Analisi del Sentimento Basata su IA
L'analisi del sentimento basata su IA di Transkriptor trasforma le tue registrazioni audio in dettagliati insight emotivi. Rileva con precisione il tempo di parola, il tono, l'emozione e l'intento nelle chiamate con i clienti, nelle riunioni online e nelle interviste, convertendo automaticamente il parlato in testo ed estraendo dati sul sentimento vocale con trascrizione avanzata e analisi del sentimento alimentate dall'IA.
Trascrivi e analizza il sentimento in oltre 100 lingue
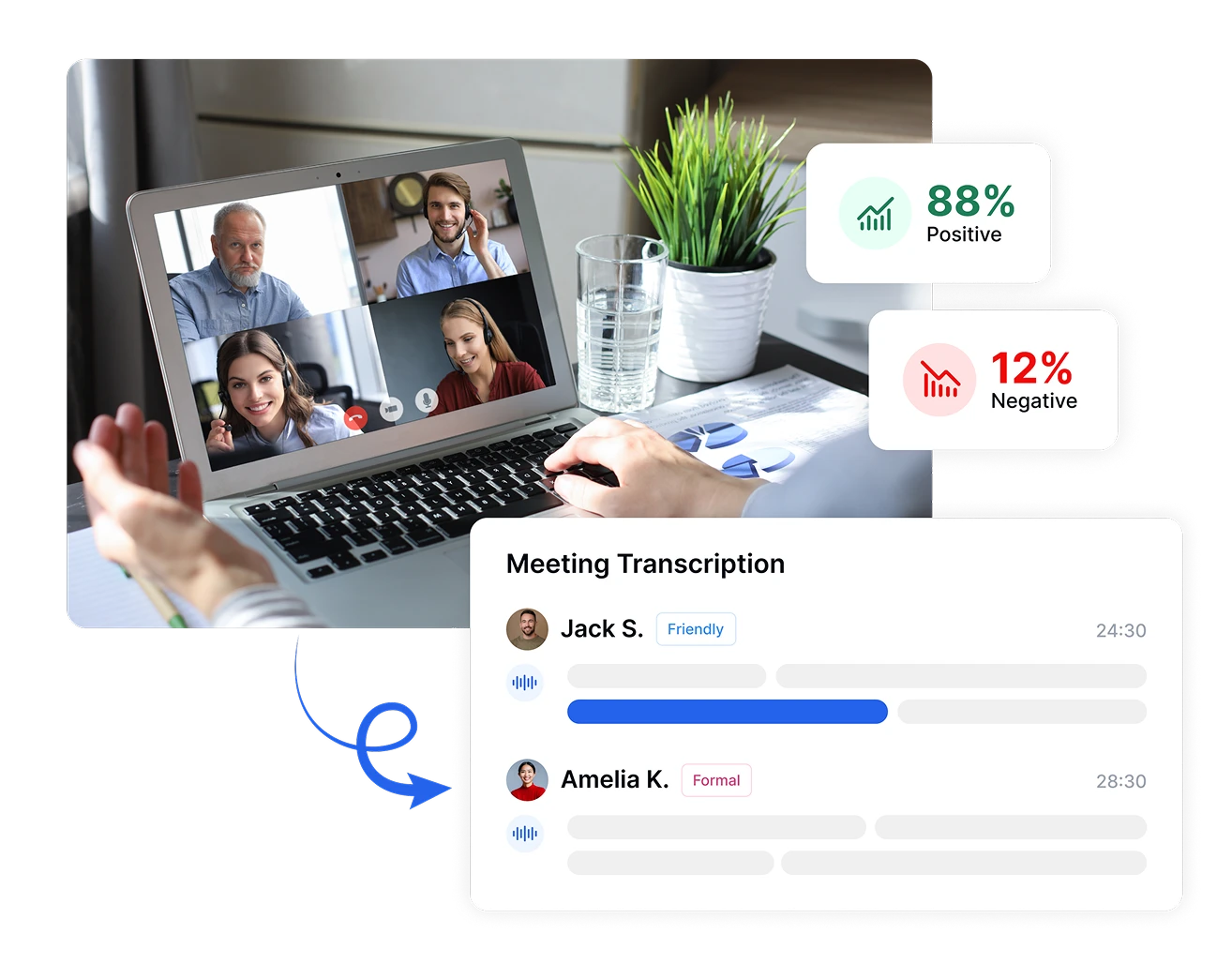
Prendi Decisioni Basate sui Dati con l'Analisi del Sentimento
Converti risposte emotive soggettive in metriche oggettive con Transkriptor. Misura l'intensità del sentimento, traccia i cambiamenti emotivi durante le conversazioni e confronta il sentimento in diversi periodi di tempo o segmenti di clientela. Queste misurazioni precise trasformano sentimenti astratti in dati concreti, consentendo decisioni basate su evidenze che migliorano la soddisfazione del cliente e i risultati aziendali.

