
Opret din konto og optag eller upload en fil
Opret din Transkriptor-konto og kom i gang med gratis transskriptionsadgang. Optag eller upload din lyd/video for at begynde at transskribere øjeblikkeligt.
Transskribér møder, interviews, opkald og forelæsninger til præcise udskrifter øjeblikkeligt—start med gratis AI-transskription og lås op for værdifulde indsigter fra dine samtaler.
Konverter lyd til tekst på over 100 sprog
Arbejder med
Konverter lokal video eller lydfil til tekst
Upload en lyd- eller videofil fra din lokale enhed og transskribér gratis.
Klik for at uploade og transskribere gratis
Optag lyd og konverter til tekst
Optag din lyd direkte og transskribér lyd til tekst gratis.
Betroet af enkeltpersoner på


Konverter lyd til tekst med den #1 bedømte transskriptions Chrome Extension. Optag øjeblikkeligt din skærm, kamera eller mikrofon og få nøjagtige tale-til-tekst transskriptioner direkte fra din browser.
Konvertér nemt video til tekst gratis med vores kraftfulde transskriptionsmotor - ingen filkonvertering nødvendig. Vi understøtter en bred vifte af formater, herunder MP3, MP4, WAV og mere. Du kan transskribere ethvert indhold hurtigt og uden kompatibilitetsproblemer.
Forbind Transkriptor med cloud-lagring, CRM og andre apps gennem Zapier for automatisk at transskribere mediefiler og dirigere dine præcise transskriptioner til dine foretrukne platforme, hvilket sparer tid og holder dit transskriberede indhold perfekt organiseret.
Opret din Transkriptor-konto og kom i gang med gratis transskriptionsadgang. Optag eller upload din lyd/video for at begynde at transskribere øjeblikkeligt.
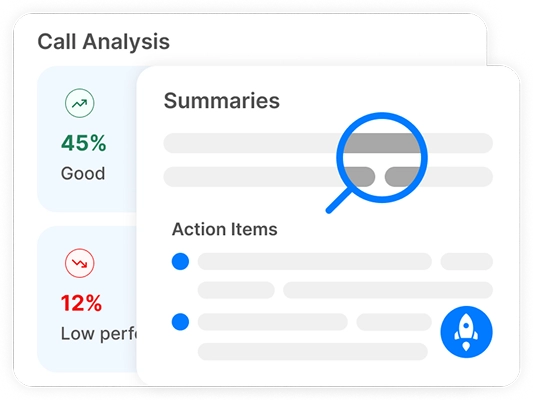
Transkriptor leverer fuldt redigerbare transskriptioner, AI-drevet analyse af opkaldssynspunkter, AI-resuméer og opdeling af vigtige emner.
Dine noter og lydtransskriptioner gemmes sikkert for nem adgang. Organiser dine mødenoter og søgbare afskrifter i mapper og arbejdsområder.
Udnyt vores AI-transskriptionsteknologi til at udtrække indsigt og vidensbaser fra flere filer, og stil spørgsmål eller tal med dine stemme-til-tekst-transskriptioner.
Opret din Transkriptor-konto og kom i gang med gratis transskriptionsadgang. Optag eller upload din lyd/video for at begynde at transskribere øjeblikkeligt.

Sikker, præcis medicinsk transskription designet til sundhedsfaglige. Omdan patientsamtaler til organiserede kliniske udskrifter øjeblikkeligt.

Omdan kundemøder til organiserede, søgbare forretningsudskrifter. Få øjeblikkelig transskriberet indsigt, nøgleresultater og AI-drevet transskriptionsanalyse for bedre kunderesultater.

Fokuser udelukkende på dine klienter, mens Transkriptor fungerer som din professionelle transskribent for terapisessioner. Få organiserede sessionsnoter, fremskridtssporing og sikker dokumentation automatisk.

Omdan kundemøder til søgbare udskrifter med juridisk transskriptionsteknologi. Få adgang til øjeblikkelige registreringer af diskussioner, samtidig med at fortroligheden opretholdes.

