
Izradite svoj račun i zabilježite ili prenesite datoteku
Stvori svoj Transkriptor račun i započni s besplatnim pristupom transkripciji. Snimi ili prenesi svoj audio/video da bi odmah počeo transkribirati audio u tekst.
Trenutačno transkribiraj sastanke, intervjue, pozive i predavanja u precizne transkripte—započni s besplatnom AI transkripcijom i otključaj vrijedne uvide iz svojih razgovora.
Pretvorite audio u tekst na više od 100 jezika
Radi s
Pretvorite lokalnu video ili audio datoteku u tekst
Prenesi audio ili video datoteku sa svog uređaja i transkribiraj audio u tekst besplatno.
Klikni za prijenos i besplatno transkribiranje
Snimanje zvuka i pretvaranje u tekst
Snimi svoj audio izravno i besplatno transkribiraj audio u tekst.
Povjerenje pojedinaca u


Pretvorite audio u tekst s #1 ocijenjenim Chrome proširenjem za transkripciju. Odmah snimajte svoj zaslon, kameru ili mikrofon i dobijte precizne transkripte govora u tekst izravno iz vašeg preglednika.
Jednostavno pretvori video u tekst besplatno s našim moćnim transkriptorskim sustavom - bez potrebe za konverzijom datoteka. Podržavamo širok raspon formata, uključujući MP3, MP4, WAV i druge. Možeš transkribirati bilo koji sadržaj brzo i bez problema s kompatibilnošću.
Povežite Transkriptor s pohranom u oblaku, CRM-om i drugim aplikacijama putem Zapiera kako biste automatski transkriptirali medijske datoteke i usmjerili svoje precizne transkripte na željene platforme, štedeći vrijeme i održavajući vaš transkriptirani sadržaj savršeno organiziranim.
Stvori svoj Transkriptor račun i započni s besplatnim pristupom transkripciji. Snimi ili prenesi svoj audio/video da bi odmah počeo transkribirati audio u tekst.
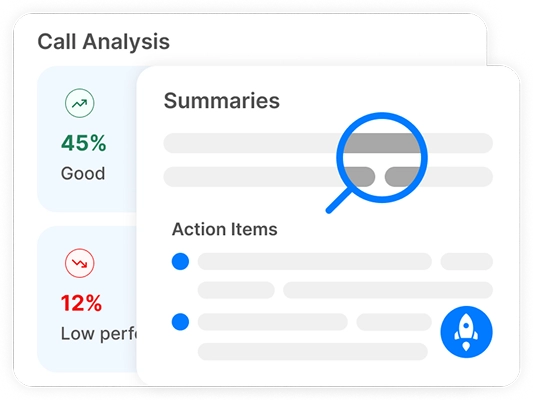
Transkriptor pruža transkripte koji se mogu u potpunosti uređivati, analizu raspoloženja poziva koju pokreće AI, sažetke AI i raščlambu ključnih tema.
Vaše bilješke i audio transkripcije sigurno su pohranjene radi lakšeg pristupa. Organizirajte bilješke sa sastanka i transkripte koji se mogu pretraživati u mapama i radnim prostorima.
Iskoristite našu tehnologiju transkripcije AI za izdvajanje uvida i baza znanja iz više datoteka te postavljajte pitanja ili razgovarajte sa svojim prijepisima glasa u tekst.
Stvori svoj Transkriptor račun i započni s besplatnim pristupom transkripciji. Snimi ili prenesi svoj audio/video da bi odmah počeo transkribirati audio u tekst.

Sigurna, precizna medicinska transkripcija dizajnirana za zdravstvene stručnjake. Pretvorite interakcije s pacijentima u organizirane kliničke zapise trenutačno.

Pretvorite sastanke klijenata u organizirane poslovne transkripte koji se mogu pretraživati. Dobijte trenutne transkribirane uvide, ključne nalaze i analizu transkripcije koju pokreće AI za bolje ishode klijenata.

Fokusirajte se u potpunosti na svoje klijente dok Transkriptor djeluje kao vaš profesionalni prepisivač za terapijske sesije. Automatski dobivajte organizirane bilješke sa sesija, praćenje napretka i sigurnu dokumentaciju.

Pretvorite sastanke klijenata u transkripte koji se mogu pretraživati pomoću pravne tehnologije transkripcije. Pristupite trenutnim zapisima rasprava uz zadržavanje povjerljivosti.