Analizza il Sentimento Vocale in Oltre 100 Lingue
Abbatti le barriere linguistiche con le capacità di analisi del sentimento multilingue di Transkriptor. Rileva sfumature emotive in oltre 100 lingue, permettendo ai team globali di comprendere il sentimento dei clienti indipendentemente dalla regione o dalla lingua. Questa copertura linguistica completa garantisce un monitoraggio coerente del sentimento nei mercati internazionali con tassi di accuratezza elevati fino al 99%.
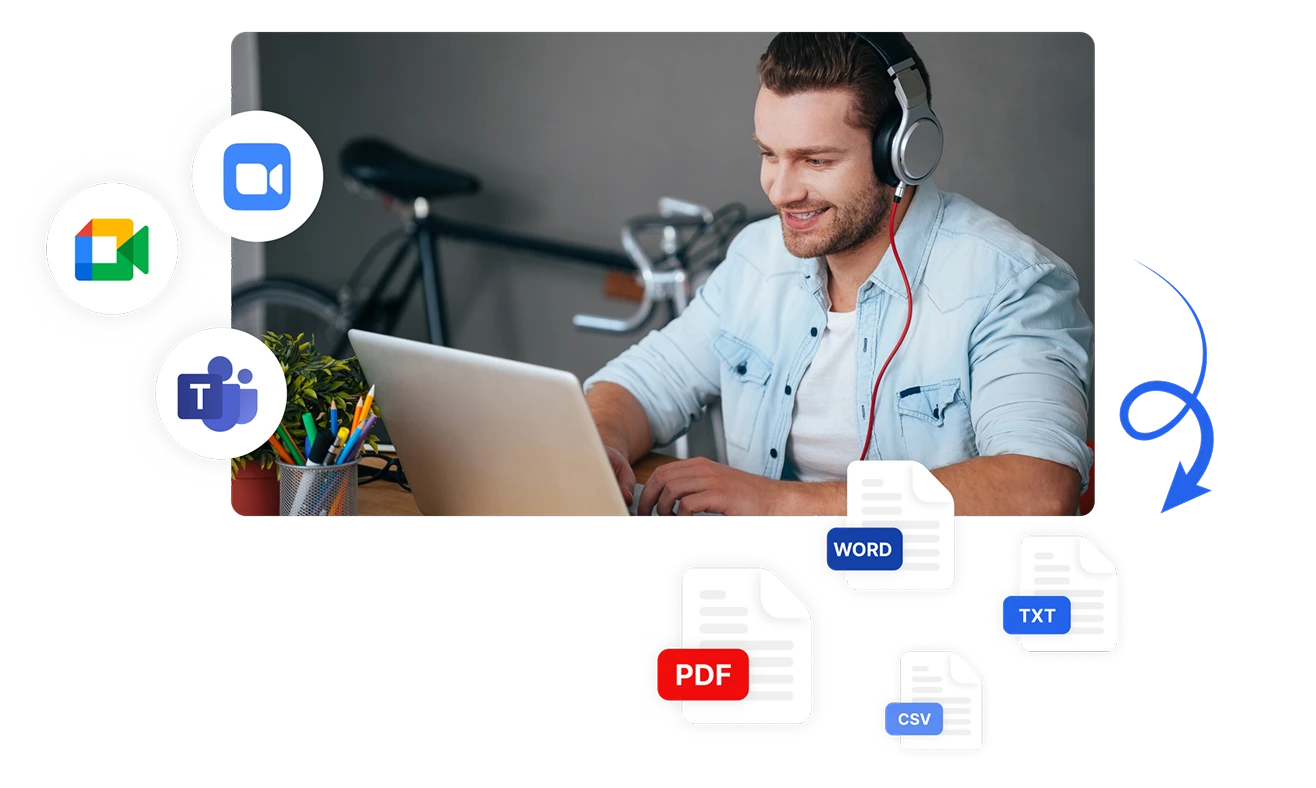
Cattura e Analizza il Sentimento su Tutti i Canali
Analizza il sentimento da molteplici canali di comunicazione con le versatili opzioni di input di Transkriptor. Trascrivi e analizza automaticamente il sentimento da file audio caricati, riunioni registrate direttamente o piattaforme integrate come Zoom, Microsoft Teams e Google Meet. Esporta i risultati dell'analisi del sentimento in formati PDF, Word, TXT, CSV o condividili istantaneamente con i membri del team.

