AI搭載の感情分析
TranskriptorのAI駆動型感情分析は、音声録音を詳細な感情インサイトに変換します。高度なAI搭載の文字起こしと感情分析により、音声をテキストに自動変換し、声の感情データを抽出することで、顧客通話、オンラインミーティング、インタビューにおける話者の時間、トーン、感情、意図を正確に検出します。
100以上の言語で文字起こしと感情分析
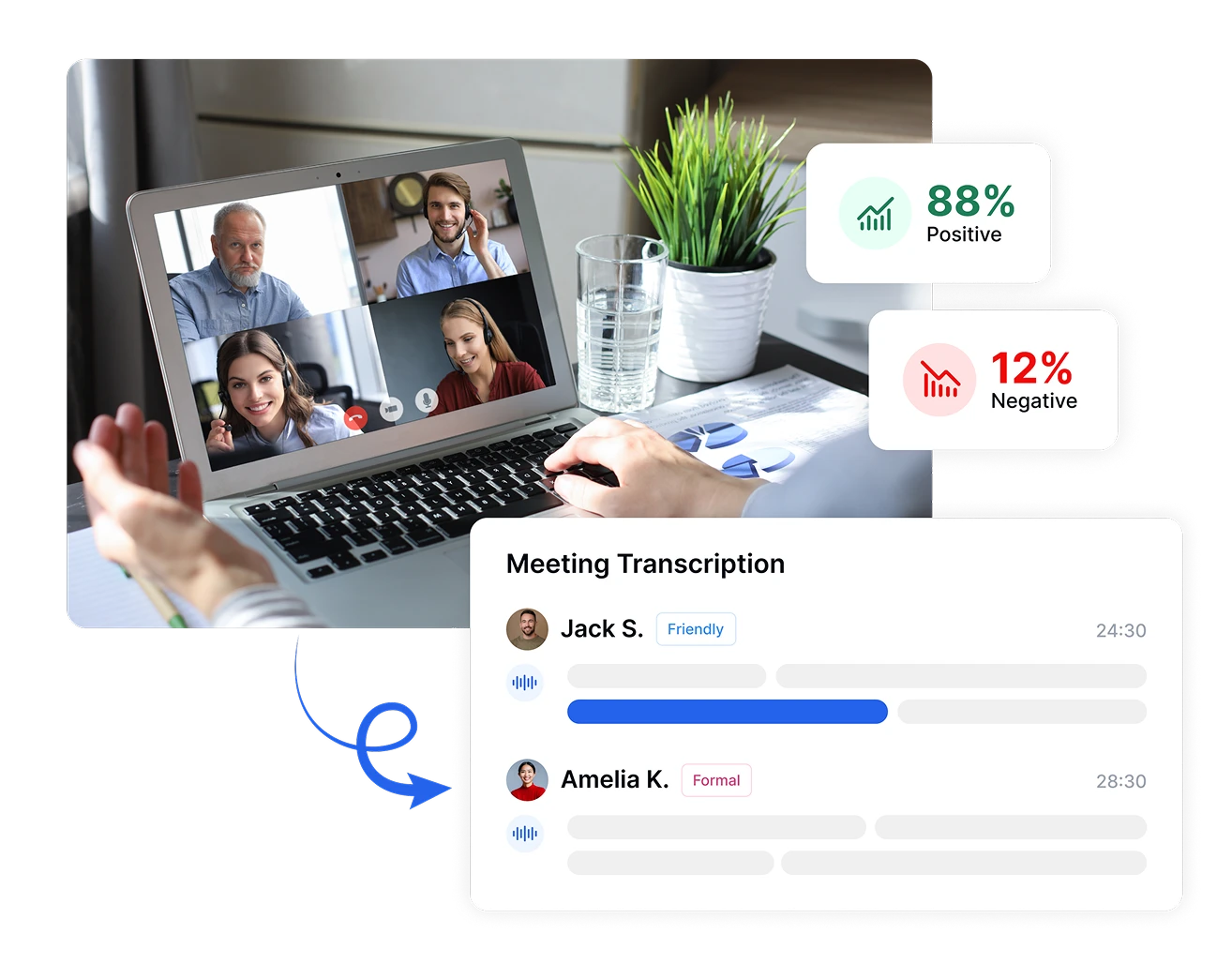
感情分析でデータ駆動型の意思決定を実現
Transkriptorで主観的な感情反応を客観的な指標に変換します。感情の強度を測定し、会話中の感情の変化を追跡し、異なる期間や顧客セグメント間の感情を比較します。これらの精密な測定により、抽象的な感情が具体的なデータポイントに変換され、顧客満足度とビジネス成果を向上させるエビデンスベースの意思決定が可能になります。

