การวิเคราะห์ความรู้สึกด้วย AI
การวิเคราะห์ความรู้สึกด้วย AI ของ Transkriptor เปลี่ยนการบันทึกเสียงของคุณให้เป็นข้อมูลเชิงลึกทางอารมณ์ที่ละเอียด ตรวจจับเวลาพูด โทนเสียง อารมณ์ และเจตนาของผู้พูดในการโทรหาลูกค้า การประชุมออนไลน์ และการสัมภาษณ์ได้อย่างแม่นยำ โดยแปลงเสียงพูดเป็นข้อความและดึงข้อมูลความรู้สึกจากเสียงโดยอัตโนมัติด้วยการถอดเสียงขั้นสูงและการวิเคราะห์ความรู้สึกด้วย AI
ถอดเสียงและวิเคราะห์ความรู้สึกในกว่า 100 ภาษา
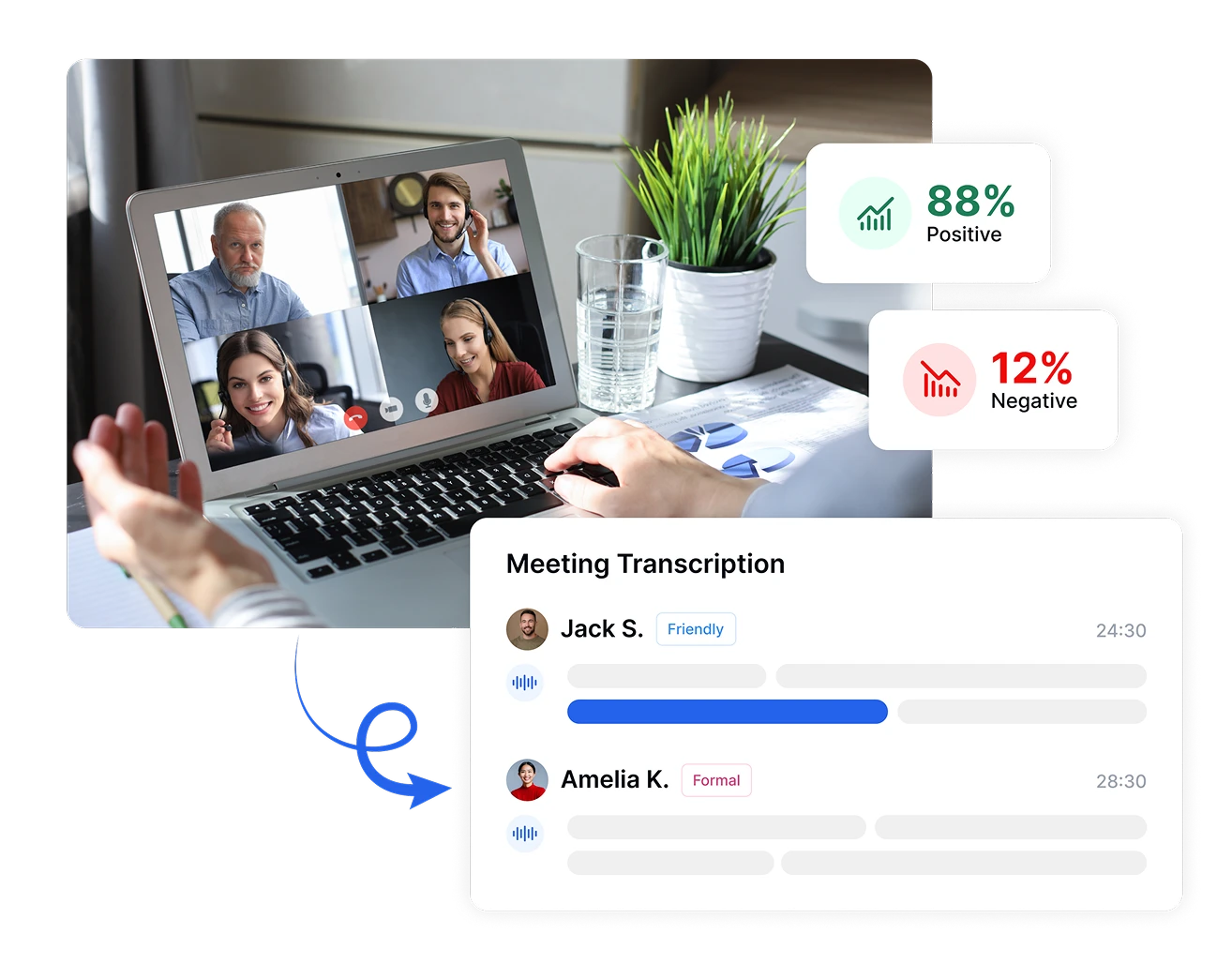
ตัดสินใจด้วยข้อมูลด้วยการวิเคราะห์ความรู้สึก
แปลงการตอบสนองทางอารมณ์เชิงอัตวิสัยให้เป็นตัวชี้วัดเชิงวัตถุวิสัยด้วย Transkriptor วัดความเข้มข้นของความรู้สึก ติดตามการเปลี่ยนแปลงทางอารมณ์ระหว่างการสนทนา และเปรียบเทียบความรู้สึกในช่วงเวลาหรือกลุ่มลูกค้าที่แตกต่างกัน การวัดที่แม่นยำเหล่านี้เปลี่ยนความรู้สึกนามธรรมให้เป็นข้อมูลที่เป็นรูปธรรม ช่วยให้ตัดสินใจบนพื้นฐานของหลักฐานที่ช่วยปรับปรุงความพึงพอใจของลูกค้าและผลลัพธ์ทางธุรกิจ