Analizza il Sentimento Vocale in Soli 4 Semplici Passaggi
- 1FASE 1
Carica il Tuo Audio o Connetti la Tua Riunione
- 2FASE 2
Transkriptor Trascrive e Analizza
- 3FASE 3
Esamina l'Analisi del Sentimento
- 4FASE 4
Esporta o Condividi gli Approfondimenti sul Sentimento
Chi Trae Maggior Vantaggio dall'Analisi del Sentimento di Transkriptor

Team di Successo Cliente
Monitora le tendenze di soddisfazione dei clienti in tutte le interazioni di servizio con l'analisi del sentiment basata sull'IA.

Professionisti delle Vendite
Ottimizza le conversazioni di vendita utilizzando l'analisi del sentiment basata sull'IA delle chiamate con i potenziali clienti.

Professionisti Legali
Analizza i modelli di sentiment nelle deposizioni registrate, nelle interviste con i clienti e nelle dichiarazioni dei testimoni.

Professionisti delle Risorse Umane
Migliora la valutazione dei colloqui e le sessioni di feedback dei dipendenti con un'analisi oggettiva del sentiment.
Soluzione All-in-One per l'Analisi del Sentiment
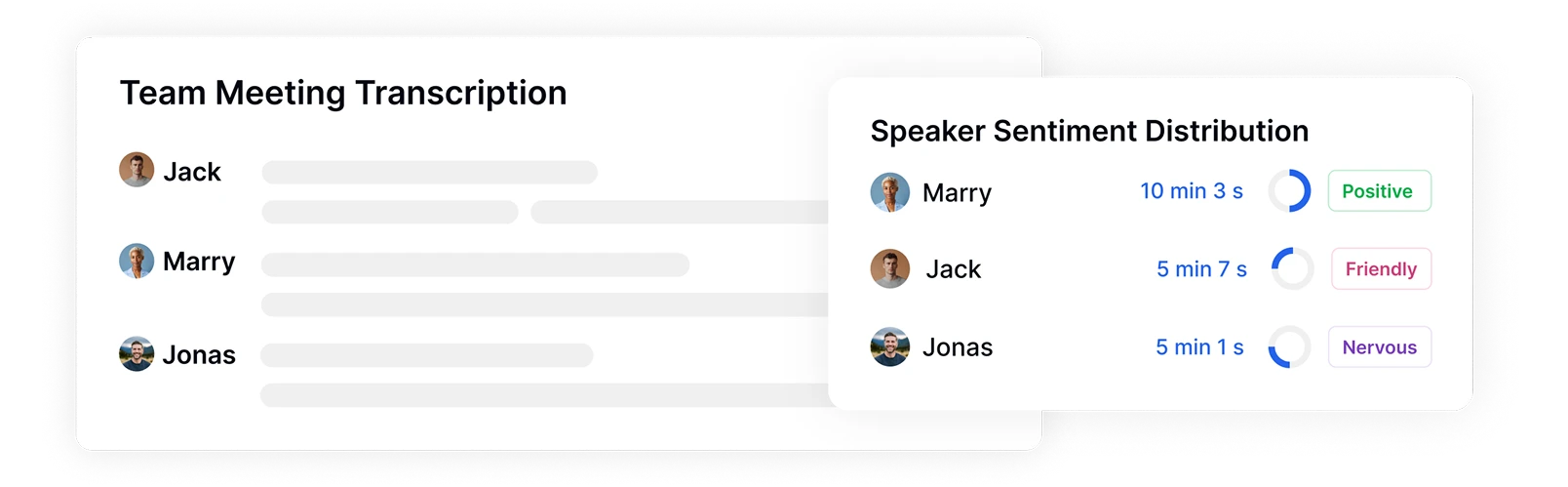
Identifica gli Interlocutori e Monitora la Distribuzione del Sentiment
Transkriptor identifica e etichetta automaticamente i diversi interlocutori nelle tue registrazioni, misurando il loro tempo di conversazione e i modelli emotivi. Vedi esattamente chi ha parlato, quando, per quanto tempo e con quale sentiment, fornendo un contesto fondamentale per analizzare le dinamiche emotive tra i partecipanti durante riunioni, interviste o interazioni con i clienti.
Identifica gli Interlocutori e Monitora la Distribuzione del Sentiment
Transkriptor identifica e etichetta automaticamente i diversi interlocutori nelle tue registrazioni, misurando il loro tempo di conversazione e i modelli emotivi. Vedi esattamente chi ha parlato, quando, per quanto tempo e con quale sentiment, fornendo un contesto fondamentale per analizzare le dinamiche emotive tra i partecipanti durante riunioni, interviste o interazioni con i clienti.