100以上の言語で音声感情を分析
Transkriptorの多言語感情分析機能で言語の壁を打ち破ります。100以上の言語で感情のニュアンスを検出し、地域や言語に関係なく顧客の感情を理解できるようにします。この包括的な言語カバレッジにより、国際市場全体で最大99%の高い精度で一貫した感情追跡が保証されます。
すべてのチャネルで感情を捉えて分析
Transkriptorの多様な入力オプションで複数のコミュニケーションチャネルから感情を分析します。アップロードされた音声ファイル、直接録音された会議、Zoom、Microsoft Teams、Google Meetなどの統合プラットフォームから自動的に文字起こしと感情分析を行います。感情分析結果をPDF、Word、TXT、CSV形式でエクスポートするか、チームメンバーとすぐに共有できます。

たった4つの簡単なステップで音声感情分析
- 1ステップ 1
音声をアップロードまたは会議を接続
- 2ステップ 2
Transkriptorが文字起こしと分析を実行
- 3ステップ 3
感情分析の確認
- 4ステップ 4
感情インサイトのエクスポートまたは共有
Transkriptorの感情分析が最も役立つのは誰か

カスタマーサクセスチーム
AIを活用した感情分析により、すべてのサービス対応における顧客満足度の傾向を追跡します。

営業担当者
AI搭載の感情分析を使用して見込み客との通話を最適化し、セールス会話を改善します。

法律専門家
録音された証言、クライアントインタビュー、証人の陳述における感情パターンを分析します。

人事担当者
客観的な感情分析により、面接評価や従業員へのフィードバックセッションを改善します。
オールインワン感情分析ソリューション
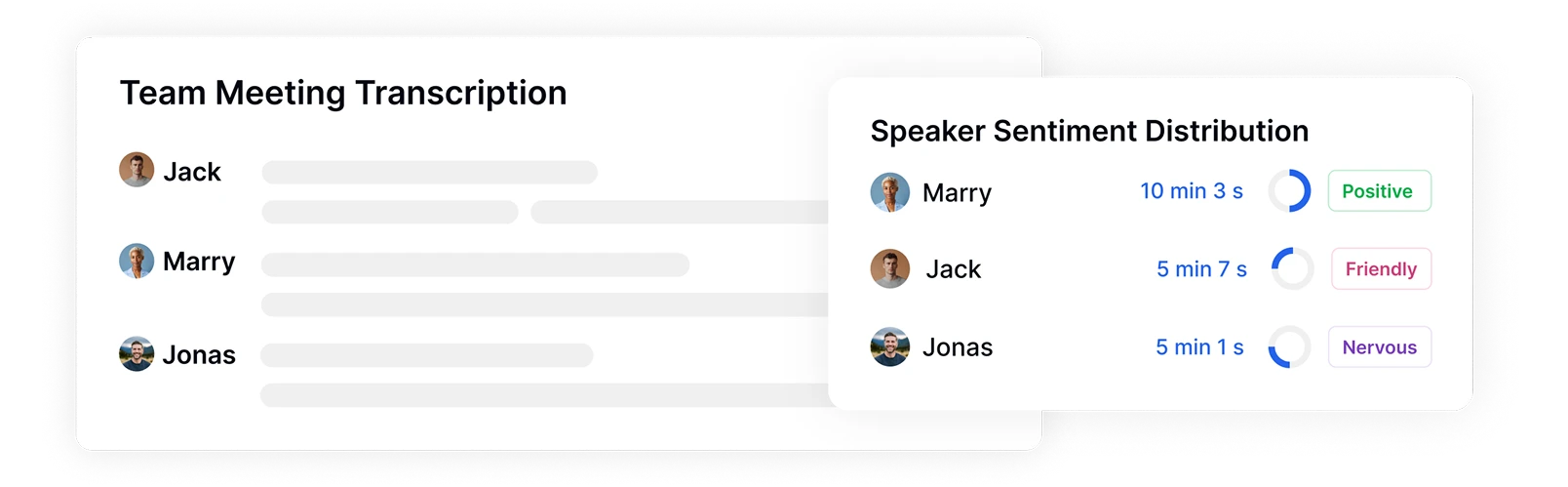
話者を識別し感情分布を追跡
Transkriptorは録音内の異なる話者を自動的に識別してタグ付けし、発話時間と感情パターンを測定します。誰がいつ、どれくらいの時間、どのような感情で話したかを正確に把握し、会議、インタビュー、顧客とのやり取りにおける参加者間の感情ダイナミクスを分析するための重要な文脈を提供します。
話者を識別し感情分布を追跡
Transkriptorは録音内の異なる話者を自動的に識別してタグ付けし、発話時間と感情パターンを測定します。誰がいつ、どれくらいの時間、どのような感情で話したかを正確に把握し、会議、インタビュー、顧客とのやり取りにおける参加者間の感情ダイナミクスを分析するための重要な文脈を提供します。

