
Opprett kontoen din og registrer eller last opp en fil
Opprett din Transkriptor-konto og kom i gang med gratis transkripsjon. Ta opp eller last opp lyd/video for å begynne å transkribere lyd til tekst øyeblikkelig.
Transkribere lyd til tekst fra møter, intervjuer, samtaler og forelesninger til presise transkripsjoner—start med gratis AI-transkripsjon og lås opp verdifull innsikt fra samtalene dine.
Konverter lyd til tekst på over 100 språk
Fungerer med
Konverter lokal video- eller lydfil til tekst
Last opp en lyd- eller videofil fra enheten din og transkribere lyd til tekst gratis.
Klikk for å laste opp og transkribere gratis
Ta opp lyd og konverter til tekst
Ta opp lyden din direkte og konverter lyd til tekst gratis.
Anerkjent av enkeltpersoner på


Konverter lyd til tekst med den #1 rangerte transkripsjon Chrome-utvidelsen. Ta øyeblikkelig opp skjermen, kameraet eller mikrofonen din og få nøyaktige tale-til-tekst-transkripsjoner direkte fra nettleseren.
Konverter enkelt video til tekst gratis med vår kraftige transkripsjonsmotor - ingen filkonvertering nødvendig. Vi støtter et bredt utvalg av formater, inkludert MP3, MP4, WAV og mer. Du kan transkribere lyd til tekst raskt og uten kompatibilitetsproblemer.
Koble Transkriptor med skylagring, CRM og andre apper gjennom Zapier for automatisk å transkribere mediefiler og rute dine nøyaktige transkripsjoner til dine foretrukne plattformer, noe som sparer tid og holder ditt transkriberte innhold perfekt organisert.
Opprett din Transkriptor-konto og kom i gang med gratis transkripsjon. Ta opp eller last opp lyd/video for å begynne å transkribere lyd til tekst øyeblikkelig.
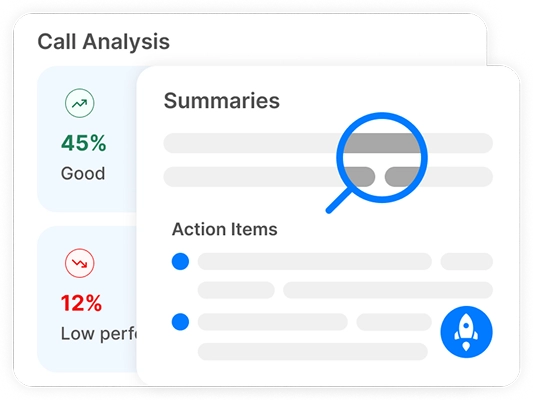
Transkriptor gir fullt redigerbare transkripsjoner, AI-drevet samtalesentimentanalyse, AI-sammendrag og oversikt over viktige emner.
Notatene og lydtranskripsjonene dine lagres sikkert for enkel tilgang. Organiser møtenotater og søkbare utskrifter i mapper og arbeidsområder.
Utnytt vår AI-transkripsjonsteknologi for å trekke ut innsikt og kunnskapsbaser fra flere filer, og still spørsmål eller snakk med tale-til-tekst-transkripsjonene dine.
Opprett din Transkriptor-konto og kom i gang med gratis transkripsjon. Ta opp eller last opp lyd/video for å begynne å transkribere lyd til tekst øyeblikkelig.

Sikker, nøyaktig medisinsk transkripsjon utviklet for helsepersonell. Transformer pasientsamtaler til organiserte kliniske transkripsjoner øyeblikkelig.

Forvandle kundemøter til organiserte, søkbare forretningsutskrifter. Få umiddelbar transkribert innsikt, nøkkelfunn og AI-drevet transkripsjonsanalyse for bedre kunderesultater.

Fokuser helt på klientene dine mens Transkriptor fungerer som din profesjonelle transkribent for terapitimer. Få organiserte samtalenotater, fremdriftssporing og sikker dokumentasjon automatisk.

Gjør kundemøter om til søkbare transkripsjoner med juridisk transkripsjonsteknologi. Få tilgang til umiddelbare oppføringer av diskusjoner samtidig som du opprettholder konfidensialiteten.