Hurtig og præcis medietransskription til udsendelser og indholdsproduktion. Konverter lyd til tekst øjeblikkeligt, med understøttelse af flere formater og sprog.
Konverter dine videoer til tilgængeligt indhold med hurtige transskriptionstjenester og automatisk undertekstning på over 100 sprog.
Stil spørgsmål, få sammendrag og udled indsigter fra dit transskriberede indhold øjeblikkeligt.
Administrer adgang, del filer og samarbejd problemfrit i dedikerede arbejdsområder.
Tilføj brugerdefinerede tags til alle dine filer. Find vigtige øjeblikke hurtigt og organiser indhold på din måde.
Analyser tonen og stemningen i transskriberede møder. Perfekt til kundeservice og teamkommunikation.
Spor fordeling af taletid og deltagelsesniveauer i samtaler.
Udnyt kraften i avanceret AI-transskription til hvert aspekt af dit arbejde. Prøv det gratis - Øg produktiviteten, forenkl arbejdsgangen!
Gør tale til nøjagtige transskriptioner på få sekunder. Professionel transskriptionsteknologi til lyd- og videoindhold, så du kan fokusere på indsigt, ikke på at tage noter.
Indfang hvert øjeblik med klarhed. Optag og transskriber nemt din skærm til selvstudier, præsentationer og meget mere – gennemgå og søg i transskriberet indhold, når du har brug for det.
Gå aldrig glip af en detalje igen. Automatiseret transskription, AI-møderesuméer og handlingspunkter fra dine møder, der omdanner samtaler til søgbare transskriptioner og samtidig øger produktiviteten.
Gør tekst levende med naturlige stemmer. Konverter skrevet tekst til realistiske talte ord, hvilket forbedrer tilgængeligheden og engagementet.
Ubesværet indhold, perfekt skrevet. Transskriber dine ideer til engagerende indhold af høj kvalitet, der er skræddersyet til dit publikum med minimalt input.
Dit teams transskriberede viden er kun et klik væk. Centraliseret AI-vidensbase, der organiserer, henter og strømliner transskriberede samtaler problemfrit.
Transkriptor prioriterer sikkerhed og privatliv på alle niveauer. Vores transskriptionsplatform i virksomhedsklasse overholder SOC 2-, GDPR-, ISO 27001- og SSL-standarderne for at sikre, at dine lyd- og videodata er fuldt beskyttet og sikkert transskriberet.




Transkriptors kraftfulde AI-notetagning genererer online transskriptioner på få sekunder, mens de fleste tjenester tager mere end 10 minutter.
Få op til 99% nøjagtighed, når du transskriberer dine lydfiler med Transkriptor. Transskribér eller oversæt lydindhold på 100+ sprog nemt.
Få valuta for pengene med Transkriptors fulde pakke af produktivitetsfunktioner og intuitive løsninger til en overkommelig pris.
Transskription er processen med at konvertere talt sprog fra lyd- eller videooptagelser til skreven tekst. Det bruges i vid udstrækning til møder, interviews, forelæsninger, podcasts og medieindhold. Transskription kan udføres manuelt af menneskelige transskribenter eller automatisk ved hjælp af AI-transskriptionssoftware.
Transskription fungerer ved at konvertere talte ord fra lyd eller video til skrevet tekst. Du uploader en fil til et værktøj som Transkriptor, der bruger AI til at registrere tale, identificere talere og generere en tidsstemplet udskrift. Du kan derefter gennemgå og redigere teksten og eksportere den i formater som TXT, DOCX eller undertekster (SRT/VTT).
Fordelene ved transskription omfatter forbedret tilgængelighed, bedre søgbarhed af indhold og øget produktivitet. Det omdanner talt indhold til skreven tekst, som er nem at læse og genanvende. Transskription understøtter også SEO ved at skabe indekserbart indhold. AI-transskriptionsværktøjer som Transkriptor automatiserer processen og sparer tid og ressourcer.
Transskriptionsnøjagtigheden påvirkes af flere faktorer, herunder lydkvalitet, baggrundsstøj, højttalerklarhed, overlappende dialog, accenter og antallet af talere. Dårligt optaget lyd eller stærke accenter kan reducere effektiviteten af AI-transskriptionsværktøjer. Mikrofoner af høj kvalitet, klar tale og minimale afbrydelser forbedrer resultaterne.
Ja, moderne transskriptionsværktøjer som Transkriptor kan håndtere flere talere ved hjælp af højttalerdiariseringsteknologi. Denne funktion identificerer og mærker hver taler i afskriften, hvilket gør det nemmere at følge samtaler i møder, interviews eller gruppediskussioner.
Den bedste transskriptionssoftware er Transkriptor. Den tilbyder meget nøjagtig AI-drevet transskription med op til 99% nøjagtighed. Transkriptor understøtter over 100 sprog, lader brugere uploade lyd- eller videofiler i forskellige formater og inkluderer funktioner som taleridentifikation, undertekstgenerering og en indbygget transskriptionseditor. Andre populære transskriptionsværktøjer inkluderer Otter.ai og Fireflies.ai, som også tilbyder AI-baserede transskriptionstjenester. Transkriptor foretrækkes dog for sin bredere sprogdækning, overkommelige priser og strømlinede redigeringsfunktioner, der understøtter både almindelige brugere og professionelle.
Du kan foretage synspunktsanalyse for samtaler ved hjælp af AI-drevne værktøjer som Transkriptor. Transkriptor's mødebot kan deltage direkte i dine onlinemøder eller analysere uploadede optagelser. Efter transskription evaluerer den automatisk den følelsesmæssige tone i samtalen – og klassificerer segmenter som positive, neutrale eller negative.
Den bedste lydkonvertering til tekst er Transkriptor. Den bruger avanceret AI til præcist at konvertere talt lyd til skreven tekst på bare få sekunder. Transkriptor understøtter populære lydformater som MP3, WAV og M4A og fungerer på over 100 sprog.
Det bedste gratis transskriptionsværktøj er Transkriptor. Det leverer meget nøjagtige og AI-drevne tale-til-tekst-tjenester, selv på den gratis plan. Med Transkriptors gratis transskriptionsmulighed kan du transskribere op til 30 minutters lyd om dagen.