AI搭載の感情サマリーを生成
TranskriptorのAI技術で長い会話を簡潔な感情サマリーに変換します。これらのサマリーは主要な感情の変化を特定し、全体的な感情トーンを定量化して、記録された会話全体の感情の流れを素早く把握できます。

感情分析でナレッジベースを構築
感情分析された文字起こしを使用してカスタムナレッジベースを作成し、重要な感情的洞察を整理します。感情データを保存、分類、検索して、感情的ベンチマークを確立し、繰り返しパターンを特定し、感情インテリジェンスの包括的なリポジトリを構築します。
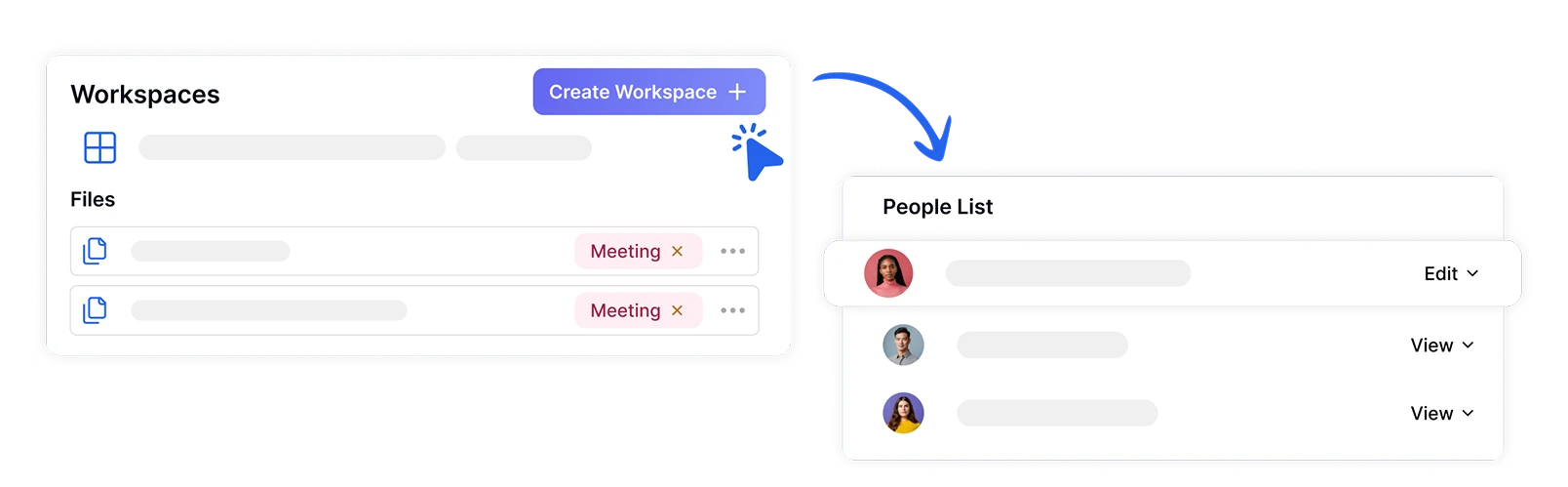
安全なワークスペースでファイルを整理・共有
役割と権限が割り当てられた専用ワークスペースを作成して、チームの感情分析プロジェクトを安全に管理します。機密性の高い感情データへのアクセスを許可されたチームメンバーのみに制限しながら、部門間での感情分析の洞察に関するコラボレーションを促進します。
エンタープライズグレードのセキュリティ
セキュリティとお客様のプライバシーはあらゆる段階で私たちの優先事項です。SOC 2およびGDPR基準に準拠し、お客様の情報が常に保護されるよう保証しています。