Brza i precizna transkripcija medija za emitiranje i produkciju sadržaja. Pretvorite audio u tekst trenutačno, s podrškom za više formata i jezika.
Pretvorite svoje videozapise u pristupačan sadržaj s brzim uslugama transkripcije i automatskim podnaslovljavanjem na više od 100 jezika.
Postavljajte pitanja, dobivajte sažetke i izvlačite uvide iz vašeg transkribiranog sadržaja trenutačno.
Upravljajte pristupom, dijelite datoteke i surađujte bez poteškoća u namjenskim radnim prostorima.
Dodajte prilagođene oznake bilo kojoj od vaših datoteka. Brzo pronađite važne trenutke i organizirajte sadržaj na svoj način.
Analizirajte ton i sentiment transkribiranim sastancima. Savršeno za korisničku podršku i komunikaciju unutar tima.
Pratite raspodjelu vremena govora i razine sudjelovanja u razgovorima.
Otključaj snagu napredne AI transkripcije za svaki aspekt svog rada. Isprobaj besplatno - povećaj produktivnost, pojednostavi radni proces!
Pretvorite govor u točne transkripte u nekoliko sekundi. Profesionalna tehnologija transkripcije audio i video sadržaja, tako da se možete usredotočiti na uvide, a ne na bilježenje.
Snimite svaki trenutak s jasnoćom. Jednostavno snimajte i transkribirajte zaslon za vodiče, prezentacije i još mnogo toga – pregledavajte i pretražujte transkribirani sadržaj kad god vam zatreba.
Nikada više ne propustite nijedan detalj. Automatizirana transkripcija, sažeci sastanaka AI i akcijske stavke sa sastanaka, pretvarajući razgovore u transkripte koji se mogu pretraživati uz povećanje produktivnosti.
Oživite tekst prirodnim glasovima. Pretvorite pisani tekst u realistične izgovorene riječi, poboljšavajući pristupačnost i angažman.
Sadržaj bez napora, savršeno napisan. Prepišite svoje ideje u visokokvalitetan, privlačan sadržaj prilagođen vašoj publici uz minimalan unos.
Transkribirano znanje vašeg tima udaljeno je samo jedan klik. Centralizirana AI baza znanja koja neprimjetno organizira, dohvaća i pojednostavljuje transkribirane razgovore.
Transkriptor daje prioritet sigurnosti i privatnosti na svim razinama. Naša platforma za transkripciju poslovne razine u skladu je sa standardima SOC 2, GDPR, ISO 27001 i SSL kako bi se osiguralo da su vaši audio i video podaci u potpunosti zaštićeni i sigurno transkribirani.




Transkriptorov moćni AI zapisničar generira online transkripte u nekoliko sekundi, dok većini usluga treba više od 10 minuta.
Dobijte do 99% točnosti pri transkripciji vaših audio datoteka s Transkriptorom. Jednostavno transkribirajte ili prevedite audio sadržaj na više od 100 jezika.
Dobijte vrijednost za svoj novac s Transkriptorovim punim rasponom produktivnih značajki i intuitivnih rješenja po pristupačnoj cijeni.
Transkripcija je proces pretvaranja govornog jezika iz audio ili video zapisa u pisani tekst. Široko se koristi za sastanke, intervjue, predavanja, podcaste i medijske sadržaje. Transkripcija se može obaviti ručno od strane ljudskih transkriptora ili automatski pomoću AI softvera za transkripciju.
Transkripcija funkcionira pretvaranjem izgovorenih riječi iz audio ili video zapisa u pisani tekst. Datoteku prenosite u alat kao što je Transkriptor, koji koristi AI za otkrivanje govora, identifikaciju govornika i generiranje transkripta s vremenskom oznakom. Zatim možete pregledati i urediti tekst te ga izvesti u formatima kao što su TXT, DOCX ili titlovi (SRT/VTT).
Prednosti transkripcije uključuju poboljšanu pristupačnost, bolju pretraživost sadržaja i povećanu produktivnost. Ona pretvara govoreni sadržaj u pisani tekst koji je lako čitati i prenamjenjivati. Transkripcija također podržava SEO stvaranjem sadržaja koji se može indeksirati. AI alati za transkripciju poput Transkriptora automatiziraju proces, štede vrijeme i resurse.
Na točnost transkripcije utječe nekoliko čimbenika, uključujući kvalitetu zvuka, pozadinsku buku, jasnoću zvučnika, preklapanje dijaloga, naglaske i broj govornika. Loše snimljeni zvuk ili jaki naglasci mogu smanjiti učinkovitost AI alata za transkripciju. Visokokvalitetni mikrofoni, jasan govor i minimalni prekidi poboljšavaju rezultate.
Da, moderni alati za transkripciju kao što je Transkriptor mogu obraditi više govornika pomoću tehnologije dijarizacije zvučnika. Ova značajka identificira i označava svakog govornika u transkriptu, što olakšava praćenje razgovora na sastancima, intervjuima ili grupnim raspravama.
Najbolji softver za transkripciju je Transkriptor. Nudi vrlo preciznu AI transkripciju s točnošću do 99%. Transkriptor podržava više od 100 jezika, omogućuje korisnicima prijenos audio ili video datoteka u različitim formatima i uključuje značajke poput identifikacije govornika, generiranja podnaslova i ugrađenog uređivača transkripta. Drugi popularni alati za transkripciju uključuju Otter.ai i Fireflies.ai, koji također nude AI usluge transkripcije. Međutim, Transkriptor je preferiran zbog svoje šire pokrivenosti jezika, pristupačnih cijena i pojednostavljenih značajki uređivanja koje podržavaju i povremene korisnike i profesionalce.
Možete provesti analizu raspoloženja za razgovore pomoću alata pokretanih AI-om kao što je Transkriptor. Transkriptor-ov bot za sastanke može se izravno pridružiti vašim mrežnim sastancima ili analizirati učitane snimke. Nakon transkripcije automatski procjenjuje emocionalni ton razgovora – klasificirajući segmente kao pozitivne, neutralne ili negativne.
Najbolji pretvarač zvuka u tekst je Transkriptor. Koristi naprednu umjetnu inteligenciju za precizno pretvaranje govornog zvuka u pisani tekst u samo nekoliko sekundi. Transkriptor podržava popularne audio formate kao što su MP3, WAV i M4A, te radi na više od 100 jezika.
Najbolji besplatni alat za transkripciju je Transkriptor. Pruža vrlo precizne i AI-pokretane usluge pretvaranja govora u tekst, čak i u besplatnom planu. S Transkriptorovom besplatnom opcijom transkripcije, možete transkribirati do 30 minuta zvuka dnevno.













