразил наш процесс собеседований за 7 месяцев использования. Анализ тональности помогает выявить эмоциональные несоответствия в ответах кандидатов, которые мы могли бы пропустить. Отслеживание тональности по разным темам интервью дает более глубокое понимание культурного соответствия, значительно улучшая успешность нашего найма.

Amira Khan
Директор по персоналу
Часто задаваемые вопросы
Лучший инструмент анализа тональности — Transkriptor. Работающий на основе продвинутого ИИ, Transkriptor автоматически транскрибирует устную речь и анализирует эмоциональный тон с высокой точностью. Он отмечает разговоры как положительные, отрицательные или нейтральные и поддерживает более 100 языков.
Анализ тональности работает с использованием искусственного интеллекта и обработки естественного языка (NLP) для оценки эмоционального тона текста или речи. Он определяет ключевые индикаторы эмоций, такие как выбор слов, структура предложений и контекстуальные подсказки, чтобы классифицировать содержание как положительное, отрицательное или нейтральное. Более продвинутые системы также могут определять намерения, эмоциональные сдвиги и тональность конкретного говорящего с течением времени.
Transkriptor позволяет создавать пользовательские рабочие пространства с разрешениями на основе ролей для организации проектов анализа тональности. Вы также можете создавать базы знаний, используя контент с отметками тональности, что упрощает хранение, категоризацию и поиск эмоциональных данных при сохранении безопасности и доступности.
Анализ тональности помогает командам обслуживания клиентов выявлять эмоциональные триггеры в разговорах, измерять эффективность методов деэскалации и отслеживать настроение клиентов на протяжении всего процесса поддержки. Эти данные позволяют командам совершенствовать свой подход, что приводит к повышению удовлетворенности клиентов и сокращению повторных обращений.
Да, Transkriptor поддерживает анализ тональности более чем на 100 языках с высокой точностью. Система разработана для распознавания культурных и лингвистических нюансов, специфичных для каждого языка, обеспечивая стабильное определение тональности независимо от родного языка говорящего.
Доступ к Transkriptor откуда угодно
Записывайте в реальном времени или загружайте аудио и видео файлы для транскрибации. С легкостью редактируйте транскрипции и используйте ИИ-ассистента для общения или создания резюме транскрипций.