วิเคราะห์ความรู้สึกจากเสียงในกว่า 100 ภาษา
ทลายอุปสรรคทางภาษาด้วยความสามารถในการวิเคราะห์ความรู้สึกหลายภาษาของ Transkriptor ตรวจจับความละเอียดอ่อนทางอารมณ์ในกว่า 100 ภาษา ช่วยให้ทีมงานทั่วโลกเข้าใจความรู้สึกของลูกค้าโดยไม่คำนึงถึงภูมิภาคหรือภาษา การครอบคลุมภาษาที่ครบถ้วนนี้ช่วยให้มั่นใจได้ว่าการติดตามความรู้สึกในตลาดระหว่างประเทศมีความสม่ำเสมอด้วยอัตราความแม่นยำสูงถึง 99%
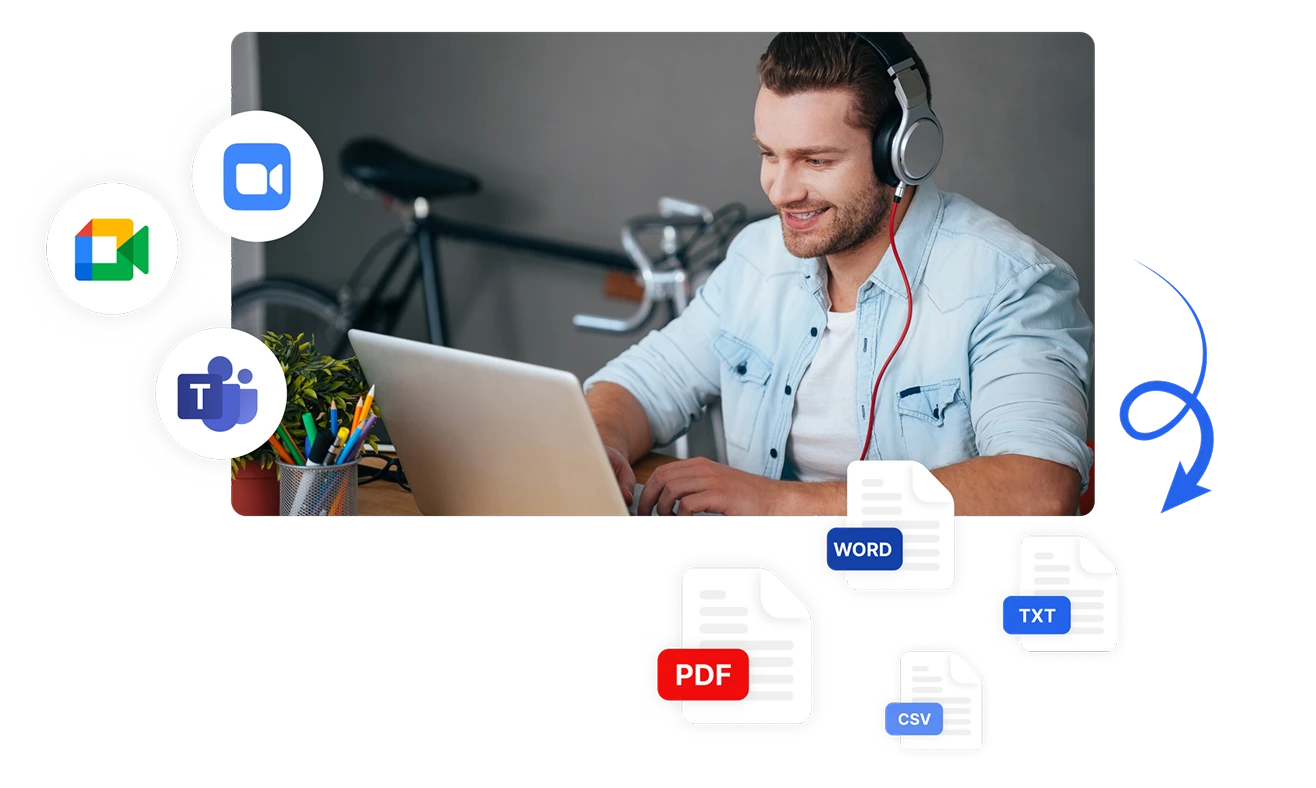
จับและวิเคราะห์ความรู้สึกในทุกช่องทาง
วิเคราะห์ความรู้สึกจากหลายช่องทางการสื่อสารด้วยตัวเลือกการป้อนข้อมูลที่หลากหลายของ Transkriptor ถอดเสียงและวิเคราะห์ความรู้สึกโดยอัตโนมัติจากไฟล์เสียงที่อัปโหลด การประชุมที่บันทึกโดยตรง หรือแพลตฟอร์มที่บูรณาการเช่น Zoom, Microsoft Teams และ Google Meet ส่งออกผลการวิเคราะห์ความรู้สึกของคุณในรูปแบบ PDF, Word, TXT, CSV หรือแชร์กับสมาชิกในทีมได้ทันที