Rask og nøyaktig medietranskribering for kringkasting og innholdsproduksjon. Konverter lyd til tekst umiddelbart, med støtte for flere formater og språk.
Konverter dine videoer til tilgængeligt indhold med hurtige transkriberingstjenester og automatisk undertekstning på over 100 sprog.
Stil spørgsmål, få sammendrag og udtræk indsigter fra dit transkriberede indhold øjeblikkeligt.
Administrer adgang, del filer og samarbejd problemfrit i dedikerede arbejdsområder.
Tilføj brugerdefinerede tags til alle dine filer. Find vigtige øjeblikke hurtigt og organiser indhold på din måde.
Analyser tonen og stemningen i transkriberede møder. Perfekt til kundeservice og teamkommunikation.
Spor fordeling af taletid og deltagelsesniveauer i samtaler.
Lås opp kraften i avansert AI-transkripsjon for alle aspekter av arbeidet ditt. Prøv det gratis - øk produktiviteten, forenkle arbeidsflyten!
Gjør tale om til nøyaktige transkripsjoner på sekunder. Profesjonell transkripsjonsteknologi for lyd- og videoinnhold, slik at du kan fokusere på innsikt, ikke notater.
Fang hvert øyeblikk med klarhet. Ta opp og transkriber skjermen enkelt for opplæringer, presentasjoner og mer – se gjennom og søk i transkribert innhold når du trenger det.
Gå aldri glipp av en detalj igjen. Automatisert transkripsjon, AI-møtesammendrag og handlingselementer fra møtene dine, som forvandler samtaler til søkbare transkripsjoner samtidig som produktiviteten økes.
Gi liv til tekst med naturlige stemmer. Konverter skrevet tekst til realistiske talte ord, og forbedre tilgjengeligheten og engasjementet.
Uanstrengt innhold, perfekt skrevet. Transkriber ideene dine til engasjerende innhold av høy kvalitet skreddersydd for publikum med minimale innspill.
Teamets transkriberte kunnskap er bare et klikk unna. Sentralisert AI-kunnskapsbase som organiserer, henter og effektiviserer transkriberte samtaler sømløst.
Transkriptor prioriterer sikkerhet og personvern på alle nivåer. Vår transkripsjonsplattform i bedriftsklasse overholder SOC 2, GDPR, ISO 27001 og SSL-standarder for å sikre at lyd- og videodataene dine er fullstendig beskyttet og sikkert transkribert.




Transkriptors kraftige AI-notatskriver genererer online transkripsjoner på sekunder, mens de fleste tjenester bruker mer enn 10 minutter.
Få opptil 99% nøyaktighet når du transkriberer lydfiler med Transkriptor. Transkriber eller oversett lydinnhold på over 100 språk enkelt.
Få valuta for pengene med Transkriptors komplette utvalg av produktivitetsfunksjoner og intuitive løsninger til en rimelig pris.
Transkripsjon er prosessen med å konvertere talespråk fra lyd- eller videoopptak til skrevet tekst. Det brukes i stor grad for møter, intervjuer, forelesninger, podcaster og medieinnhold. Transkripsjon kan gjøres manuelt av menneskelige transkribenter eller automatisk ved hjelp av AI-transkripsjonsprogramvare.
Transkripsjon fungerer ved å konvertere talte ord fra lyd eller video til skrevet tekst. Du laster opp en fil til et verktøy som Transkriptor, som bruker AI til å oppdage tale, identifisere talere og generere en tidsstemplet transkripsjon. Du kan deretter se gjennom og redigere teksten, og eksportere den i formater som TXT, DOCX eller undertekster (SRT/VTT).
Fordelene med transkripsjon inkluderer forbedret tilgjengelighet, bedre søkbarhet i innhold og økt produktivitet. Det gjør om muntlig innhold til skriftlig tekst som er enkel å lese og gjenbruke. Transkripsjon støtter også SEO ved å skape indekserbart innhold. AI-transkripsjonsverktøy som Transkriptor automatiserer prosessen, noe som sparer tid og ressurser.
Transkripsjonsnøyaktigheten påvirkes av flere faktorer, inkludert lydkvalitet, bakgrunnsstøy, høyttalerklarhet, overlappende dialog, aksenter og antall talere. Dårlig innspilt lyd eller sterke aksenter kan redusere effektiviteten til AI-transkripsjonsverktøy. Mikrofoner av høy kvalitet, tydelig tale og minimale avbrudd forbedrer resultatene.
Ja, moderne transkripsjonsverktøy som Transkriptor kan håndtere flere høyttalere ved å bruke høyttalerdiariseringsteknologi. Denne funksjonen identifiserer og merker hver taler i utskriften, noe som gjør det enklere å følge samtaler i møter, intervjuer eller gruppediskusjoner.
Den beste transkripsjons-programvaren er Transkriptor. Den tilbyr svært nøyaktig AI-drevet transkripsjon med opptil 99% nøyaktighet. Transkriptor støtter over 100 språk, lar brukere laste opp lyd- eller videofiler i ulike formater, og inkluderer funksjoner som taleidentifikasjon, undertekstgenerering og en innebygd transkripsjonsredigerer. Andre populære transkripsjonsverktøy inkluderer Otter.ai og Fireflies.ai, som også tilbyr AI-baserte transkripsjonstjenester. Transkriptor foretrekkes imidlertid for sin bredere språkdekning, rimelige priser og strømlinjeformede redigeringsfunksjoner som støtter både tilfeldige brukere og profesjonelle.
Du kan utføre sentimentanalyse for samtaler ved hjelp av AI-drevne verktøy som Transkriptor. Transkriptor sin møtebot kan bli med i nettmøtene dine direkte eller analysere opplastede opptak. Etter transkripsjon evaluerer den automatisk den emosjonelle tonen i samtalen – og klassifiserer segmenter som positive, nøytrale eller negative.
Den beste lyd-til-tekst-konverteren er Transkriptor. Den bruker avansert AI for å nøyaktig konvertere talt lyd til skrevet tekst på bare sekunder. Transkriptor støtter populære lydformater som MP3, WAV og M4A, og fungerer på over 100 språk.
Det beste gratis transkripsjonsverktøyet er Transkriptor. Det tilbyr svært nøyaktige og AI-drevne tale-til-tekst-tjenester, selv i gratisversjonen. Med Transkriptors gratis transkripsjonsalternativ kan du transkribere opptil 30 minutter med lyd per dag.













