
Alternatywą rozpoznawania mowy jest transkrypcja ręczna. Transkrypcja ręczna to proces konwersji języka mówionego na tekst pisany poprzez odsłuchanie nagrania audio lub wideo i wpisanie treści.
Istnieje wiele programów do rozpoznawania mowy, ale kilka nazw wyróżnia się na rynku, jeśli chodzi o oprogramowanie do rozpoznawania mowy; Dragon NaturallySpeaking, Google Speech-to-Text i Transkriptor.
Koncepcja stojąca za pytaniem "co to jest rozpoznawanie mowy?" odnosi się do zdolności systemu lub oprogramowania do rozumienia i przekształcania komunikacji ustnej w pisemną formę tekstową. Funkcjonuje jako podstawowa podstawa szerokiej gamy nowoczesnych aplikacji, począwszy od wirtualnych asystentów aktywowanych głosem, takich jak Siri lub Alexa , po narzędzia do dyktowania i manipulację gadżetami bez użycia rąk.
Rozwój ten przyczyni się do większej integracji interakcji głosowych z codziennym życiem jednostki.

Co to jest rozpoznawanie mowy?
Rozpoznawanie mowy, znane jako ASR, rozpoznawanie głosu lub zamiana mowy na tekst, to proces technologiczny. Pozwala komputerom analizować i transkrybować ludzką mowę na tekst.
Jak działa funkcja rozpoznawania mowy?
Technologia rozpoznawania mowy działa podobnie do sposobu, w jaki dana osoba prowadzi rozmowę ze znajomym. Uszy wykrywają głos, a mózg przetwarza i rozumie. Technologia tak, ale wymaga zaawansowanego oprogramowania, a także skomplikowanych algorytmów. To działa w czterech krokach.
Mikrofon rejestruje dźwięki głosu i przekształca je w małe sygnały cyfrowe, gdy użytkownicy mówią do urządzenia. Oprogramowanie przetwarza sygnały, aby wykluczyć inne głosy i wzmocnić mowę pierwotną. System dzieli mowę na małe jednostki zwane fonemami.
Różne fonemy dają swoje własne, unikalne reprezentacje matematyczne przez system. Jest w stanie rozróżniać poszczególne słowa i przewidywać to, co mówca próbuje przekazać.
System wykorzystuje model językowy do przewidywania właściwych słów. Model przewiduje i koryguje sekwencje słów na podstawie kontekstu mowy.
Tekstowa reprezentacja mowy jest tworzona przez system. Proces ten zajmuje niewiele czasu. Jednak poprawność transkrypcji zależy od różnych okoliczności, w tym jakości dźwięku.
Jakie znaczenie ma rozpoznawanie mowy?
Znaczenie rozpoznawania mowy jest wymienione poniżej.
- Wydajność: Pozwala na obsługę bez użycia rąk. Sprawia, że wielozadaniowość jest łatwiejsza i bardziej wydajna.
- Dostępność: Zapewnia niezbędne wsparcie dla osób niepełnosprawnych.
- Bezpieczeństwo: Zmniejsza rozproszenie uwagi, umożliwiając rozmowy telefoniczne w trybie głośnomówiącym.
- Tłumaczenie w czasie rzeczywistym: Ułatwia tłumaczenie języków w czasie rzeczywistym. Przełamuje bariery komunikacyjne.
- Automatyzacja: Zasila wirtualnych asystentów, takich jak Siri, Alexai Google Assistant, usprawniając wiele codziennych zadań.
- Personalizacja: Pozwala urządzeniom i aplikacjom zrozumieć preferencje i polecenia użytkownika.
Jakie są zastosowania rozpoznawania mowy?
Poniżej wymieniono 7 zastosowań rozpoznawania mowy.
- Wirtualni asystenci. Obejmuje zasilanie asystentów aktywowanych głosem, takich jak Siri, Alexai Google Assistant.
- Usługi transkrypcji. Polega na konwersji treści mówionych na tekst pisany do dokumentacji, napisów lub innych celów.
- Opieki zdrowotnej. Umożliwia lekarzom i pielęgniarkom dyktowanie notatek i dokumentacji pacjentów bez użycia rąk.
- Motoryzacyjny. Obejmuje on włączanie sterowania głosowego w pojazdach, od odtwarzania muzyki po nawigację.
- Obsługa klienta. Obejmuje zasilanie aktywowanych głosem IVR w centrach telefonicznych.
- Educatio.: Służy do ułatwiania aplikacji do nauki języków, wspomagania wymowy i ćwiczeń ze zrozumieniem.