วิเคราะห์ความรู้สึกจากเสียงใน 4 ขั้นตอนง่ายๆ
- 1ขั้นตอน 1
อัปโหลดไฟล์เสียงหรือเชื่อมต่อการประชุมของคุณ
- 2ขั้นตอน 2
Transkriptor ถอดความและวิเคราะห์
- 3ขั้นตอน 3
ตรวจสอบการวิเคราะห์ความรู้สึก
- 4ขั้นตอน 4
ส่งออกหรือแชร์ข้อมูลเชิงลึกด้านความรู้สึก
ใครได้ประโยชน์มากที่สุดจากการวิเคราะห์ความรู้สึกของ Transkriptor

ทีมดูแลลูกค้า
ติดตามแนวโน้มความพึงพอใจของลูกค้าในทุกการมีปฏิสัมพันธ์ด้านบริการด้วยการวิเคราะห์ความรู้สึกที่ขับเคลื่อนด้วย AI

นักขายมืออาชีพ
ปรับการสนทนาการขายให้เหมาะสมด้วยการวิเคราะห์ความรู้สึกของการโทรหาลูกค้าที่มีศักยภาพด้วย AI

นักกฎหมายมืออาชีพ
วิเคราะห์รูปแบบความรู้สึกในการบันทึกคำให้การ การสัมภาษณ์ลูกความ และคำให้การของพยาน