Genera Riassunti del Sentiment Basati su IA
Trasforma lunghe conversazioni in riassunti concisi del sentiment con la tecnologia IA di Transkriptor. Questi riassunti identificano i principali cambiamenti di sentiment e quantificano il tono emotivo generale, fornendo una rapida panoramica del percorso emotivo durante qualsiasi conversazione registrata.

Crea Basi di Conoscenza con l'Analisi del Sentiment
Organizza informazioni emotive essenziali creando basi di conoscenza personalizzate utilizzando trascrizioni analizzate per sentiment. Archivia, categorizza e cerca dati sul sentiment per stabilire parametri emotivi di riferimento, identificare modelli ricorrenti e costruire un archivio completo di intelligenza emotiva.
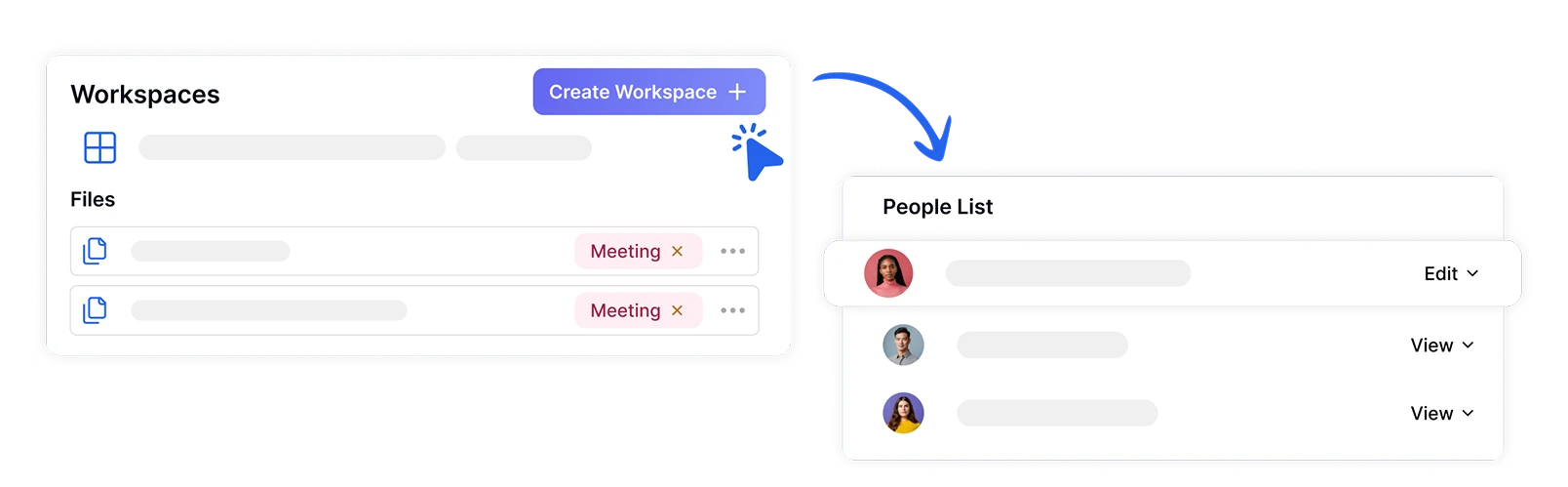
Organizza e Condividi File in Spazi di Lavoro Sicuri
Gestisci progetti di analisi del sentiment del team in modo sicuro creando spazi di lavoro dedicati con ruoli e autorizzazioni assegnati. Assicura che i dati emotivi sensibili siano accessibili solo ai membri del team autorizzati, facilitando la collaborazione sulle informazioni di sentiment tra i vari reparti.
Sicurezza di Livello Enterprise
La sicurezza e la privacy dei clienti sono la nostra priorità in ogni fase. Rispettiamo gli standard SOC 2 e GDPR, garantendo che le tue informazioni siano protette in ogni momento.