- Gier. Obejmuje to udostępnianie funkcji poleceń głosowych w grach wideo, aby zapewnić bardziej wciągające wrażenia.
Kto korzysta z funkcji rozpoznawania mowy?
Zwykli konsumenci, profesjonaliści, studenci, programiści i twórcy treści korzystają z oprogramowania do rozpoznawania głosu. Rozpoznawanie głosu wysyła wiadomości tekstowe, wykonuje połączenia telefoniczne i zarządza urządzeniami za pomocą poleceń głosowych. Prawnicy, lekarze i dziennikarze należą do profesjonalistów, którzy wykorzystują rozpoznawanie mowy. Korzystając z oprogramowania do rozpoznawania mowy, dyktują informacje specyficzne dla domeny.
Jakie są zalety korzystania z rozpoznawania mowy?
Zaletą korzystania z rozpoznawania mowy jest przede wszystkim jego dostępność i wydajność. Sprawia, że interakcja człowiek-maszyna jest bardziej dostępna i wydajna. Zmniejsza ludzką potrzebę, która jest również czasochłonna i podatna na błędy.
Jest to korzystne dla dostępności. Osoby niedosłyszące używają poleceń głosowych, aby łatwo się komunikować. Opieka zdrowotna odnotowała znaczny wzrost wydajności, a profesjonaliści wykorzystują rozpoznawanie mowy do szybkiego nagrywania. Polecenia głosowe w ustawieniach jazdy pomagają zachować bezpieczeństwo i pozwalają dłoniom i oczom skupić się na najważniejszych obowiązkach.
Jaka jest wada korzystania z rozpoznawania mowy?
Wadą korzystania z rozpoznawania mowy jest możliwość niedokładności i poleganie na określonych warunkach. Hałas otoczenia lub akcenty dezorientują algorytm. Skutkuje to błędnymi interpretacjami lub błędami w transkrypcji.
Te nieścisłości są problematyczne. Mają one kluczowe znaczenie w sytuacjach wrażliwych, takich jak transkrypcja medyczna lub dokumentacja prawna. Niektóre systemy potrzebują czasu, aby nauczyć się, jak dana osoba mówi, aby działać poprawnie. Systemy rozpoznawania głosu prawdopodobnie mają trudności z tłumaczeniem wielu mówców w tym samym czasie. Kolejną wadą jest prywatność. Urządzenia aktywowane głosem mogą przypadkowo nagrywać prywatne rozmowy.
Jakie są różne rodzaje rozpoznawania mowy?
Poniżej wymieniono 3 różne typy rozpoznawania mowy.
- Automatyczne rozpoznawanie mowy (ASR)
- Rozpoznawanie zależne od osoby mówiącej (SDR)
- Rozpoznawanie niezależne od osoby mówiącej (SIR)
Automatyczne rozpoznawanie mowy (ASR) jest jednym z najpopularniejszych typów rozpoznawania mowy . Systemy ASR konwertują język mówiony na format tekstowy. Wiele aplikacji z nich korzysta, takich jak Siri i Alexa. ASR koncentruje się na rozumieniu i transkrypcji mowy niezależnie od mówcy, dzięki czemu ma szerokie zastosowanie.
Rozpoznawanie zależne od osoby mówiącej rozpoznaje głos pojedynczego użytkownika. Potrzebuje czasu, aby nauczyć się i dostosować do swoich szczególnych wzorców głosowych i akcentów. Systemy zależne od mówcy są bardzo dokładne ze względu na szkolenie. Mają jednak trudności z rozpoznawaniem nowych głosów.
Rozpoznawanie niezależne od osoby mówiącej interpretuje i transkrybuje mowę dowolnego mówcy. Nie dba o akcent, tempo mówienia ani wysokość głosu. Systemy te są przydatne w aplikacjach z wieloma użytkownikami.
Jakie akcenty i języki rozpoznają systemy rozpoznawania mowy?
Akcenty i języki, które mogą rozpoznawać systemy rozpoznawania mowy, to angielski, hiszpański i mandaryński, a także mniej popularne. Systemy te często zawierają niestandardowe modele do rozróżniania dialektów i akcentów. Uznaje różnorodność w obrębie języków. Transkriptorna przykład jako oprogramowanie do dyktowania obsługuje ponad 100 języków.
Czy oprogramowanie do rozpoznawania mowy jest dokładne?
Tak, oprogramowanie do rozpoznawania mowy jest dokładne powyżej 95%. Jednak jego dokładność różni się w zależności od wielu rzeczy. Szum tła i jakość dźwięku to dwa przykłady.