ผู้เชี่ยวชาญด้านทรัพยากรบุคคล
ปรับปรุงการประเมินการสัมภาษณ์และการให้ข้อมูลย้อนกลับแก่พนักงานด้วยการวิเคราะห์ความรู้สึกที่เป็นกลาง
โซลูชันการวิเคราะห์ความรู้สึกแบบครบวงจร
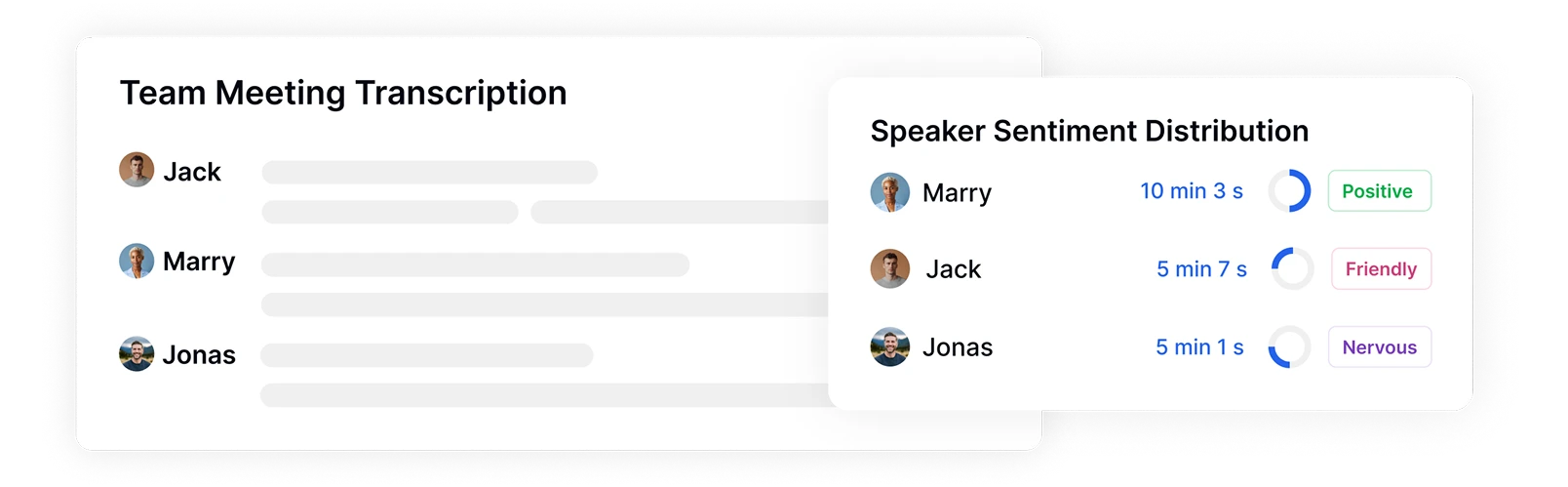
ระบุผู้พูดและติดตามการกระจายความรู้สึก
Transkriptor ระบุและติดแท็กผู้พูดที่แตกต่างกันในการบันทึกของคุณโดยอัตโนมัติ พร้อมวัดเวลาการพูดและรูปแบบอารมณ์ ดูได้อย่างชัดเจนว่าใครพูดเมื่อไหร่ นานแค่ไหน และด้วยความรู้สึกอย่างไร ให้บริบทสำคัญสำหรับการวิเคราะห์พลวัตทางอารมณ์ระหว่างผู้เข้าร่วมในการประชุม การสัมภาษณ์ หรือการมีปฏิสัมพันธ์กับลูกค้า
ระบุผู้พูดและติดตามการกระจายความรู้สึก
Transkriptor ระบุและติดแท็กผู้พูดที่แตกต่างกันในการบันทึกของคุณโดยอัตโนมัติ พร้อมวัดเวลาการพูดและรูปแบบอารมณ์ ดูได้อย่างชัดเจนว่าใครพูดเมื่อไหร่ นานแค่ไหน และด้วยความรู้สึกอย่างไร ให้บริบทสำคัญสำหรับการวิเคราะห์พลวัตทางอารมณ์ระหว่างผู้เข้าร่วมในการประชุม การสัมภาษณ์ หรือการมีปฏิสัมพันธ์กับลูกค้า

สร้างสรุปความรู้สึกด้วย AI
แปลงการสนทนาที่ยาวเป็นสรุปความรู้สึกที่กระชับด้วยเทคโนโลยี AI ของ Transkriptor สรุปเหล่านี้ระบุการเปลี่ยนแปลงความรู้สึกที่สำคัญ และวัดโทนอารมณ์โดยรวม ให้ภาพรวมอย่างรวดเร็วของการเดินทางทางอารมณ์ตลอดการสนทนาที่บันทึกไว้