Storie di Successo dei Clienti
Riduzione dell'Abbandono Utilizzando i Dati di Sentiment
Transkriptor ha rivoluzionato il modo in cui il nostro team di 14 persone gestisce le relazioni con i clienti. Analizzando il sentiment nelle chiamate di onboarding e di verifica, identifichiamo gli account a rischio prima che le metriche tradizionali mostrino problemi. Il supporto multilingue gestisce la nostra clientela globale, e i modelli personalizzati aiutano a standardizzare il nostro approccio in tutto il team.

Kira Johnson
Responsabile del Successo Clienti
Riduzione del 30% nelle Assunzioni Sbagliate
Transkriptor ha trasformato il nostro processo di colloquio in 7 mesi di utilizzo. L'analisi del sentiment aiuta a identificare incongruenze emotive nelle risposte dei candidati che potremmo non notare. Monitorare il sentiment su diversi argomenti del colloquio fornisce approfondimenti più profondi sulla compatibilità culturale, migliorando significativamente il tasso di successo delle nostre assunzioni.

Amira Khan
Direttrice HR
Domande Frequenti
Il miglior strumento di analisi del sentiment è Transkriptor. Alimentato da intelligenza artificiale avanzata, Transkriptor trascrive automaticamente i contenuti vocali e analizza il tono emotivo con elevata precisione. Classifica le conversazioni come positive, negative o neutre e supporta oltre 100 lingue.
L'analisi del sentiment funziona utilizzando l'intelligenza artificiale e l'elaborazione del linguaggio naturale (NLP) per valutare il tono emotivo di testi o discorsi. Identifica indicatori chiave di emozione come la scelta delle parole, la struttura della frase e gli indizi contestuali per classificare i contenuti come positivi, negativi o neutri. I sistemi più avanzati possono anche rilevare l'intento, i cambiamenti emotivi e il sentiment specifico del parlante nel tempo.
Transkriptor ti permette di creare spazi di lavoro personalizzati con autorizzazioni basate sui ruoli per organizzare i progetti di analisi del sentiment. Puoi anche costruire basi di conoscenza utilizzando contenuti classificati per sentiment, rendendo facile archiviare, categorizzare e cercare dati emotivi mantenendo sicurezza e accessibilità.
L'analisi del sentiment aiuta i team di assistenza clienti a identificare i fattori emotivi nelle conversazioni, misurare l'efficacia delle tecniche di de-escalation e monitorare il sentiment del cliente durante tutto il processo di supporto. Questi insight permettono ai team di perfezionare il loro approccio, portando a una maggiore soddisfazione del cliente e a una riduzione delle chiamate ripetute.
Sì, Transkriptor supporta l'analisi del sentiment in oltre 100 lingue con elevata precisione. Il sistema è progettato per riconoscere le sfumature culturali e linguistiche specifiche di ogni lingua, garantendo un rilevamento costante del sentiment indipendentemente dalla lingua madre del parlante.
Accedi a Transkriptor Ovunque
Registra dal vivo o carica file audio e video da trascrivere. Modifica le tue trascrizioni con facilità e utilizza l'assistente AI per chattare o riassumere le trascrizioni.