Jak dokładne mogą być wyniki rozpoznawania mowy?
Wyniki rozpoznawania mowy mogą osiągnąć poziom dokładności do 99% w optymalnych warunkach. Najwyższy poziom dokładności rozpoznawania mowy wymaga kontrolowanych warunków, takich jak jakość dźwięku i szumy tła. Wiodące systemy rozpoznawania mowy odnotowały wskaźniki dokładności przekraczające 99%.
Jak działa transkrypcja tekstu z rozpoznawaniem mowy?
Transkrypcja tekstu współpracuje z rozpoznawaniem mowy, analizując i przetwarzając sygnały audio. Proces transkrypcji tekstu rozpoczyna się od mikrofonu, który nagrywa mowę i konwertuje ją na dane cyfrowe. Następnie algorytm dzieli dźwięk cyfrowy na małe kawałki i analizuje każdy z nich, aby zidentyfikować jego odrębne tony.
Zaawansowane algorytmy komputerowe wspomagają system w dopasowaniu tych dźwięków do rozpoznanych wzorców mowy. Oprogramowanie porównuje te wzorce z ogromną bazą danych języków, aby znaleźć słowa wyartykułowane przez użytkowników. Następnie łączy słowa, tworząc logiczny tekst.
W jaki sposób dane audio są przetwarzane za pomocą funkcji rozpoznawania mowy?
Rozpoznawanie mowy przetwarza dane dźwiękowe, dzieląc fale dźwiękowe, wyodrębniając cechy i mapując je na części językowe. System zbiera i przetwarza ciągłe fale dźwiękowe, gdy użytkownicy mówią do urządzenia. Oprogramowanie przechodzi do etapu wyodrębniania cech.
Oprogramowanie wyodrębnia określone cechy dźwięku. Koncentruje się na fonemach, które są kluczowe dla identyfikacji jednego fonemu od drugiego. Proces ten polega na ocenie składowych częstotliwości.
Następnie system zaczyna korzystać z wytrenowanych modeli. Oprogramowanie łączy wyodrębnione funkcje ze znanymi fonemami, korzystając z obszernych baz danych i modeli uczenia maszynowego.
System pobiera fonemy i łączy je w słowa i frazy. System łączy umiejętności technologiczne i rozumienie języka, aby przekształcać dźwięki w zrozumiały tekst lub polecenia.
Jakie jest najlepsze oprogramowanie do rozpoznawania mowy?
Poniżej wymieniono 3 najlepsze oprogramowanie do rozpoznawania mowy.
- Transkriptor
- Dragon NaturallySpeaking
- Zamiana mowy na tekst w Google
Jednak wybór najlepszego oprogramowania do rozpoznawania mowy zależy od osobistych preferencji.
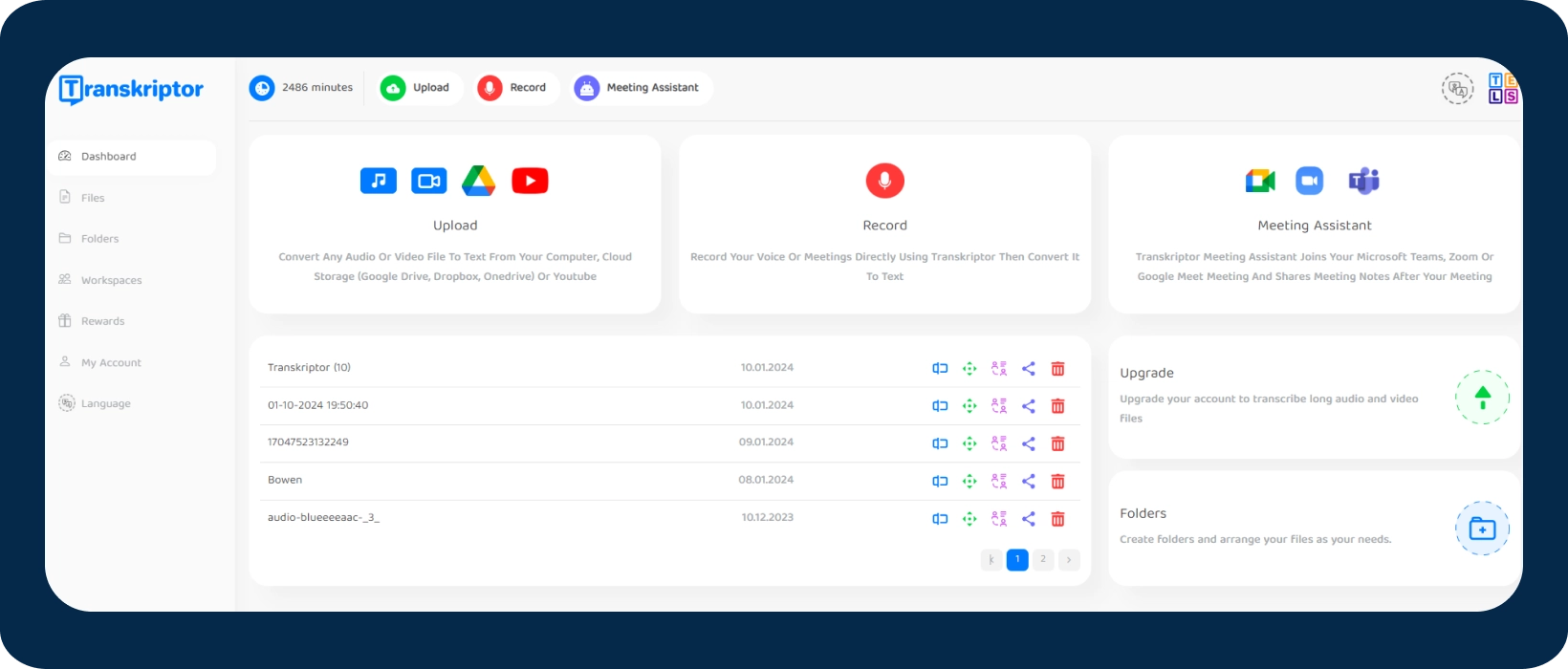