สร้างฐานความรู้ด้วยการวิเคราะห์ความรู้สึก
จัดระเบียบข้อมูลเชิงลึกทางอารมณ์ที่สำคัญโดยการสร้างฐานความรู้ที่กำหนดเองโดยใช้การถอดเสียงที่วิเคราะห์ความรู้สึก จัดเก็บ จัดหมวดหมู่ และค้นหาข้อมูลความรู้สึกเพื่อสร้างมาตรฐานทางอารมณ์ ระบุรูปแบบที่เกิดซ้ำ และสร้างคลังข้อมูลความฉลาดทางอารมณ์ที่ครอบคลุม
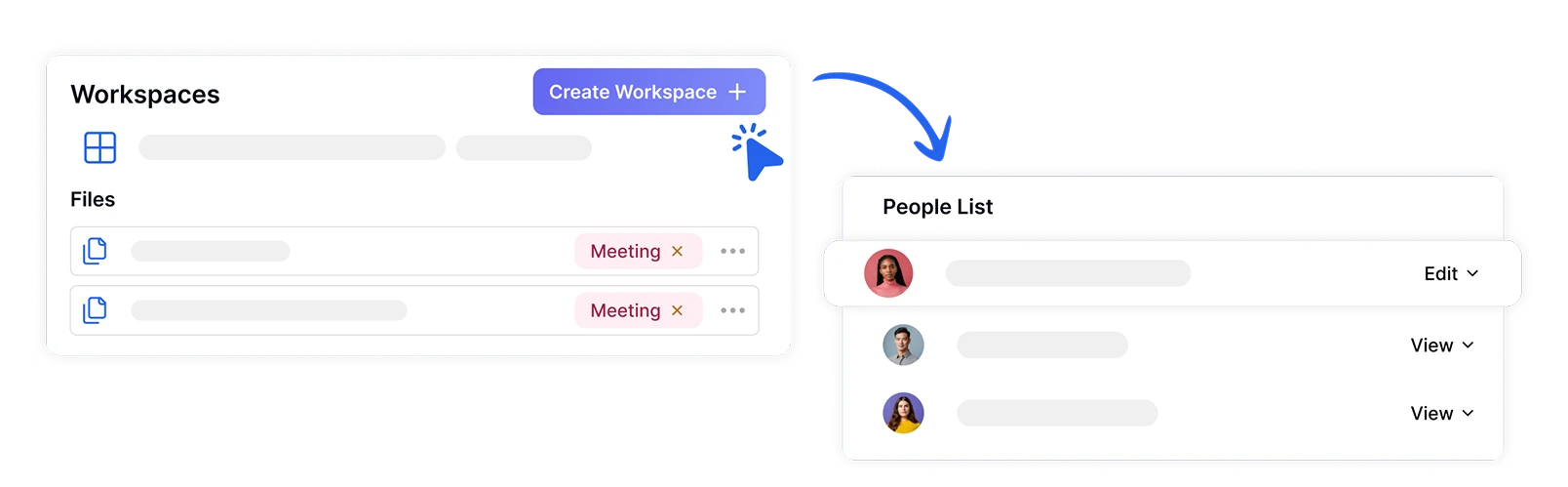
จัดระเบียบและแชร์ไฟล์ในพื้นที่ทำงานที่ปลอดภัย
จัดการโครงการวิเคราะห์ความรู้สึกของทีมอย่างปลอดภัยโดยการสร้างพื้นที่ทำงานเฉพาะที่มีการกำหนดบทบาทและสิทธิ์ ทำให้มั่นใจว่าข้อมูลอารมณ์ที่ละเอียดอ่อนสามารถเข้าถึงได้เฉพาะสมาชิกทีมที่ได้รับอนุญาตเท่านั้น ในขณะที่อำนวยความสะดวกในการทำงานร่วมกันเกี่ยวกับข้อมูลเชิงลึกด้านความรู้สึกระหว่างแผนกต่างๆ
ความปลอดภัยระดับองค์กร
ความปลอดภัยและความเป็นส่วนตัวของลูกค้าเป็นสิ่งสำคัญในทุกขั้นตอนของเรา เราปฏิบัติตามมาตรฐาน SOC 2 และ GDPR และทำให้มั่นใจว่าข้อมูลของคุณได้รับการปกป้องตลอดเวลา





เรื่องราวความสำเร็จของลูกค้า
ลดการสูญเสียลูกค้าด้วยการใช้ข้อมูลความรู้สึก
Transkriptor ได้ปฏิวัติวิธีที่ทีมงาน 14 คนของเราจัดการความสัมพันธ์กับลูกค้า ด้วยการวิเคราะห์ความรู้สึกในการโทรเพื่อเริ่มต้นใช้งานและติดตามผล เราสามารถระบุบัญชีที่มีความเสี่ยงก่อนที่ตัวชี้วัดแบบดั้งเดิมจะแสดงปัญหา การรองรับหลายภาษาช่วยจัดการฐานลูกค้าทั่วโลกของเรา และเทมเพลตที่กำหนดเองช่วยให้มาตรฐานวิธีการของเราทั่วทั้งทีม