お客様の成功事例
感情データを活用して解約率を削減
Transkriptorは、14人のチームが顧客関係を管理する方法を革新しました。オンボーディングやチェックインコールの感情分析により、従来の指標が問題を示す前にリスクのあるアカウントを特定できます。多言語サポートでグローバルな顧客基盤に対応し、カスタムテンプレートによりチーム全体でアプローチを標準化できます。

Kira Johnson
カスタマーサクセスリード
採用ミスを30%削減
Transkriptorは7ヶ月間の使用で面接プロセスを変革しました。感情分析により、見逃しがちな候補者の回答における感情の不一致を特定できます。異なる面接トピックにわたる感情を追跡することで、文化的適合性についてより深い洞察が得られ、採用成功率が大幅に向上しました。

Amira Khan
人事ディレクター
よくある質問
最高の感情分析ツールはTranskriptorです。高度なAIを搭載したTranskriptorは、話された内容を自動的に文字起こしし、高精度で感情的なトーンを分析します。会話をポジティブ、ネガティブ、またはニュートラルとタグ付けし、100以上の言語をサポートしています。
感情分析は、人工知能と自然言語処理(NLP)を使用してテキストや音声の感情的なトーンを評価します。単語の選択、文章構造、文脈的な手がかりなど、感情の重要な指標を識別し、コンテンツをポジティブ、ネガティブ、またはニュートラルに分類します。より高度なシステムでは、意図、感情の変化、時間の経過に伴う話者固有の感情も検出できます。
Transkriptorでは、ロールベースの権限を持つカスタムワークスペースを作成して、感情分析プロジェクトを整理できます。また、感情タグ付けされたコンテンツを使用してナレッジベースを構築することもでき、セキュリティとアクセシビリティを維持しながら、感情データの保存、分類、検索が簡単に行えます。
感情分析は、カスタマーサービスチームが会話における感情的なトリガーを特定し、エスカレーション防止技術の効果を測定し、サポートプロセス全体を通じて顧客の感情を追跡するのに役立ちます。これらの洞察により、チームはアプローチを改善し、顧客満足度の向上とリピートコールの削減につながります。
はい、Transkriptorは100以上の言語で高精度の感情分析をサポートしています。システムは各言語特有の文化的・言語的ニュアンスを認識するように設計されており、話者の母国語に関係なく一貫した感情検出を保証します。
どこでもTranskriptorにアクセス
ライブ録音または音声・動画ファイルをアップロードして文字起こしができます。文字起こしを簡単に編集し、AIアシスタントを使用して文字起こしとチャットしたり要約したりできます。