Transkriptor to oprogramowanie do transkrypcji online, które wykorzystuje sztuczną inteligencję do szybkiej i dokładnej transkrypcji. Użytkownicy mogą tłumaczyć swoje transkrypcje jednym kliknięciem bezpośrednio z pulpitu nawigacyjnego Transkriptor. Transkriptor technologia jest dostępna w postaci aplikacji na smartfony, rozszerzenia Google Chrome i wirtualnego bota do spotkań. Jest kompatybilny z popularnymi platformami, takimi jak Zoom, Microsoft Teamsi Google Meet co czyni go jednym z najlepszych programów do rozpoznawania mowy.
Dragon NaturallySpeaking umożliwia użytkownikom przekształcanie mowy mówionej w tekst pisany. Oferuje dostępność, a także dostosowanie do konkretnych języków językowych. Użytkownikom podoba się możliwość dostosowania oprogramowania do różnych słowników.

Zamiana mowy na tekst Google jest szeroko stosowana ze względu na skalowalność, opcje integracji i możliwość obsługi wielu języków. Osoby fizyczne używają go w różnych zastosowaniach, od usług transkrypcji po systemy poleceń głosowych.
Czy rozpoznawanie mowy i dyktowanie to samo?
Nie, rozpoznawanie mowy i dyktowanie to nie to samo. Ich główne cele są różne, mimo że zarówno rozpoznawanie głosu, jak i dyktowanie dokonują konwersji języka mówionego na tekst. Rozpoznawanie mowy to szerszy termin obejmujący zdolność technologii do rozpoznawania i analizowania wypowiadanych słów. Konwertuje je do formatu zrozumiałego dla komputerów.
Dyktowanie odnosi się do procesu mówienia na głos w celu nagrania. Oprogramowanie do dyktowania wykorzystuje rozpoznawanie mowy do konwersji słów mówionych na tekst pisany.
Jaka jest różnica między rozpoznawaniem mowy a dyktowaniem?
Różnica między rozpoznawaniem mowy a dyktowaniem jest związana z ich głównym celem, interakcjami i zakresem. Jego głównym celem jest rozpoznawanie i rozumienie wypowiadanych słów. Dyktando ma bardziej określony cel. Koncentruje się na bezpośredniej transkrypcji mowy mówionej na formę pisemną.
Rozpoznawanie mowy obejmuje szeroki zakres zastosowań pod względem zakresu. Pomaga asystentom głosowym odpowiadać na pytania użytkowników. Dyktowanie ma węższy zakres.
Zapewnia bardziej dynamiczne interaktywne doświadczenie, często pozwalając na dwukierunkowe dialogi. Na przykład wirtualni asystenci, tacy jak Siri lub Alexa , nie tylko rozumieją prośby użytkowników, ale także przekazują informacje zwrotne lub odpowiedzi. Dyktowanie działa w bardziej podstawowy sposób. Zazwyczaj jest to procedura jednokierunkowa, w której użytkownik mówi, a system dokonuje transkrypcji, a program nie angażuje się w dyskusję na temat odpowiedzi.