Kira Johnson
หัวหน้าฝ่ายความสำเร็จของลูกค้า
ลดการจ้างงานที่ไม่เหมาะสมลง 30%
Transkriptor ได้เปลี่ยนแปลงกระบวนการสัมภาษณ์ของเราตลอด 7 เดือนที่ใช้งาน การวิเคราะห์ความรู้สึกช่วยระบุความไม่สอดคล้องทางอารมณ์ในการตอบของผู้สมัครที่เราอาจพลาดไป การติดตามความรู้สึกในหัวข้อการสัมภาษณ์ที่แตกต่างกันให้ข้อมูลเชิงลึกที่ลึกซึ้งเกี่ยวกับความเหมาะสมทางวัฒนธรรม ซึ่งปรับปรุงอัตราความสำเร็จในการจ้างงานของเราอย่างมีนัยสำคัญ

Amira Khan
ผู้อำนวยการฝ่ายทรัพยากรบุคคล
คำถามที่พบบ่อย
เครื่องมือวิเคราะห์ความรู้สึกที่ดีที่สุดคือ Transkriptor ขับเคลื่อนด้วย AI ขั้นสูง Transkriptor ถอดเสียงพูดโดยอัตโนมัติและวิเคราะห์โทนอารมณ์ด้วยความแม่นยำสูง ระบบจะติดแท็กการสนทนาเป็นเชิงบวก เชิงลบ หรือเป็นกลาง และรองรับมากกว่า 100 ภาษา
การวิเคราะห์ความรู้สึกทำงานโดยใช้ปัญญาประดิษฐ์และการประมวลผลภาษาธรรมชาติ (NLP) เพื่อประเมินโทนอารมณ์ของข้อความหรือคำพูด ระบบจะระบุตัวบ่งชี้สำคัญของอารมณ์ เช่น การเลือกใช้คำ โครงสร้างประโยค และบริบทแวดล้อม เพื่อจำแนกเนื้อหาเป็นเชิงบวก เชิงลบ หรือเป็นกลาง ระบบที่ซับซ้อนกว่ายังสามารถตรวจจับเจตนา การเปลี่ยนแปลงทางอารมณ์ และความรู้สึกเฉพาะของผู้พูดตลอดช่วงเวลาได้
Transkriptor ช่วยให้คุณสร้างพื้นที่ทำงานแบบกำหนดเองพร้อมสิทธิ์การเข้าถึงตามบทบาทสำหรับการจัดระเบียบโครงการวิเคราะห์ความรู้สึก คุณยังสามารถสร้างฐานความรู้โดยใช้เนื้อหาที่ติดแท็กความรู้สึก ทำให้ง่ายต่อการจัดเก็บ จัดหมวดหมู่ และค้นหาข้อมูลทางอารมณ์ ในขณะที่ยังคงรักษาความปลอดภัยและการเข้าถึงได้
การวิเคราะห์ความรู้สึกช่วยให้ทีมบริการลูกค้าระบุตัวกระตุ้นทางอารมณ์ในการสนทนา วัดประสิทธิภาพของเทคนิคการลดความตึงเครียด และติดตามความรู้สึกของลูกค้าตลอดกระบวนการให้บริการ ข้อมูลเชิงลึกเหล่านี้ช่วยให้ทีมปรับปรุงวิธีการทำงาน นำไปสู่ความพึงพอใจของลูกค้าที่เพิ่มขึ้นและลดการโทรซ้ำ
ได้ Transkriptor รองรับการวิเคราะห์ความรู้สึกในกว่า 100 ภาษาด้วยความแม่นยำสูง ระบบได้รับการออกแบบให้รับรู้ความแตกต่างทางวัฒนธรรมและภาษาเฉพาะของแต่ละภาษา ทำให้มั่นใจได้ว่าการตรวจจับความรู้สึกมีความสม่ำเสมอโดยไม่คำนึงถึงภาษาแม่ของผู้พูด
เข้าถึง Transkriptor ได้ทุกที่
บันทึกสดหรืออัปโหลดไฟล์เสียงและวิดีโอเพื่อถอดความ แก้ไขการถอดความได้อย่างง่ายดาย และใช้ผู้ช่วย AI เพื่อแชทหรือสรุปการถอดความ